
基本概念
Job: 每个 action 都会触发 sparkcontext 提交一个 Job, 比如 count, collect, reduce 这些函数。
Stage: 一个 Job 提交后会 build 出一个有向无环图,展示每个 partition 在不同 RDD 的传递关系。具体如何划分 Stage 呢?比如 map, filter 这些窄依赖(one to one)的,可以 pipeline 流式执行,将这些划分成同一个 Stage, 直到遇到 shuffle 宽依赖(one to more)。
Task: 由于 Spark 是大规模并发执行的框架,底层最小执行单元就是 Task. 对应 Stage 中,会并发对不同 partition 做流式操作,那么一个 partition 就会提交一个 Task.
Cache tracking: 通俗讲,Spark 中所有 partition 都是可以通过 lineage 回溯重新计算,如果有节点失联,或是任务依赖的 partition missing 不见了,recomputing 即可。但是大规模迭代计算时开销还是蛮大的,为了避免这种情况,会在计算的中间阶段或是已知会重用的 RDD 做持久化,一般都会持久化每个 Stage 最后的 shuffle RDD
Cleanup: 防止内存泄漏,所有操作都会在 ClosureCleaner 里进行注册,等任务结束后回收资源。
Preferred locations: the DAGScheduler also computes where to run each task in a stage based on the preferred locations of its underlying RDDs, or the location of cached or shuffle data. 可以理解为就近原则
RDD 在 action 触发 submitJob 后,由 DAGScheduler 负责调度。主要由以下几点
1. 把 Job 划分成多个 stage(阶段),每个 stage 可能独立,也可能有依赖
2. 每个 stage 内部包含一个 taskset, 即任务集,每个 task 都是独立互不依赖,可以并行执行
3. DAGScheduler 提交 Job,将任务下发执行
但是具体如何操作呢?我们通过官方 GroupByTest 来看看
例子GroupByTest

打开 spark-shell 单步调式,一共生成了三个RDD,触发两次 action 操作,即提交了两个任务。首先 sc.parallelize 生成了一个 ParallelCollectionRDD[Int], 然后由 flatMap 生成了一个 MapPartitionsRDD[(Int, Array[Byte])], 触发一次 count 操作。由 groupByKey 生成 ShuffledRDD[(Int,Iterable[Array[Byte]])],再触发一次 count 操作。
一定要记住: RDD 只读,每次都是新建一个 RDD, 这叫做 transformation 阶段, 没有任何数据拷贝开销,内部通过 Iterator 实现流式计算,这是惰性的,直到 action 阶段才触发任务执行。
scala> var numMappers = 2
numMappers: Int = 2
scala> var numKVPairs = 1000
numKVPairs: Int = 1000
scala> var valSize = 1000
valSize: Int = 1000
scala> var numReducers = numMappers
numReducers: Int = 2
scala> import java.util.Random
scala> val pdd=sc.parallelize(0 until numMappers, numMappers)
pdd:org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at:29
scala> val pair1 = pdd.flatMap { p =>
val ranGen = new Random
var arr1 = new Array[(Int, Array[Byte])](numKVPairs)
for (i <- 0 until numKVPairs) {
val byteArr = new Array[Byte](valSize)
ranGen.nextBytes(byteArr)
arr1(i) = (ranGen.nextInt(Int.MaxValue), byteArr)
}
arr1
}.cache()
pair1: org.apache.spark.rdd.RDD[(Int, Array[Byte])] = MapPartitionsRDD[1] at flatMap at:40
scala> pair1.count
res6: Long = 2000
scala> val gbrdd = pair1.groupByKey(numReducers)
gbrdd: org.apache.spark.rdd.RDD[(Int, Iterable[Array[Byte]])] = ShuffledRDD[2] at groupByKey at:44
scala> gbrdd.count
res4: Long = 2000
源码跟踪
1. parallelize 生成 ParallelCollectionRDD, 拥有两个 ParallelCollectionPartition, 内部分别持有数据 Seq[Int](0) 和 Seq[Int](1), 对外通过这个 Seq.iterator 访问

scala> pdd.collect
res11: Array[Int] = Array(0, 1)
scala> pdd.getNumPartitions
res12: Int = 2
通过 getNumPartitions, collect 查看, 确实只有两个分区,并且元素是0和1
2. flatMap 作用后生成 MapPartitionsRDD, 由于 map 操作是一一对应的窄依赖 transformation, 所以很容易得出新 RDD同样持有两个分区,每个分区持有 1000 个元素,每个元素都是二元组 (Int, Array[Byte]),同样可以用 getNumPartitions, collect 进行验证

f 是闭包,代指操作的语句块,withScope 是为了增加可调试信息,调用真正函数的函数。sc.clean 是为了注册 f,方便任务结束后清理,可以看到 flatMap 只是简单的新建一个 RDD.

由于新RDD不依赖上一个RDD分区函数,所以preservesPartitioning 使用默认的false. getPartitions 函数使用依赖的父 RDD 分区。而 compute 就是最终当 action 被触发时所执行的函数,可以看到是针对 iterator 的操作,所以是流式惰性。
3. cache 操作触发持久化,一般优先持久在内存中,这块暂不分析。
4. pair1.count 第一次触发 action 操作,导致 sc 提交任务

这个操作暂不深入,就是迭代所有 partitions, 得到每个分区的元素个数,最后再做 sum 累加
5. groupByKey 不是 MapPartitionsRDD 的方法,而是先通过rddToPairRDDFunctions隐式转换成 PairRDDFunctions

numPartitions 表示分区数,这里是 2, 同时采用hash分区策略,最终结果将(k,v)按k做hash分成两个分区,v 是相同key的集合,就里面是 CompactBuffer。具体如何聚合不做展开。

6. 最后再执行 count, 我们具体看下:

这个会提交任务,返回值是 Array[U], 然后再做 sum

这个 f 闭包很简单,计算给定 iterator 的元素个数,简单暴力易理解。性能啥样不知道,估计不慢。


runJob 接收四个参数,rdd是当前作用的 RDD, func 是对每个分区做计算的闭包, partitions 表示要计算的分区列表,resultHandler 是对每个分区计算结果的处理函数,在这里就是将 result 扔到 results 数组里。

Spark 代码非常易懂,本着大系作小做的思想,不会有特别复杂的函数。在这里将任务传递给 DAGScheduler,至此重量级的角色闪量登场。
有向无环图
大家都知道一个任务想要执行的更快,只能并行处理。Spark 将一个任务,划分成多个 Stage, 互相依赖的串行执行,不互相依赖的可以并行,并且在单个 Stage 内部,Spark 将任务以分区为计算并行的最小单元。

如上图,先说结论。Spark 将任务以 shuffle 依赖(宽依赖)为边界打散,划分多个 Stage. 最后的结果阶段叫做 ResultStage, 其它阶段叫 ShuffleMapStage, 从后往前推导,依将计算。还是以上个例子跟踪源码
1. SparkContext 调用 DAGScheduler 提交任务

代码很容易理解,提交任务后,返回一个 JobWaiter, 然后阻塞在这里,不断轮询任务结果。
2. 省去了部分代码,eventLoop提交 JobSubmitted,这是一个 case class, Scala 中信息传递常见方式。

3. DAGScheduler 开始处理接收到的 handleJobSubmitted 消息,同样省去部分代码。由于任务都是从后向前推导,所以在这里提交一个 ResultStage,即最后代码主逻辑进入 submitStage(finalStage)
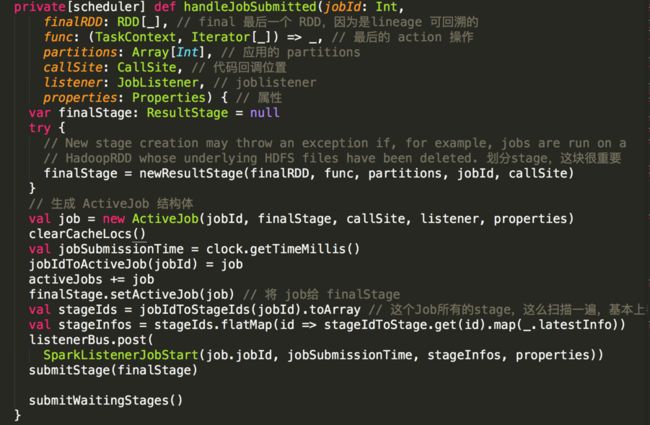
4. 检查是否有依赖的父 Stage, 如果没有直接执行,如果有那么递归提交父 Stage,因为我们这是第一次提交,所以代码逻辑先进入 getMissingParentStage 找到并生成父 Stage,并将该 Stage 加入到等待执行队列

5. 整个 DAGScheduler 划分 Stage 的精髓就在这里,代码逻辑超乎意料的简单易懂。

a) 将该 Stage 的RDD压栈
b) 循环遍历RDD栈,取出依赖 dependencies,遍历就结分区依赖,如果是窄依赖 narrowDep, 那么将该分区 RDD 压栈,继续遍历。如果是 shuffle (宽依赖),那么就以此为边界,将该 RDD 生成新的 Stage,放入 missing stage 队列。
c) 全部遍历后,返回依赖的 missing stage 列表
7. 经过上一步递归操作,DAGScheduler 完成 Stage 划分并将任务提交,此时在 waitingStage 队列的 Stage 会在其它任务完成后被 handleTaskCompletion 回调 submitWaitingStages 再次提交。
8. submitMissingTasks 提交 任务,将一个 Stage 内以分区为最小单元生成 numPartitions 个任务,一并提交。
至此 DAGScheduler 阶段分析完毕,其它 action 函数也都大同小异,下一步分析 TaskScheduler, 展示任务调度动态细节。
如有错误,请大家及时指证,谢谢~~~