内存分段分页机制理解
现代操作系统,计算机内存是按照先分段再分页的方式管理的。
注意:
以下描述都是基于32位计算机进行描述的。
1. 分段
1) 程序直接使用物理地址的问题
考虑最原始,最直接的情况,程序中访问的地址都直接对应于物理地址。
这种方式有以下几个问题:
1)两个使用的地址有交集的程序没法同时动行。
2)写代码时,必须考虑到要运行的计算机内存大小。比如说,程序要在两台机器上运行,但是一台内存为4G,一台内存为8G,那么程序最大能够使用的物理地址也就只有4G。
3)各个程序使用的内存无法进行控制。系统程序无法得到保护,各个程序之间无法隔离。
所以引入了分段机制。那么什么是分段机制呢?
将内存分成一段一段的(段大小不固定),为程序被分配某个段之后,程序便只能访问固定的段,无法访问其他地址。
而且代码中不再使用绝对地址,而是使用相对地址。当程序加载到内存中运行的时候,操作系统为程序分配合适的段。并记录段的起始地址,及界限。当程序需要访问内存中某个变量时,用段起始地址+相对地址(段内偏移地址)得到真实的物理地址。
通过这么一个机制,上面提到的直接使用物理内存的几个问题就都得到了解决。
2) 分段机制详述
内存的分段信息由操作系统进行维护,整个系统独一份(网上找到的文章大多都说一个处理器一份,不太理解)。维护分段信息的表叫做段描述符表,英文叫做GDT(global describetor table),里面存储的是段描述符,每个段描述符占8个字节。包含段起始地址,段界限(大小),属性。计算机有一个专门的寄存器来存储段描述符表的起始地址:GDTR。这个寄存器长48个bit,32位表示基地址,16位表示长度。
知道了段描述符表,还得知道对应表中的哪个表项,才能找到段起始地址及界面。这就需要另一个寄存器了:段选择符寄存器。段选择符寄存器长16位,13位用来存储在段描述符表中的偏移,另外3位用来存储属性。所以可以看出,GDT表长度最多只能到2^13=8192个字节。8192/8=1024b也就是1024个表项。
可以想象,对于庞大的操作系统而言,仅仅分1024个段是远远不够的。所以又设计了LDT的机制:
段选择符寄存器的3个属性位中,有一个属性位标识要访问的段描述符表项一个普通的表项,还是一个LDT。LDT和GDT一样,就是一个段描述符表,不过不是全局唯一的了。那么在LDT中,到底对应哪一个表项呢?答案是LDTR,LDTR中存储了在LDT表中的偏移。
可以看出,GDTR寄存器中的值是不需要变的。
但是段选择符寄存器,LDTR都是随着运行的程序的变化而变化的。所以保存对应程序的上下文时,需要保存对应寄存器的值。
附以上涉及的各个寄存器各个bit详细说明:
段描述符(8个字节)

GDTR(48bit,存储段描述符表的起始地址及长度)

段选择符
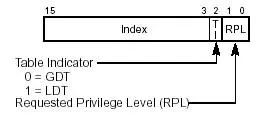
LDTR
长度也是16位。没找到关于详细结构的说明。略。。
参考
内存寻址原理(详细透彻)
3) 实模式下的分段机制
上面讲的是保护模式下的分段机制,在保护模式下利用GDT存储段信息来实现相对地址到线性地址的转换。
在实模式下也有分段机制,不过原因有所不同。
段寄存器的产生
段寄存器的产生源于Intel 8086 CPU体系结构中数据总线与地址总线的宽度不一致。数据总线的宽度,也即是ALU(算数逻辑单元)的宽度,平常说一个CPU是“16位”或者“32位”指的就是这个。8086CPU的数据总线是16位。
地址总线的宽度不一定要与ALU的宽度相同。因为ALU的宽度是固定的,它受限于当时的工艺水平,当时只能制造出16位的ALU;但地址总线不一样,它可以设计得更宽。地址总线的宽度如果与ALU相同当然是不错的办法,这样CPU的结构比较均衡,寻址可以在单个指令周期内完成,效率最高;而且从软件的解决来看,一个变量地址的长度可以用整型或者长整型来表示会比较方便。但是,地址总线的宽度还要受制于需求,因为地址总线的宽度决定了系统可寻址的范围,即可以支持多少内存。如果地址总线太窄的话,可寻址范围会很小。如果地址总线设计为16位的话,可寻址空间是2^16=64KB,这在当时被认为是不够的;Intel最终决定要让8086的地址空间为1M,也就是20位地址总线。地址总线宽度大于数据总线会带来一些麻烦,ALU无法在单个指令周期里完成对地址数据的运算。有一些容易想到的可行的办法,比如定义一个新的寄存器专门用于存放地址的高4位,但这样增加了计算的复杂性,程序员要增加成倍的汇编代码来操作地址数据而且无法保持兼容性。
Intel想到了一个折中的办法:把内存分段,并设计了4个段寄存器,CS,DS,ES和SS,分别用于指令、数据、其它和堆栈。把内存分为很多段,每一段有一个段基址,当然段基址也是一个20位的内存地址。不过段寄存器仍然是16位的,它的内容代表了段基址的高16位,这个16位的地址后面再加上4个0就构成20位的段基址。而原来的16位地址只是段内的偏移量。这样,一个完整的物理内存地址就由两部分组成,高16位的段基址和低16位的段内偏移量,当然它们有12位是重叠的,它们两部分相加在一起,才构成完整的物理地址。
参考:
段寄存器
(搜到搜去,百度百科居然是讲得最清楚的)
2.分页
1) 为什么需要分页?
线性地址是连续的,如果直接使用线性地址作为物理地址,那么为每个段分配的物理内存就必须是连续的物理内存。这不利用碎片化内存的利用,为内存管理增大了难度。所以引入了分页机制,将地址分为大小固定的页(一般为4096字节),按页为单位进行映射。连续的线性地址可以映射到不连续的的物理内存上。
分页的另一个优点是,当物理内存不足时,可以按页为单位将内存的内容转换到磁盘上保存起来。
如果不使用分页,则只能整个段整个段的进行转换。
2) 分页机制详述
对于4GB线性地址而言,每个页4KB,则总共可以分成1024*1024=1048576个页面。
要表示每个页面的物理地址,需要4个字节。那么总共需要4MB的空间来存储分页相关的信息。
按我的理解,基于上面讲的分段机制,所有程序是共享4GB的线性地址的,所以整个系统保存一份分页相关的信息即可。
可能是哪里理解得有点不对,实际情况貌似是程序可以独享4GB的线性地址。所以每个程序都需要维护一个分页信息。那么每个程序都要4M的空间用来存储分页信息,这是不可接受的。
所以设计了两级分页机制:
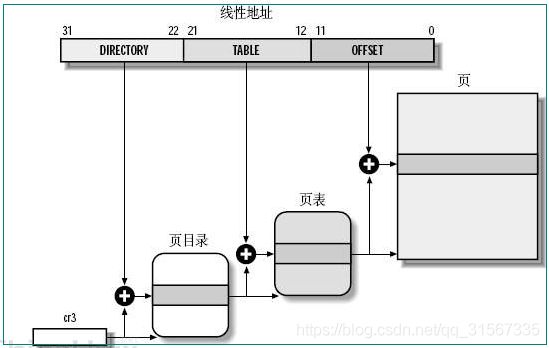
第一级叫做页目录,包含1024个表项。每个表项指向二级页表的地址。
第二级叫做页表,包含1024个页。每个表项对应一个物理地址。
页目录和页表项以及内存都是4KB对齐的。也就是说,地址的低12位必须全部为0,只需要使用地址的高20位即可。低12位可以用来存储属性。
那么怎么确定页目录存储的位置呢?答案是CR3寄存器。需要为每个程序维护一个CR3寄存器的值。
CPU内置了段部件和页部件。所以说CPU支持从相对地址(逻辑地址)到线性地址的转换,也支持线性地址到物理地址的转换。
线性地址转换为物理地址时,线性地址被分为3个部分:高10位,中间10位,低12位。
高10位4(每个表项4字节)作为索引在页目录上查找。
中间10拉4,在页表中查找。
低12位作为页内偏移,得到最终的物理地址。
参考
内存分页机制
疑问
1)每个程序的线性地址是独立的吗?为什么要为每个程序维护一份分页信息?
根据我的理解来看,各个程序的线性地址是独立的。
正是因为各个程序的线性地址是独立的,所以需要为各个程序维护分页信息。
貌似操作系统都未真正使用分段机制,分段起始地址都是0。
但是在linux上查看各个进程,却发现他们的堆栈地址空间是无重叠的部分。所以说,还是没有弄清楚。
2)以上所讲分段和分页机制,还无法支持32位计算机使用超过4GB的内存,其机制是怎么样的?
在linux上使用的机制叫PAE机制:
简述:
使用PAE扩展之后(设置CR4寄存器的第5位),地址变为8个字节。页目录和页表的大小没变,所以表示的项变少为一半。为了解决这个问题,增加了一级:cr3不再指向页目录表,而是指向一个大小为4的页目录指针表。(32字节对齐,所以只需要27位从便足够表示)
为了寻址超过4GB的空间,就需要对cr3设置不同的值。
通过设置cr3不同的值,就可以访问总共超过4GB大小的物理空间。
只有内核能够修改进程的页表,所以用户态下运行的进程不能使用大于4GB的物理空间。
https://blog.csdn.net/qq_31567335/article/details/84420554
其实还是理解得比较模糊。