初探 Kafka Streams 之二:编写 Kafka Streams 应用程序
一、构建一个 Maven 项目
通过如下命令,利用Kafka Streams Maven Archetype创建一个Streams项目:
mvn archetype:generate \
-DarchetypeGroupId=org.apache.kafka \
-DarchetypeArtifactId=streams-quickstart-java \
-DarchetypeVersion=2.5.0 \
-DgroupId=streams.examples \
-DartifactId=streams.examples \
-Dversion=0.1 \
-Dpackage=myapps

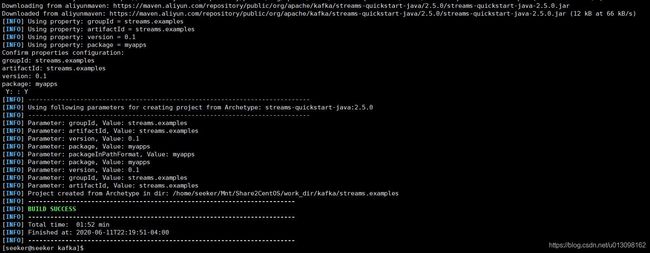
针对groupId, artifactId和package参数可以设置不同的值,所创建的项目结构如下:

pom.xml文件定义了Streams依赖项。注意:生成的pom.xml文件以Java8为目标,不适用于更高版本的 Java。src/main/java目录下已经有几个用Streams库编写的示例程序,可以删除,然后从头开始编写此类程序:
cd streams.examples/
rm src/main/java/myapps/*.java
二、编写第一个 Streams 应用程序:Pipe
在src/main/java/myapps目录下创建一个 java 文件,命名为Pipe.java:
package myapps;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.Topology;
import org.apache.kafka.streams.kstream.KStream;
import java.util.Properties;
public class Pipe {
public static void main(String[] args) throws Exception {
// 创建java.util.Properties属性映射以指定StreamsConfig中定义的不同流执行配置值
Properties props = new Properties();
// 为Streams应用程序提供唯一的标识符,以便于与同一Kafka集群对话的其他应用程序区分开来
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-pipe");
// 指定用于建立到Kafka集群的初始连接的主机/端口对列表
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.3.169:9092");
// 在同一映射中自定义其他配置:如记录键值对的默认序列化和反序列化库
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
// 定义Streams应用程序的计算逻辑,
// 在Kafka流中,该计算逻辑被定义为连接的处理器节点的拓扑,可以使用拓扑生成器来构造这样的拓扑
final StreamsBuilder builder = new StreamsBuilder();
// 使用该拓扑生成器从一个命名为streams-plaintext-input的Kafka主题创建一个源流
KStream<String, String> source = builder.stream("streams-plaintext-input");
// 将从源Kafka主题流中生成的记录(字符串键值对)写入另一个Kafka主题
source.to("streams-pipe-output");
// 检查从该生成器创建的拓扑类型
final Topology topology = builder.build();
System.out.println(topology.describe());
}
}
Kafka Streams客户端库配置见:3.6 Kafka Streams Configs
编译和运行以上程序:
mvn clean package
mvn exec:java -Dexec.mainClass=myapps.Pipe

以上打印信息说明构造的拓扑有两个处理器节点,一个是源节点KSTREAM-SOURCE-0000000000,一个是汇聚节点KSTREAM-SINK-0000000001。KSTREAM-SOURCE-0000000000从Kafka主题流streams-plaintext-input中连续读取记录,并将记录发送到它的下游节点KSTREAM-SINK-0000000001;KSTREAM-SINK-0000000001将写入它的每个接收到的记录,以便发送到另一个Kafka主题streams-pipe-output(箭头-->和<--指示此节点的下游和上游处理器节点)。该信息还说明了这个简单的拓扑没有与之相关联的全局状态存储。
完整代码如下:
package myapps;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.Topology;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class Pipe {
public static void main(String[] args) throws Exception {
// 创建java.util.Properties属性映射以指定StreamsConfig中定义的不同流执行配置值
Properties props = new Properties();
// 为Streams应用程序提供唯一的标识符,以便于与同一Kafka集群对话的其他应用程序区分开来
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-pipe");
// 指定用于建立到Kafka集群的初始连接的主机/端口对列表
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.3.169:9092");
// 在同一映射中自定义其他配置:如记录键值对的默认序列化和反序列化库
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
// 定义Streams应用程序的计算逻辑,
// 在Kafka流中,该计算逻辑被定义为连接的处理器节点的拓扑,可以使用拓扑生成器来构造这样的拓扑
final StreamsBuilder builder = new StreamsBuilder();
// 使用该拓扑生成器从一个命名为streams-plaintext-input的Kafka主题创建一个源流
// 将从源Kafka主题流中生成的记录(字符串键值对)写入另一个Kafka主题
builder.stream("streams-plaintext-input").to("streams-pipe-output");
// 检查从该生成器创建的拓扑类型
final Topology topology = builder.build();
System.out.println(topology.describe());
// 接下来,利用上面构建的两个组件来构建Streams客户端
final KafkaStreams streams = new KafkaStreams(topology, props);
// 通过调用其start()函数,可以触发此客户端的执行;在此客户端上调用close()之前,执行不会停止
// 可以添加一个带有倒计时锁存器的关机钩子,以捕获用户中断并在终止此程序时关闭客户端
final CountDownLatch latch = new CountDownLatch(1);
// 将关闭处理程序附加到捕获Ctrl-C
Runtime.getRuntime().addShutdownHook(new Thread("streams-shutdown-hook") {
@Override
public void run() {
streams.close();
latch.countDown();
}
});
try {
streams.start();
latch.await();
} catch (Throwable e) {
System.exit(1);
}
System.exit(0);
}
}
假设 Kafka 运行在192.168.3.169:9092,并且主题streams-plaintext-input和streams-pipe-output已经创建,编译运行:
# 编译运行
mvn clean package
mvn exec:java -Dexec.mainClass=myapps.Pipe
# 启动控制台生产者
bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic streams-plaintext-input
# 启动控制台消费者
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-pipe-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.StringDeserializer
三、编写第二个 Streams 应用程序:Line Split
前面已经学习了如何使用StreamsConfig和Topology这两个关键组件构建 Streams 客户端,接下来通过扩展当前拓扑来添加一些实际的处理逻辑。创建文件src/main/java/myapps/LineSplit.java,完整代码如下:
package myapps;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.Topology;
import org.apache.kafka.streams.kstream.KStream;
//import org.apache.kafka.streams.kstream.ValueMapper;
import java.util.Arrays;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class LineSplit {
public static void main(String[] args) throws Exception {
// 创建java.util.Properties属性映射以指定StreamsConfig中定义的不同流执行配置值
Properties props = new Properties();
// 为Streams应用程序提供唯一的标识符,以便于与同一Kafka集群对话的其他应用程序区分开来
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-linesplit");
// 指定用于建立到Kafka集群的初始连接的主机/端口对列表
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.3.169:9092");
// 在同一映射中自定义其他配置:如记录键值对的默认序列化和反序列化库
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
// 定义Streams应用程序的计算逻辑,
// 在Kafka流中,该计算逻辑被定义为连接的处理器节点的拓扑,可以使用拓扑生成器来构造这样的拓扑
final StreamsBuilder builder = new StreamsBuilder();
// 由于源流的每个记录都是字符串类型的键值对,将该值字符串视为文本行,
// 使用FlatMapValues运算符将其拆分为多个字符
KStream<String, String> source = builder.stream("streams-plaintext-input");
// KStream words = source.flatMapValues(new ValueMapper>() {
// @Override
// public Iterable apply(String value) {
// return Arrays.asList(value.split("\\W+"));
// }
// });
// 如果使用的是JDK 8,可以使用lambda表达式简化代码
source.flatMapValues(value -> Arrays.asList(value.split("\\W+")))
.to("streams-linesplit-output");
// 检查从该生成器创建的拓扑类型
final Topology topology = builder.build();
System.out.println(topology.describe());
// 接下来,利用上面构建的两个组件来构建Streams客户端
final KafkaStreams streams = new KafkaStreams(topology, props);
// 通过调用其start()函数,可以触发此客户端的执行;在此客户端上调用close()之前,执行不会停止
// 可以添加一个带有倒计时锁存器的关机钩子,以捕获用户中断并在终止此程序时关闭客户端
final CountDownLatch latch = new CountDownLatch(1);
// 将关闭处理程序附加到捕获Ctrl-C
Runtime.getRuntime().addShutdownHook(new Thread("streams-shutdown-hook") {
@Override
public void run() {
streams.close();
latch.countDown();
}
});
try {
streams.start();
latch.await();
} catch (Throwable e) {
System.exit(1);
}
System.exit(0);
}
}
编译运行:
# 编译运行
mvn clean package
mvn exec:java -Dexec.mainClass=myapps.LineSplit
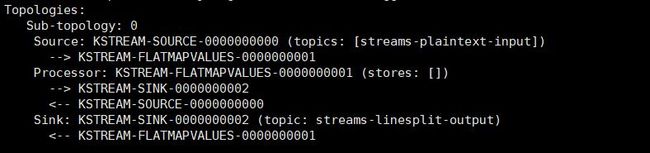
如图中所示,一个新的处理器节点KSTREAM-FLATMAPVALUES-0000000001被注入到原始源节点和汇聚节点之间的拓扑中。它将源节点作为其父节点,将汇节点作为其子节点。换句话说,源节点获取的每条记录将首先遍历到要处理的新添加的KSTREAM-FLATMAPVALUES-0000000001节点,并因此生成一个或多个新记录。它们将继续向下遍历到sink节点,并将其写回 Kafka。注意,此处理器节点是“无状态(stateless)”的,因为它与任何存储(即 stores: [])都没有关联。
# 启动控制台生产者
bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic streams-plaintext-input
![]()
# 启动控制台消费者
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-linesplit-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.StringDeserializer
四、编写第三个 Streams 应用程序:WordCount
更进一步,通过计算从源文本流中拆分的单词的出现次数,向拓扑中添加一些“有状态(stateful)”计算。创建文件src/main/java/myapps/WordCount.java,完整代码如下:
package myapps;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.common.utils.Bytes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.Topology;
import org.apache.kafka.streams.kstream.*;
import org.apache.kafka.streams.state.KeyValueStore;
import java.util.Arrays;
import java.util.Locale;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class WordCount {
public static void main(String[] args) throws Exception {
// 创建java.util.Properties属性映射以指定StreamsConfig中定义的不同流执行配置值
Properties props = new Properties();
// 为Streams应用程序提供唯一的标识符,以便于与同一Kafka集群对话的其他应用程序区分开来
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-wordcount");
// 指定用于建立到Kafka集群的初始连接的主机/端口对列表
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.3.169:9092");
// 在同一映射中自定义其他配置:如记录键值对的默认序列化和反序列化库
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
// 定义Streams应用程序的计算逻辑,
// 在Kafka流中,该计算逻辑被定义为连接的处理器节点的拓扑,可以使用拓扑生成器来构造这样的拓扑
final StreamsBuilder builder = new StreamsBuilder();
// 为了对单词进行计数,首先修改flatMapValues运算符,将所有单词视为小写
KStream<String, String> source = builder.stream("streams-plaintext-input");
// // 为了进行计数聚合,首先指定要用groupBy运算符为值字符串(即消息字)上的流设置键,此运算符生成一个新的分组流,
// // 然后可以由count运算符进行聚合,该运算符在每个分组键上生成一个运行计数
// KTable counts = source.flatMapValues(new ValueMapper>() {
// @Override
// public Iterable apply(String value) {
// return Arrays.asList(value.toLowerCase(Locale.getDefault()).split("\\W+"));
// }
// }).groupBy(new KeyValueMapper() {
// @Override
// public String apply(String key, String value) {
// return value;
// }
// // 将结果具体化到名为"counts-store"的KeyValueStore中,
// // 物化存储总是类型,因为这是最内部存储的格式
// }).count(Materialized.> as("counts-store"));
//
// // 注意,count运算符有一个具体化参数,该参数指定运行的计数应存储在名为counts-store的状态存储中,可实时查询;
// // 还可以将counts KTable的changelog流写回到另一个Kafka主题,如streams-wordcount-output
// // 由于结果是changelog流,输出主题streams-wordcount-output应该配置为启用日志压缩,
// // 并且值类型不再是String而是Long,因此默认的序列化类不再适用于将其写入Kafka。
// counts.toStream().to("streams-wordcount-output", Produced.with(Serdes.String(), Serdes.Long()));
// 使用JDK8的lambda表示式简化以上代码[36~56行]
source.flatMapValues(value -> Arrays.asList(value.toLowerCase(Locale.getDefault()).split("\\W+")))
.groupBy((key, value) -> value)
.count(Materialized., Long, KeyValueStore<Bytes, byte[]>>as("counts-store"))
.toStream()
.to("streams-wordcount-output", Produced.with(Serdes.String(), Serdes.Long()));
// 检查从该生成器创建的拓扑类型
final Topology topology = builder.build();
System.out.println(topology.describe());
// 接下来,利用上面构建的两个组件来构建Streams客户端
final KafkaStreams streams = new KafkaStreams(topology, props);
// 通过调用其start()函数,可以触发此客户端的执行;在此客户端上调用close()之前,执行不会停止
// 可以添加一个带有倒计时锁存器的关机钩子,以捕获用户中断并在终止此程序时关闭客户端
final CountDownLatch latch = new CountDownLatch(1);
// 将关闭处理程序附加到捕获Ctrl-C
Runtime.getRuntime().addShutdownHook(new Thread("streams-shutdown-hook") {
@Override
public void run() {
streams.close();
latch.countDown();
}
});
try {
streams.start();
latch.await();
} catch (Throwable e) {
System.exit(1);
}
System.exit(0);
}
}
编译运行:
# 编译运行
mvn clean package
mvn exec:java -Dexec.mainClass=myapps.WordCount
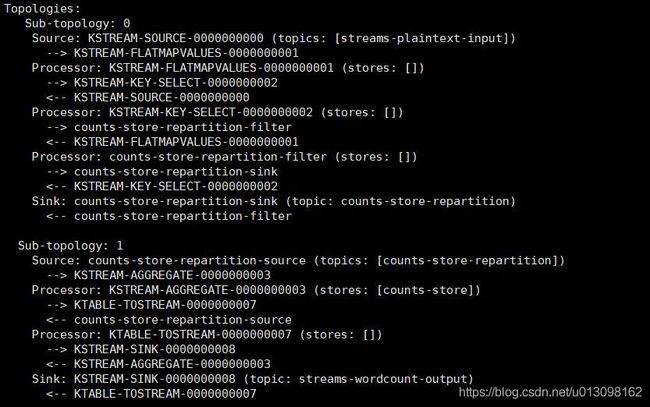
如图所示,拓扑现在包含两个断开连接的子拓扑。第一个子拓扑的汇节点counts-store-repartition-sink将写入重新分区主题counts-store-repartition,第二个子拓扑的源节点counts-store-repartition-source将读取该主题。重新分区主题用于通过源流的聚合键(本例中即值字符串)对源流进行“shuffle”。此外,在第一个子拓扑中,在分组KSTREAM-KEY-SELECT-0000000002节点和汇节点之间注入一个无状态counts-store-repartition-filter节点,以过滤出聚合键为空的任何中间记录。
在第二个子拓扑中,聚合节点KSTREAM-AGGREGATE-0000000003与名为counts-store的状态存储关联(该名称由用户在count运算符中指定)。当从即将到来的流源节点接收到每条记录时,聚合处理器将首先查询其相关联的counts-store存储,以获取该键当前计数,增加一个,然后将新计数写回存储。键的每个更新计数也将通过管道传输到下游KTABLE-TOSTREAM-0000000007节点,该节点将此更新流解释为一个记录流,然后再通过管道传输到汇节点KSTREAM-SINK-0000000008,以便回写到 Kafka。
# 启动控制台生产者
bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic streams-plaintext-input
![]()
# 启动控制台消费者
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer

五、参考资料
[1] Tutorial: Write a Kafka Streams Application