全景图拼接 特征匹配 附代码
全景图拼接项目
本项目和源代码来自唐宇迪项目实战课程
先放代码
ImageStiching.py
from Stitcher import Stitcher
import cv2
def resize(img):
height, width = img.shape[:2]
size = (int(width*0.4), int(height*0.4))
img_resize = cv2.resize(img, size, interpolation=cv2.INTER_AREA)
return img_resize
# 读取拼接图片
imageA = cv2.imread("bag_1.jpg")
imageB = cv2.imread("bag_2.jpg")
a = resize(imageA)
b = resize(imageB)
# 把图片拼接成全景图
stitcher = Stitcher()
(result, vis) = stitcher.stitch([a, b], showMatches=True)
# 显示所有图片
cv2.imshow("Image A", a)
cv2.imshow("Image B", b)
cv2.imshow("Keypoint Matches", vis)
cv2.imshow("Result", result)
cv2.waitKey(0)
cv2.destroyAllWindows()
Stitcher.py
import numpy as np
import cv2
class Stitcher:
# 拼接函数
def stitch(self, images, ratio=0.75, reprojThresh=4.0, showMatches=False):
# 获取输入图片
(imageB, imageA) = images
# 检测A、B图片的SIFT关键特征点,并计算特征描述子
(kpsA, featuresA) = self.detectAndDescribe(imageA)
(kpsB, featuresB) = self.detectAndDescribe(imageB)
print("kpsA, featuresA", (kpsA, featuresA))
# 匹配两张图片的所有特征点,返回匹配结果
M = self.matchKeypoints(kpsA, kpsB, featuresA, featuresB, ratio, reprojThresh)
print("M", M)
# 如果返回结果为空,没有匹配成功的特征点,退出算法
if M is None:
return None
# 否则,提取匹配结果
# H是3x3视角变换矩阵
(matches, H, status) = M
# 将图片A进行视角变换,result是变换后图片
result = cv2.warpPerspective(imageA, H, (imageA.shape[1] + imageB.shape[1], imageA.shape[0]))
self.cv_show('result', result)
# 将图片B传入result图片最左端
result[0:imageB.shape[0], 0:imageB.shape[1]] = imageB
self.cv_show('result', result)
# 检测是否需要显示图片匹配
if showMatches:
# 生成匹配图片
vis = self.drawMatches(imageA, imageB, kpsA, kpsB, matches, status)
# 返回结果
return (result, vis)
# 返回匹配结果
return result
def cv_show(self, name, img):
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
def detectAndDescribe(self, image):
# 将彩色图片转换成灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 建立SIFT生成器
descriptor = cv2.xfeatures2d.SIFT_create()
# 检测SIFT特征点,并计算描述子
(kps, features) = descriptor.detectAndCompute(image, None)
# 将结果转换成NumPy数组
kps = np.float32([kp.pt for kp in kps])
# 返回特征点集,及对应的描述特征
return (kps, features)
def matchKeypoints(self, kpsA, kpsB, featuresA, featuresB, ratio, reprojThresh):
# 建立暴力匹配器
matcher = cv2.BFMatcher()
# 使用KNN检测来自A、B图的SIFT特征匹配对,K=2
rawMatches = matcher.knnMatch(featuresA, featuresB, 2)
matches = []
for m in rawMatches:
# 当最近距离跟次近距离的比值小于ratio值时,保留此匹配对
if len(m) == 2 and m[0].distance < m[1].distance * ratio:
# 存储两个点在featuresA, featuresB中的索引值
matches.append((m[0].trainIdx, m[0].queryIdx))
# 当筛选后的匹配对大于4时,计算视角变换矩阵
if len(matches) > 4:
# 获取匹配对的点坐标
ptsA = np.float32([kpsA[i] for (_, i) in matches])
ptsB = np.float32([kpsB[i] for (i, _) in matches])
# 计算视角变换矩阵
(H, status) = cv2.findHomography(ptsA, ptsB, cv2.RANSAC, reprojThresh)
# 返回结果
return (matches, H, status)
# 如果匹配对小于4时,返回None
return None
def drawMatches(self, imageA, imageB, kpsA, kpsB, matches, status):
# 初始化可视化图片,将A、B图左右连接到一起
(hA, wA) = imageA.shape[:2]
(hB, wB) = imageB.shape[:2]
vis = np.zeros((max(hA, hB), wA + wB, 3), dtype="uint8")
vis[0:hA, 0:wA] = imageA
vis[0:hB, wA:] = imageB
# 联合遍历,画出匹配对
for ((trainIdx, queryIdx), s) in zip(matches, status):
# 当点对匹配成功时,画到可视化图上
if s == 1:
# 画出匹配对
ptA = (int(kpsA[queryIdx][0]), int(kpsA[queryIdx][1]))
ptB = (int(kpsB[trainIdx][0]) + wA, int(kpsB[trainIdx][1]))
cv2.line(vis, ptA, ptB, (0, 234, 0), 1)
# 返回可视化结果
return vis
显示结果:
输入的两张相同大小的图像


全景拼接的结果:

特征匹配结果:

1理论背景
本例中用到图像的特征匹配,即找出两张图片中的共同特征。
本例子中用到了两种特征匹配方法:蛮力匹配和knn匹配方法。
蛮力匹配方法的原理(BF)
先放代码:
import cv2
import numpy as np
from matplotlib import pyplot as plt
img1 = cv2.imread("candy.jpg")
img2 = cv2.imread("can.jpg")
def cv_show(name, img):
height, width = img.shape[:2]
size = (int(width* 0.4), int(height * 0.4))
shrink = cv2.resize(img, size, interpolation=cv2.INTER_AREA)
cv2.imshow(name, shrink)
cv2.waitKey(0)
cv2.destroyAllWindows()
cv_show("img1", img1)
cv_show("img2", img2)
sift = cv2.xfeatures2d.SIFT_create()
print("sift", sift)
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
bf = cv2.BFMatcher(crossCheck=True)
matches = bf.match(des1, des2)
print(len(matches))
matches_10 = sorted(matches, key=lambda x: x.distance)
print(len(matches_10))
print(matches_10[:10])
img3 = cv2.drawMatches(img1, kp1, img2, kp2, matches_10[:10], None, flags=2)
cv_show("img3", img3)
首先读取灰度图像,用SIFT算法进行特征提取。kp1, des1 = sift.detectAndCompute()函数有两个返回值,第一个返回值是特征点的坐标,第二个返回值是特征向量。
然后使用BF特征匹配方法
bf = cv2.BFMatcher(crossCheck=True)
matches = bf.match(des1, des2)
函数cv2.BFMatcher()的参数:第一个参数表示使用的测量距离,这里使用的是欧氏距离,为默认值,而且默认使用NORM_L2来归一化数组的欧氏距离。第二个参数是一个布尔值,默认为Faulse,本例中crossCheck设置为True,即两张图像中的特征点必须互相都是唯一选择,即第一张图像的i点与第二张图像的j点匹配,则根据第二张图像的j点计算匹配的特征点也应该得到第一张图像中的i点。
这个匹配函数的返回值到底是什么?
我们来打印出前10个结果
返回值中包涵3部分内容:
1.queryIdx:测试图像的特征点描述符的下标(第几个特征点描述符),同时也是描述符对应特征点的下标。
2.trainIdx:样本图像的特征点描述符下标,同时也是描述符对应特征点的下标。
3.distance:代表这一对匹配的特征点描述符的欧式距离,数值越小也就说明俩个特征点越相近。
知道了这一点以后继续看程序步骤,接着对返回值按照distance进行排序(从小到大),最后cv2.drawMatches(img1, kp1, img2, kp2, matches_10[:10], None, flags=2)对图像的关键点进行连线操作。
参数:
前四个参数分别表示两张图片和两张图片提取的特征点, matches_10表示进过cv2.BFMatcher获得的匹配的索引值,也有距离, flags表示有几个图像,这里是匹配两张图像所以设为2。
显示结果:

knn匹配方法原理
import cv2
img1 = cv2.imread("can.jpg")
img2 = cv2.imread("candy.jpg")
def cv_show(name, img):
height, width = img.shape[:2]
size = (int(width * 0.4), int(height * 0.4))
shrink = cv2.resize(img, size, interpolation=cv2.INTER_AREA)
cv2.imshow(name, shrink)
cv2.waitKey(0)
cv2.destroyAllWindows()
cv_show("img1", img1)
cv_show("img2", img2)
sift = cv2.xfeatures2d.SIFT_create()
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
bf = cv2.BFMatcher()
matches = bf.knnMatch(des1, des2, k=2)
print("matches", matches)
good = []
for m, n in matches:
if m.distance < 0.6 * n.distance:
good.append([m])
img3 = cv2.drawMatchesKnn(img1, kp1, img2, kp2, good, None, flags=2)
cv_show("img3", img3)
和上一种个特征匹配的方法相同, 首先进行SIFT特征提取。
返回值是特征点的坐标和特征向量。
然后使用cv2.BFMatcher()特征匹配算法,上一节已经说过了返回值包含三部分内容,其中第三部分distance表示欧氏距离,该值越小,说明两点越相似。
bf.knnMatch()函数表示
第一张图中的点对应第二张图中两个特征点。
该函数的返回值是什么,打印出来看一下:

返回的是对应两个特征点的信息:(上文已经提到过)
1.queryIdx:测试图像的特征点描述符的下标(第几个特征点描述符),同时也是描述符对应特征点的下标。
2.trainIdx:样本图像的特征点描述符下标,同时也是描述符对应特征点的下标。
3.distance:代表这一对匹配的特征点描述符的欧式距离,数值越小也就说明两个特征点越相近。
for m, n in matches:
if m.distance < 0.6 * n.distance:
good.append([m])
这里m, n分别表示两个特征点,如果两个特征点distance比值小于0.6,则保留该特征匹配点。
cv2.drawMatchesKnn(img1, kp1, img2, kp2, good, None, flags=2)同样的,对图像的关键点进行连线操作。
显示结果:

显示如果现实knn特征匹配的结果将存入good中的值改为[m, n], 结果如图所示:

在程序ImageStiching.py中调用sticher中的自定义函数。
接着,逐个函数解释函数的功能:
1、detectAndDescribe(self, image)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
descriptor = cv2.xfeatures2d.SIFT_create()
(kps, features) = descriptor.detectAndCompute(image, None)
kps = np.float32([kp.pt for kp in kps])
return (kps, features)
首先将图像转化成灰度图, 用SIFT进行特征提取。
(kps, features) = descriptor.detectAndCompute(image, None)检测特征点并计算描述子。
kps = np.float32([kp.pt for kp in kps])将返回的特征点转化成numpy格式的数组。即用数组来表示特征点的坐标。
这个函数做了什么呢?
用SIFT算法对图像进行特征提取,并将特征点的坐标转化成数组的格式。提取两张图片里的关键点、提取局部不变特征
2、matchKeypoints(self, kpsA, kpsB, featuresA, featuresB, ratio, reprojThresh)
matcher = cv2.BFMatcher()
rawMatches = matcher.knnMatch(featuresA, featuresB, 2)
matches = []
for m in rawMatches:
if len(m) == 2 and m[0].distance < m[1].distance * ratio:
matches.append((m[0].trainIdx, m[0].queryIdx))
if len(matches) > 4:
ptsA = np.float32([kpsA[i] for (_, i) in matches])
ptsB = np.float32([kpsB[i] for (i, _) in matches])
(H, status) = cv2.findHomography(ptsA, ptsB, cv2.RANSAC, reprojThresh)
return (matches, H, status)
return None
首先用cv2.BFMatcher()进行特征匹配。使用Knn检测来自A、B图的SIFT特征匹配对。当最近距离跟次近距离的比值小于ratio值时,保留此匹配对。
存储在数组中的内容是:(m[0].trainIdx, m[0].queryIdx), 还记得cv2.BFMatcher()返回值包涵部分内容分别是什么吗?
trainIdx:样本图像的特征点描述符下标,同时也是描述符对应特征点的下标。
queryIdx:测试图像的特征点描述符的下标。
打印出结果如图所示:

第一个值表示特征点的下标,第二个值表示匹配特征点的欧氏距离。
当匹配对大于4时,计算视觉变换矩阵。
为什么是4个, 这个变换矩阵是三维的,最后一个元素设为1, 那么矩阵有8个未知数。一个点中包含两个值,那么至少需要8个值,即4个点。
函数cv2.findHomography的参数:
InputArray srcPoints,(源平面中点的坐标矩阵,可以是CV_32FC2类型,也可以是vector类型)
InputArray dstPoints,(目标平面中点的坐标矩阵,可以是CV_32FC2类型,也可以是vector类型)
int method = 0, (计算单应矩阵所使用的方法。)
0 - 利用所有点的常规方法
RANSAC -基于RANSAC的鲁棒算法
LMEDS - 最小中值鲁棒算法
RHO -PROSAC-基于PROSAC的鲁棒算法
double ransacReprojThreshold = 3,(将点对视为内点的最大允许重投影错误阈值(仅用于RANSAC和RHO方法)。)
mask = noArray(),(可选输出掩码矩阵,通常由鲁棒算法(RANSAC或LMEDS)设置。 请注意,输入掩码矩阵是不需要设置的。)
const int maxIters = 2000,(RANSAC算法的最大迭代次数,默认值为2000。)
const double confidence = 0.995 (可信度值,取值范围为0到1。)
本实例中 (H, status) = cv2.findHomography(ptsA, ptsB, cv2.RANSAC, reprojThresh)
前两个参数表示提取到的特征点的坐标矩阵, 在此之前还对数组进行以下操作:
ptsA = np.float32([kpsA[i] for (_, i) in matches])
ptsB = np.float32([kpsB[i] for (i, _) in matches])
因为函数对输入的特征点矩阵的格式有要求。
第三个参数是计算矩阵使用的方法,本实例中使用的是随机抽样一致性算法(RANSAC)
最后一个参数是将RANSAC算法的误差阈值设置为3
把变换矩阵H打印出来:

那么matchKeypoints函数又做了什么?
利用上一步的到的特征点的坐标来计算视觉变换矩阵H, 用knn算法返回匹配结果
3drawMatches(self, imageA, imageB, kpsA, kpsB, matches, status)
(hA, wA) = imageA.shape[:2]
(hB, wB) = imageB.shape[:2]
vis = np.zeros((max(hA, hB), wA + wB, 3), dtype="uint8")
vis[0:hA, 0:wA] = imageA
vis[0:hB, wA:] = imageB
for ((trainIdx, queryIdx), s) in zip(matches, status):
if s == 1:
ptA = (int(kpsA[queryIdx][0]), int(kpsA[queryIdx][1]))
ptB = (int(kpsB[trainIdx][0]) + wA, int(kpsB[trainIdx][1]))
cv2.line(vis, ptA, ptB, (0, 234, 0), 1)
return vis
首先计算出图像的高和宽,确定生成图像的大小。
宽度是两张图片的宽度之和,高度是两张图片中高度的最大值。
for ((trainIdx, queryIdx), s) in zip(matches, status)联合遍历,画出匹配对。
其中(trainIdx, queryIdx)中的内容是样本图像和测试图像的特征点描述符的下标。
将下标和特征点进行匹配,然后将特征点连接起来。
drawMatches(self, imageA, imageB, kpsA, kpsB, matches, status)函数的作用:
连接匹配的特征点
4、stitch 函数
首先读取图像,调用detectAndDescribe函数提取图像关键点和局部不变特征。
调用matchKeypoints函数用knn算法返回匹配结果, 并且得到变换矩阵。M中存放着匹配结果和变换矩阵。打印结果如下:
Matches(两张图像特征点描述符的下标):
H(变换矩阵)

status(匹配结果布尔值)

然后调用cv2.warpPerspective(imageA, H, (imageA.shape[1] + imageB.shape[1], imageA.shape[0]))函数进行透视变换操作。
(在OCR文本识别任务中用到过)
第一个参数src:输入图像
第二个参数dst:输出图像
第三个参数M:变换矩阵
第四个参数dsize:变换后输出图像尺寸
flag:插值方法
borderMode:边界像素外扩方式
borderValue:边界像素插值,默认用0填充
result[0:imageB.shape[0], 0:imageB.shape[1]] = imageB
将图片B传入result图片最左端。
放另外一张图的结果
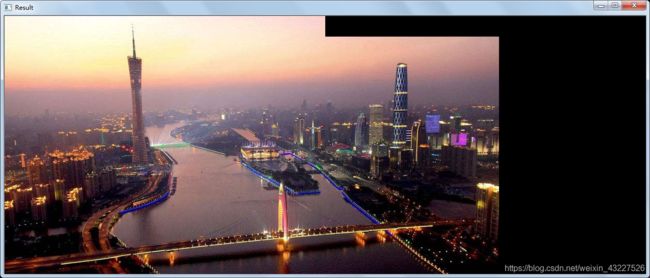
至此全景图拼接任务完成,恳请批评指正,
感谢外我提供帮助的博客,你辛勤耕耘让我受益匪浅。
https://blog.csdn.net/fengyeer20120/article/details/87798638
我想开学 了。