操作系统(十) -- 段页结合的实际内存管理模型
文章目录
- 前言
- 虚拟内存
- 虚拟内存的引入
- 虚拟内存
- 一个实际的段、页式内存管理
- 分配内存、建立段表
- 分配内存、建立页表
- MMU地址处理
- 参考资料
前言
前面说过用户程序喜欢分段来分配内存,但是实际的物理内存更加倾向于分页管理,因为这样可以使内存的利用率最大化。作为操作系统,既要向上负责,又要向下负责。这一篇博客主要谈谈用户程序需要的段和物理内存需要的页是如何结合到一起的。
虚拟内存
虚拟内存的引入
首先两个条件,第一:物理内存必须得是分页管理的;第二:对用户来说是分段的。但是用户程序最终又得在内存上面跑,因此肯定需要某种机制或者转化使得以用户程序的视角看起来内存是分段的,以物理内存的视角看起来又是分页的,这种机制就是虚拟内存
虚拟内存
虚拟内存是一种和物理内存差不多的东西,每一个字节都有对应的地址。但是有一点与物理内存不同,其实从它的名字就能看出来,“虚拟”:即实际上并不存在,它只是一种机制,纯粹是用程序表示的,没有这种硬件。它的作用就是让上层程序看起来是内存是分段的,而实际上是分页的。那它是怎么实现的呢?
基本思想:用户程序使用了一段内存,那么首先会在虚拟内存上面找到一段空的内存,然后将用户程序使用的内存映射到这段内存上,然后虚拟内存再将这段内存映射到物理内存上。
从这里能看出,用户程序使用的逻辑内存经过了两次映射才达到物理内存,第一次映射是段的映射,需要段表;第二次是页的映射,需要页表。那么逻辑地址究竟是如何变成物理地址的呢?逻辑地址是段号+偏移(CS:IP)组成的,首先根据段号在段表中找到虚拟内存的段基址,然后加上偏移得到虚拟地址(即在虚拟内存上面的地址),格式是:页号+偏移。然后根据页号在页表中找到对应的页框号,再加上偏移得到最后的物理地址。实现了逻辑地址与物理地址的对应。也就是重定位操作。
一个实际的段、页式内存管理
内存管理的核心就是内存分配,所以从程序放入内存、使用内存开始。其实只要程序可以正常运行,就说明内存使用起来了;管理就是如何更好的使用;这点可以类似CPU的管理,首先使用起来,然后如何让它更高效的使用。
程序放入内存首先就是要在虚拟内存中给它分配段、建立段表,然后是分配页、建立页表;注意先后关系。第一步:在虚拟内存上分配段;如何分配呢?首先肯定是得找到空闲的段,如何找,可以使用前面谈到过的内存分区方法。这个见前文《内存的分段与分页》。然后将用户程序映射到虚拟内存,建立段表,然后分配页,建立页表。这里的分配页并不是在内存里面查找空闲页的,而是另外一种方式。
分配内存、建立段表
创建进程使用的是fork()系统调用,从前面系统调用的知识可以知道fork()调用首先是sys_fork->copy_process。
在Linux/kernel/fork.c
int copy_process(int nr, long ebp...)
{
………………
copy_mem(nr,p);
………………
}
int copy_mem(int nr, task_struct *p)
{
unsigned long new_data_base;
new_data_base = nr*0x4000000; // nr * 64M
set_base(p_>ldt[1], new_data_base); // 代码段
set_base(p->ldt[2], new_data_base); // 数据段
………………
}
上面是fork()建立一个进程执行的代码。进入copy_process后,在copy_process中调用copy_men();这个函数就是给该进程在虚拟内存上分配内存空间的,形参nr和p分别表示:第nr个进程和该进程的pcb。ldt表示的是段表。
new_data_base = nr*0x4000000; // nr * 64M
首先给该进程在虚拟内存上分配一块64M的内存块。可以看到第0个进程内存区域就是0 ~ 64M,第一个进程64~128M,依次类推,互不重叠。然后将p的ldt[1]和ldt[2]都指向这块内存。如下图
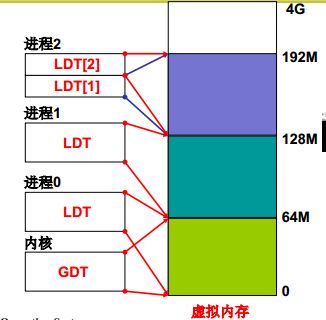
这里的ldt[1]和ldt[2]指的是数据段和代码段,这里的数据段和代码段
到这里为止,在虚拟内存上分配内存、建立段表就弄好了。
分配内存、建立页表
接下来就是分配内存、建立页表。还是上面那个copy_mem()函数
int copy_mem(int nr, task_struct *p)
{
unsigned long old_data_base;
old_data_base = get_base(currnet->ldt[2]);
copy_page_tables(old_data_base, new_data_base, data_limit);
………………
}
int copy_page_tables(unsigned long from, unsigned long to , long size)
{
from_dir = (unsigned long *) ((from>>20) & 0xffc);
to_dir = (unsigned long * )((to>>20) & 0xffc);
size = (unsigned long)(size + 0x3fffff) >> 22;
for (; size-->0; from_dir++, to_dir++)
{
from_page_table=(0xfffff000 & *from_dir);
to_page_table = get_free_page();
*to_dir = ((unsigned long) to_page_table) | 7;
}
}
首先看copy_mem函数
old_data_base = get_base(currnet->ldt[2]);
这条语句的含义就是得到当前进程的虚拟内存地址赋给old_data_base;然后调用copy_page_tables()函数,首先from和to是什么?从形参以及copy_mem里面的调用可以看出,这两个都是32为虚拟内存地址。from_dir指向一个父进程的页目录项(章),to_dir指向一个子进程的页目录项(章)。前面说过了32位虚拟内存地址的构成如下图。

from_dir = (unsigned long *) ((from>>20) & 0xffc);
这句话是什么意思?from右移22位得到的是页目录号,但是
(from>>20) & 0xffc
是什么意思。回想一下多级页表的工作原理,from>>22得到的是目录项编号,每一项都是4字节,即from>>22之后乘以4就得到该项的相对于页目录指针(CR3)的偏移了,也就是可以找到具体的页目录号。(from>>20) & 0xffc这里看视频的时候没怎么听懂,上面这个解释是我自己的理解。而from>>22乘以4不正好是(from>>20) & 0xffc吗。
size就是页目录项数(章数)。
for (; size-->0; from_dir++, to_dir++)
{
from_page_table=(0xfffff000 & *from_dir);
to_page_table = get_free_page();
*to_dir = ((unsigned long) to_page_table) | 7;
}
前面说过from_dir指向一个父进程的页目录项(章),那么*from_dir就是from_dir对应的那个页目录表(节),也就是from_page_table的含义。get_free_page()新建一个子进程的页目录表(节);然后将这个页目录表赋给to_dir,但是to_dir指向的这个表里面的内容还是空的,接下来就是要将这个表填上
for (; nr-->0; from_page_table++, to_page_table++)
{
this_page = *from_page_table;
this_page &= ~2; // 设置为只读
*to_page_table = this_page;
*from_page_table = this_page;
this_page -= LOW_MEN;
this->page >>= 12;
mem_map[this_page]++;
}
主要就是看这一段
this_page = *from_page_table;
this_page &= ~2; // 设置为只读
*to_page_table = this_page;
这三句的含义就是将父进程的from_page_table赋值给子进程的to_page_table,并且将对应的页设置为只读。这也是前面说的为什么不用为子进程找空闲页,因为子进程用的就是父进程的内存。为什么要设置为只读属性?两个进程共享同一块内存,如果都是读,没有任何问题,但是如何要写呢?那么就出问题了;因此要设置为只读。到这里分配物理页、建立页表就说完了。
MMU地址处理
到目前为止,分配内存、建立段表,分配内存、建立页表都讲完了。程序就可以正确的存储到物理内存了。真不容易啊-。接下来程序执行的时候只需要根据这两张表找到对应的内存就好了;当然如果查这两张表的操作全部由软件来实现的话就要浪费很多时间了,因此计算机将查表的操作交给硬件来完成,只要从用户程序那里得到CS:ip,硬件会自动得到该逻辑地址对应的物理地址的,这个硬件就是MMU。
参考资料
哈工大李志军操作系统