这一节我们主要讨论机器学习具体应用中的一些建议,大部分内容都不会涉及到数学,但却可能是最难理解的一部分。另外本文的部分内容可能有一些争议,部分内容也不适用于学术研究。
机器学习算法的诊断
我们来思考如下这个问题:在垃圾邮件分类问题中,我们从50000+的词汇表中选择了100个单词作为特征,然后选择贝叶斯逻辑回归(Bayesian logistic regression)模型,利用梯度下降法进行训练,但是训练得到的结果有20%的误差,这显然是不能接受的。
这个模型的目标函数如下:
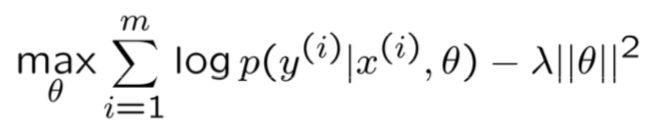
那么我们下一步应该如何优化呢?通常我们可以有如下多个改进方式:
- 增加训练数据
- 尝试更小的特征集合
- 尝试更大的特征集合
- 尝试改变特征(比如使用邮件的标题和正文部分)
- 增加梯度下降的迭代次数
- 尝试用牛顿方法
- 改变正则化参数λ
- 尝试其他模型,比如SVM
这些方法都可能有用,但是挨个进行实验非常耗时,如果碰巧解决问题也可能只是运气好。因此更好的方法是我们对算法进行诊断,并根据诊断结果进行针对性的改进。
第一个的诊断方法是判断算法是过拟合还是欠拟合。过拟合意味着高方差,欠拟合意味着高偏差。我们可以通过学习曲线(learning curve)来诊断模型到底是高方差还是高偏差的。
下图展示的是高偏差模型的学习曲线:

可以看出,当训练集个数增加时,测试误差逐步减少,但是测试误差和训练误差之间仍存在较大的间隔。因此增加训练数据可以改善模型。
下图展示的是高方差模型的学习曲线:

可以看出,测试误差和训练误差之间的间隔很小,但是它们的误差率与理想值相差很远。
第二个诊断方法是关于优化算法和优化目标。这里我们继续接着刚才的例子讨论:假设通过BLR(贝叶斯逻辑回归)算法在垃圾邮件上的误差是2%,在正常邮件上的误差也是2%(对于正常邮件来说,这个误差是不可接受的),而通过SVM算法在垃圾邮件上的误差是10%,在正常邮件上的误差是0.01%(对于正常邮件来说,这个误差是可以接受的),但是我们倾向于使用BLR算法,因为BLR的计算效率更高。我们接下来应该怎么办?
令SVM的参数为θSVM,BLR的参数为θBLR。其实我们真正在乎的是加权准确率(weighted accuracy):

在上面的例子中,我们有:a(θSVM) > a(θBLR)
BLR的优化目标J(θ)是:
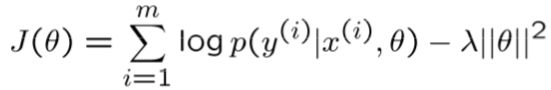
所以我们接下来诊断的方法就是比较J(θSVM)和J(θBLR)的大小。
第一种情况:a(θSVM) > a(θBLR),J(θSVM) > J(θBLR)。BLR的目标是最大化J(θ),但是现在BLR没能做到这点,因此问题在于优化算法,有可能算法还没有达到收敛。
第二种情况:a(θSVM) > a(θBLR),J(θSVM) <= J(θBLR)。BLR确实做到了最大化J(θ),但是BLR的加权准确率不如SVM,因此问题在于优化目标,J(θ)并不能很好地代表a(θ)。
因此回过头来看之前列的改进方式,每个改进方式其实都是在优化某一方面,具体描述如下:
- 增加训练数据:解决高方差
- 尝试更小的特征集合:解决高方差
- 尝试更大的特征集合:解决高偏差
- 尝试改变特征(比如使用邮件的标题和正文部分):解决高偏差
- 增加梯度下降的迭代次数:解决优化算法问题
- 尝试用牛顿方法:解决优化算法问题
- 改变正则化参数λ:解决优化目标问题
- 尝试其他模型,比如SVM:解决优化目标问题
通过对算法进行诊断,我们可以有针对性地提出解决方案,从而避免无意义地进行错误的尝试。
误差分析和销蚀分析
很多机器学习应用中会包含多个组成部分,各个部分之间形成一个整体的“管道(pipeline)”。比如下图展示了一个从图像中进行面部识别的管道图:

那么我们如何知道究竟哪个组件(component)对整体的贡献率最大呢?
我们可以使用两种方法来分析这个问题。第一个方法是误差分析(error analysis),误差分析是指从最基础的模型开始,依次增加一个组件,看每个组件对准确率的提升情况。比如对这个例子来说,我们可以分析如下:
| 组件 | 准确率 |
|---|---|
| 整体系统 | 85% |
| 预处理(去除背景) | 85.1% |
| 面部识别 | 91% |
| 分割眼睛 | 95% |
| 分割鼻子 | 96% |
| 分割嘴巴 | 97% |
| 逻辑回归 | 100% |
由此可见,面部识别和分割眼睛这两个组件对整体的贡献率较大。
第二个方法是销蚀分析(ablative analysis)。销蚀分析的步骤刚好相反,每次从完整系统中去除一个组件,看每个组件对准确率的降低情况。比如在一个垃圾邮件分类系统里,我们可以做如下分析:
| 组件 | 准确率 |
|---|---|
| 整体系统 | 99.9% |
| 拼写检查 | 99.0% |
| 发送方主机特征 | 98.9% |
| 邮件头部特征 | 98.9% |
| 邮件文本解析器特征 | 95% |
| Javascript解析器 | 94.5% |
| 图像特征 | 94% |
由此可见,邮件文本解析器特征极大地提升了准确率,而邮件头部特征则对准确率几乎没有什么帮助。
如何上手一个机器学习问题
通常我们面对一个机器学习问题,可以有如下两种思路:
思路1:仔细设计(Careful design)
- 花较长的时间设计出最好的特征,收集到最好的数据,建造出最好的算法架构
- 实现这个算法并希望它可以成功
- 优点:可能找到更新,更优雅的学习算法;适合用于学术研究
思路2:快速迭代(Build-and-fix)
- 先快速做一个可用版本
- 对算法进行误差分析和诊断,找到优化的方向并进行优化
- 优点:可以更快地将算法应用到实际场景中
另外还有一个建议:在项目的早期阶段,我们通常并不清楚系统每个部分的实现难度,因此我们需要避免进行过早优化(premature optimization)。
总结
- 通过对算法进行诊断,可以帮助我们确定优化方向,从而避免无意义地进行错误的尝试
- 误差分析和销蚀分析可以帮助我们确定一个系统中哪个组件的贡献率最大
- 应用机器学习的两种方法:仔细设计和快速迭代;仔细设计适合用于学术研究,但是要避免过早优化的风险
参考资料
- 斯坦福大学机器学习课CS229讲义 pdf
- 网易公开课:机器学习课程 双语字幕视频