【论文笔记】SeqSLAM、Fast-SeqSLAM 和 Bow、Incremental Bow、DBoW2、ORB-SLAM 论文阅读笔记
此篇博客主要重点关注于在闭环检测领域,利用图像序列进行识别的经典算法SeqSLAM和FAST-SeqSLAM。以及词袋模型的发展历史,从06年提出词袋模型,到08年的增量词袋模型,再到12年的二进制词袋模型,最后到ORB-SLAM中词袋模型的使用。
文章较长,请配合目录使用哦~
文章目录
- 2012-SeqSLAM
- Abstract
- SeqSLAM的优势:
- I. Introduction
- II. BACKGROUND 背景
- III. SEQSLAM 原理部分
- A. Local Best Match(局部最佳匹配)
- B. Localized Sequence Recognition 定位序列识别
- IV. EXPERIMENTAL SETUP实验部分
- A. 数据集
- B. Ground Truth
- C. Image Pre-Processing and Comparison
- E. Template Learning
- G. Parameters参数
- V. RESULTS 结果
- B. PR曲线
- C. Ground Truth Plots
- 2017-Fast-seqSLAM
- 大致流程
- 补充前提知识
- FLANN
- HOG描述子
- 算法实现细节
- 稀疏差异性矩阵
- 序列匹配
- 1) Difference Score
- 2)贪婪运动模型估计
- 总结
- 2006-BOW(Scalable Recognition with a Vocabulary Tree)
- 2008 - A Fast and Incremental Method for Loop-Closure Detection Using Bags of Visual Words
- 摘要
- 导言
- 视觉字典
- 贝叶斯闭环检测
- 投票方案
- 缺点
- 2012-Bags of Binary Words for Fast Place Recognition in Image Sequences
- 实现细节
- 评估
- 正确的回环验证 Correctness Measure
- 参数的选择
- 运行时间
- 缺点
- 优点
- 2015-ORB-SLAM
2012-SeqSLAM
Abstract
our approach calculates the best candidate matching location within every local navigation sequence. Localization is then achieved by recognizing coherent sequences of these “local best matches”. This approach removes the need for global matching performance by the vision front-end – instead it must only pick the best match within any short sequence of images.
关于这段话的深入理解:在每一个局部邻域找一个与当前图像最佳的候选匹配,然后由当前的图像序列,识别出连续的一个最佳候选匹配序列。这个方法不需要通过视觉前端找一个全局最佳匹配,而是仅仅挑选一个图像的短序列作为最佳匹配,即序列与序列之间的匹配。

SeqSLAM的优势:
- 序列与序列之间的匹配。2.能够在不同季节、天气、昼夜等极端感知变化的情况下做到正确的匹配。
I. Introduction
- 视觉(相机)已被成功地用作学习和识别1000公里以内旅途中的地点的主要感觉形态,换句话说就是目前大部分使用相机作为传感器,做位置识别,SLAM回环检测等。
- 许多位置识别技术依赖于feature-finding算法,如SIFT[9]和SURF[10],尽管它们具有令人印象深刻的旋转和尺度不变特性,但在处理极端感知变化时本质上不合适。
II. BACKGROUND 背景
RatSLAM已经在一个长期的送货机器人实验中展示了它对一个郊区道路网[17]的视觉映射。RatSLAM 通过对序列而不是单个位置进行定位,消除了对完美数据关联或特征检测的要求。事实上,在不进行传统特征提取的情况下,仅使用低分辨率视觉感官输入(通常约为1000像素[19])和图像强度轮廓等轻量级预处理技术,就可以获得显著的实验结果。但是白天绘制的道路网络在晚上无法被系统识别。
我们的方法也使用序列,但放弃使用特征,而是使用整个图像
III. SEQSLAM 原理部分
A. Local Best Match(局部最佳匹配)
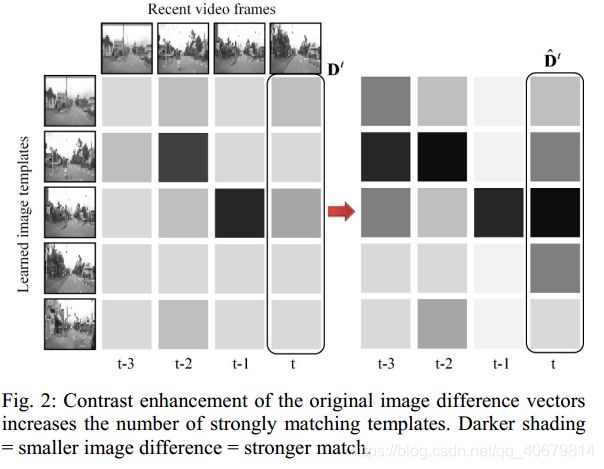
这里的意思是:此方法不在像之前的方法那样,在全局中去找与当前图像最匹配的一个候选帧(single template),而是,在每一个局部领域中去找一个候选帧template,那么数据集中可以分出来好多个局部领域,则就要好多个template组成了templates,也就组成了上图最左边一列的图像。
结合全文的详解:
这里使用了(SAD)匹配器对将分辨率的图像进行操作。Di就是图二中的一个小方块,i代表是左边第一例中第i个候选帧。
【SAD匹配参考链接:https://blog.csdn.net/liulina603/article/details/53302168】

其中,Rx、Ry为图像patch的维度,p为图像像素强度值。在每个时刻t,将当前的图像帧template与每个学习过的模板template进行比较,得到一个图像差分向量Dt,如图2左侧所示。注意,Dt由图像差异组成,值越低(越负),匹配越好。
B. Localized Sequence Recognition 定位序列识别
先构建一个差异性(两图像的相加)矩阵,在匀速运动的假设下,在差异性矩阵上搜寻一个最佳路径,该路径使得总差异性最小,下图展示了这样一个搜寻过程,图中不同斜率的直线代表了不同的速度模型。图3中就是一个差异性矩阵,正如在图2中描述的一样,每一列代表Dt,共有ds列,从D(T-ds)到D(T)。(这里我比较迷惑的一点是如何确定起点s:(更新)看了fast-seqslam后,决定这里的s是遍历来的的,就是说需要从数据集的第一个局部领域开始作为原点,然后第二个,第三个…)
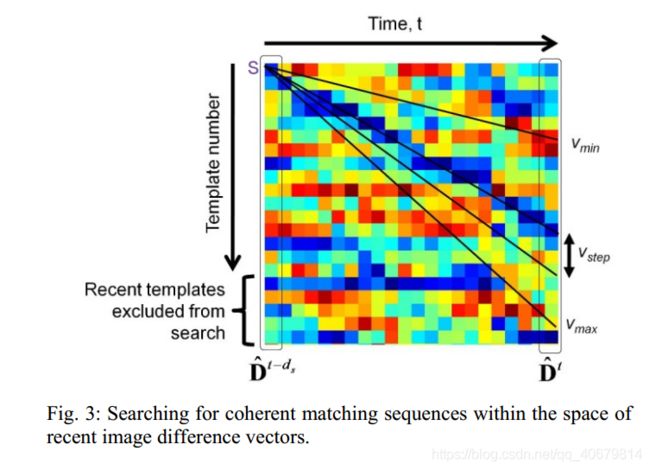
每一条轨迹有一个得分:

不同的曲线,代表着不同的速率,间接也代表了所匹配上的template数,例如速度越快,template越多,根据不同的轨迹的得分画出了下图,每一个点代表一条曲线的得分。判断是否该轨迹是匹配上的回环的方法是:如果在在Rwindow内取得最低分数的轨迹,小于其他轨迹的分数的µ倍,就认为出现了正确的匹配。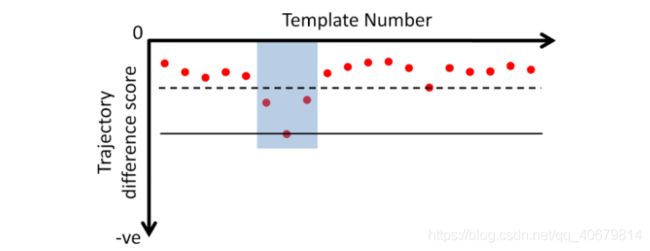
IV. EXPERIMENTAL SETUP实验部分
A. 数据集
有两个数据集,每个数据集在相同环境下跑两圈,这两个数据集都涉及了不同的交通状况、停车状况,以及由于基础设施的变化和停车车辆的移动而带来的额外感知变化。第一个数据集包含两个来自德国著名的22公里纽博格林赛道一圈的车载摄像机视频。帧率:30;大小: 640×480;特征:在一年的不同时期拍摄的,轨迹如Fig6(a)所示。第二个数据集包含两个8公里的旅程,穿越澳大利亚布里斯班的Alderley郊区。帧率:50,大小:640*256,特征:在暴风雨的深夜和晴朗的白天分别拍摄,轨迹如图6(b)所示。

B. Ground Truth
为了获得Ground Truth,所有视频都是逐帧手动解析的,关键帧使用谷歌地图的组合标记它们的纬度和经度。
第一个数据集被标注了236个location,第二个数据集被标注了182个数据集。
C. Image Pre-Processing and Comparison
裁剪后的图像首先转换为灰度,然后下采样,总分辨率为2048 (Alderley)和1024 (Nurburgring)像素,使用OpenCV提供的像素区域重采样技术,以避免云纹干涉模式。保持了原始视频帧的近似高宽比。向下采样后,将图像分割成边长为P的较小的正方形区域,然后对这些区域进行patch归一化处理,如图7e所示。

E. Template Learning
template以每帧处理Vav个模板的固定速率学习。对于本文中描述的实验,我们发现Vav = 0.5(即从两个原始帧学习一个template)的值给出了很好的结果——唯一的折衷是计算速度。由于图像冗余严重,我们每4个原始视频帧只处理1个,因此每8个原始视频帧(8=2*4)需要学习一个模板。为了减少相机静止时学习的模板数量,只在相机明显移动时才处理帧。通过将帧比较算法应用于当前帧和之前标记帧的帧flag来检测静止摄像机周期。
这里讲的应该是:给出了如何确定局部最佳匹配中局部的范围,即8个帧学习出一个template。
G. Parameters参数

关于Rrecent:为了避免与当前的轨迹匹配,在除了当前模板的Rrecent中最近学习的模板之外,对每个模板执行轨迹搜索。
关于Rwindow和系数µ:如果最低Score轨迹的滑动窗口范围Rwindow内小于任何轨迹的窗外的µ倍,则认为这个轨迹是一个匹配。
V. RESULTS 结果
当前的实现没有内建优化,因此计算规模与数据集的长度成线性关系。
A. 样本图像序列匹配


B. PR曲线
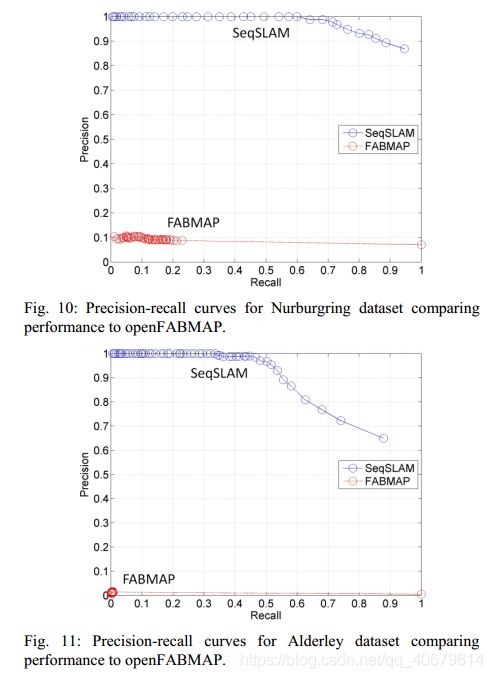
PR曲线 随着µ的改变而生成,之前指出只有在Rwindow内取得最低分数的轨迹,小于其他轨迹的分数的µ倍,才被认定出现了回环,那么如果µ变大,则判断为回环的条件就变严格了,则从而剔除了假阳性,慢慢使得准确率变为100%。
那么如何判断这个轨迹是否被正确匹配了呢?对每一个与当前轨迹序列匹配的学习轨迹序列,将其中点对应的Ground-truth值位置与当前轨迹中点的地面真值位置进行比较,超过40米的度量误差被指定为两个数据集的假阳性。从这里可以很清楚的看出SeqSlam是序列与序列之间的匹配而不是普通的图像与图像之间的匹配,但是我有一个问题是如何确定从D(T-ds)开始匹配起始原点,之后看懂了再来补。
下图是SeqSLAM和OpenFABMAP的比较,可以看出基于特征的方法很难在任何recall level上正确地回忆多帧。
这里思考一个问题:在很低的recall下,precision也很低是什么样子的,就说明TP就很低,也就是正确匹配回环的数量就很少很少。
C. Ground Truth Plots
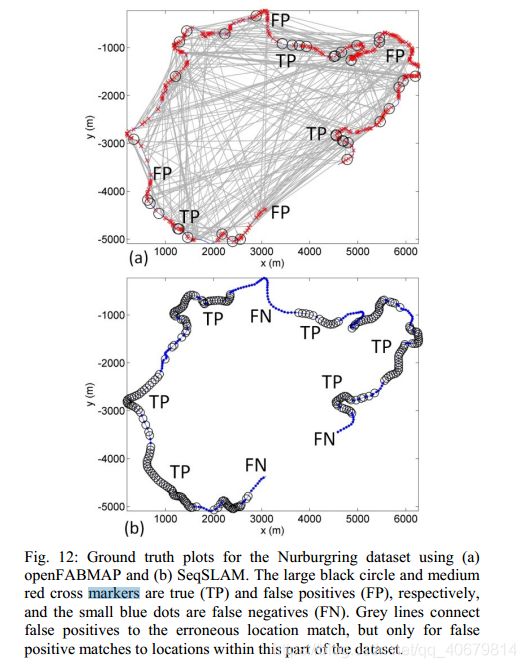
一些SeqSLAM的假阴性(FN)可能是由于缺乏运动模型和假设在轨迹段上匀速运动造成的。如下图a所示是FAB-MAP的结果,b是SeqSLAM的结果,其中大黑圈是TP,红色小叉是FP,蓝点是FN
2017-Fast-seqSLAM
SeqSLAM缺点:严重依赖于穷举序列匹配,这是一种计算开销很大的过程,会妨碍算法用于处理大型地图,因此提出了Fast-SeqSLAM。
Fast-SeqSLAM降低了时间复杂度而不降低精度,这是通过使用一个近似最近邻(ANN)算法来匹配当前图像与机器人地图,并且拓展了SeqSLAM去贪婪的搜索一个与当前图像序列最匹配的序列的思想。
大致流程
- 使用ANN算法为当前输入图像搜索出N个最近邻
- 只计算N个最近邻与当前图像的距离,(不是像SeqSLAM那样计算当前图像和所有templates的差异值)从而组成稀疏差异性矩阵。
- 修改SeqSLAM的算法,我们不像原来的SeqSLAM算法那样进行详尽的搜索;相反,我们贪婪地只从地图中K个与机器人当前视图最匹配的位置搜索,K小于N。
- 最终,由于算法的有效性,算法复杂度从O(n^2)降到O(nlogn)
补充前提知识
FLANN
链接:https://blog.csdn.net/qq_36387683/article/details/80578480
注意,这篇文章实际讲的是几种k-d树,其实上ANN的方法分为三大类:基于树的方法、哈希方法、矢量量化方法。brute-force搜索的方式是在全空间进行搜索,为了加快查找的速度,几乎所有的ANN方法都是通过对全空间分割,将其分割成很多小的子空间,在搜索的时候,通过某种方式,快速锁定在某一(几)子空间,然后在该(几个)子空间里做遍历。而FLANN为给定数据集和目标精度自动选择ANN参数
文中指出这里的FLANN可以使用随机k-d树,也可以使用层次化的k-d树。
对于数据维度从10到10^3、目标精度为80%的数据,速度提高了 10 ^ 3倍。在我们的研究中,图像描述符的尺寸小于1024。
HOG描述子
链接:https://blog.csdn.net/u011665459/article/details/60575107(这篇翻译的蛮清楚的)
算法实现细节
稀疏差异性矩阵
我们将差分矩阵初始化为较大的值(图1中明亮的单元格)。我们使用FLANN创建一个树结构来存储地图图像描述符,以便于高效搜索。对于一个地图或遍历n个图像,在O(log(n))时间复杂度内,每个图像都可以在图像中找到它n个最近邻,而在线性搜索的情况下,则需要O(n)时间复杂度。ANN算法返回的距离值用于替换初始值(图1中为N=2),因此,我们的差分矩阵是稀疏的,每个列(行)都包含(近似)N个最近邻的距离。

序列匹配
我们只计算地图中K个与机器人当前视图最匹配的位置的最小差值,而我们总共有N个匹配位置(算法1第10行)。
N决定了差分矩阵的近似值。
然后利用机器人的当前速度更新机器人的当前位置,选择最短序列路径间接就得到了当前速度。
我们更新了机器人的位置,使得两个序列之间的闭环节点在时间上是连续的。、
== 这里存在一个问题怎么确定是哪K个?==
1) Difference Score
计算得分和SeqSLAM基本相同,就是好像方向不一样了,都是将轨迹上的差分值相加起来
2)贪婪运动模型估计
每一条轨迹代码不同速度,不同的运动模型,具有最小分数的轨迹是最合适的,只有当最合适的轨迹线至少有一个最近的邻居时,我们才会更新机器人的当前位置,也相当于确定这是一个回环。
总结
可以看出Fast-SeqSLAM主要在于关注算法的执行效率,它应用了一个高效的搜索结构——FLANN(可以用随机k-d树,或者层次化的k-d树),放进树结构的是用32*32patch提取的HOG特征;其次它应用了贪婪搜索去做序列匹配,依我自己的理解是,它首先是选定了起点,减少了搜素次数,然后还利用当前的速度更新位置,进一步提升速度。
2006-BOW(Scalable Recognition with a Vocabulary Tree)
这篇文章叙述的方法与《视觉SLAM十四讲》中的方法基本一致, 定义了一个使用k-means聚类的k叉树,设树的深度为L,则可能到k^L个单词,对于在线的输入图像,要找到它的单词只需通过KL次比较(因为每一层比较k次,然后进入该节点的子节点也是k个)。
此该篇文章使用的单词权重是TF-IDF中的IDF(因为说感觉TF没什么用),需要注意的是这个是用来计算:从数据库所有图像中提取的单词的权重(也就是查询图像q和数据库图像d共用这个权重w,不同的是对于单词i,q(i)=n(i)w(i) ,d(i)=m(i)w(i) ,其中n(i)和m(i)是q和d图像中在单词i中所包含的描述子的个数)
文中也采用了倒排索引**,做的改进是:剔除那些单词队列里面长度过长和过短的单词(这些单词对于检索往往是没有什么用的)
最后的相似度计算采用了一个可自定义的公式:
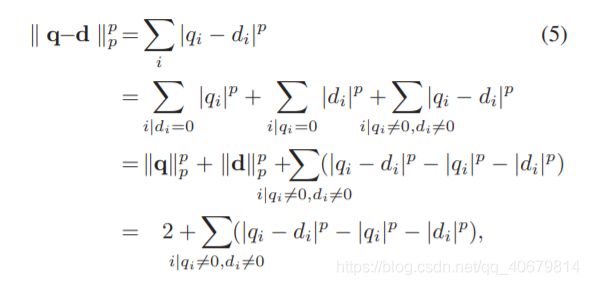
当p取2时:

2008 - A Fast and Incremental Method for Loop-Closure Detection Using Bags of Visual Words
摘要
- 主要创新点:使用了局部形状和颜色信息。
- 具体实施方案:该方法将图像分类中的词袋法扩展到增量条件下,并利用贝叶斯滤波估计闭环概率。
- 最后取得的效果:可以解决不管是在室内还是室外图像序列中,强烈感知偏差的环境条件的下的实时闭环检测。
导言
the loop-closure detection issue concerns the difficulty of recognizing already mapped areas, while the global localization issue concerns the difficulty of retrieving the robot’s location in an existing map
译:闭环检测关注的是如何识别出从已经在地图里面的区域,而全局定位主要关注于检索机器人的位置在已经存在的地图中。
Such task bears strong similarities with image classification methods like those described in [8] and [9], but an important difference is our commitment to online processing.
译:像这样的工作和图像分类非常相似,只不过我们最重要的不同是我们是在线处理。
工作:
1.在贝叶斯滤波的方案下,提出了一种基于视觉的闭环检测系统:当一个查询图像输入时,我们计算它在来自于已经存在的概率。
2. 设计了一种场景识别框架,基于增量版本的视觉词袋思想。
3. 几何验证是:在回环检测假设的概率高于某一个阈值时,判断是否在对应图像对中有一致相关的结构,例如满足几何极线的关系。
指出目前工作存在的问题:
1.一些回环检测系统只能用于特定SLAM系统、
2. 还有一些不能用于有强烈感知偏差的场景
3. 使用BoW的大多数方法都使用NN搜索来检索当前查询图像词袋向量和数据库图像词袋向量,这样花销太大。
依据:
例如,正如[19]中所述,颜色直方图是一种强大的特性,它提供了一种紧凑的无几何图像表示,对视点变化显示出一些有吸引力的不变性。
因此,为了在不同的上下文中获得可靠的解决方案,可以合并多个互补的视觉信息,例如形状和颜色。
视觉字典
增量的意义:
字典的构建与图像采集一起在线执行,以增量方式进行。
使用两个颜色空间:
1.SIFT 特征。描述子128维,使用L2距离比较。
2. 局部颜色直方图。为了提升视角不变性,把图片划分为几个为小块。描述符为16维,用扩散距离进行比较。
颜色直方图参考链接:https://blog.csdn.net/sunbin0123/article/details/42240791
颜色直方图和Gist类似,只是将划分bins的方法从角度换成了HSV颜色空间(或者其他颜色空间)中的颜色量化值。
贝叶斯闭环检测
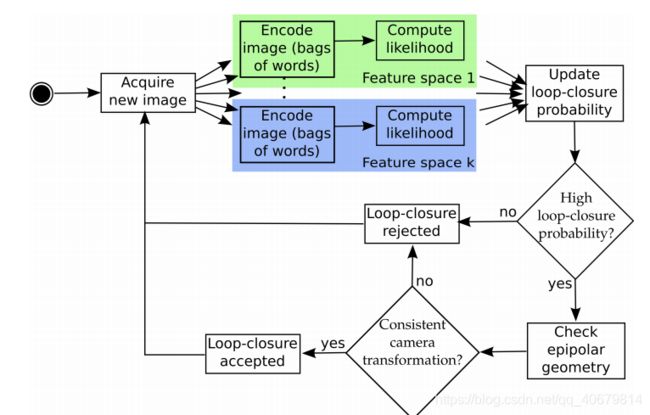
上图是此篇文章的结构流程图:
- 提取两个特征空间中的图像信息,进行计算似然,得到回环概率。这里利用的贝叶斯滤波的方法,得到的是当前查询图像和之间数据库所有图像是隶属同一个场景的概率,主要利用了信息的时间一致性,使得系统更加鲁棒。
- 如果找到这样一张图片,它和当前图像的似然概率高于某一个阈值,也许找不到峰值,但是我们可以找邻域对应领域的和最大的候选帧,进入几何验证的阶段,采用RANSAC剔除误匹配,如果成功,算法返回xt和xi之间的3D变换(即与它和Ii相关的视点),假设被接受。否则,假设就被抛弃了,这可以很好的解决感知偏差的问题。
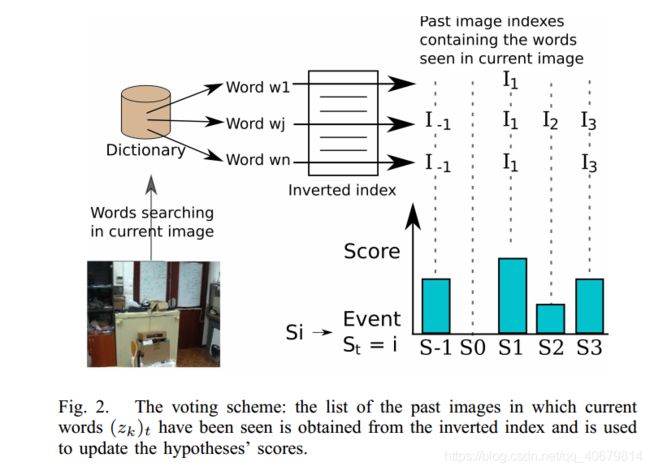
投票方案
缺点
- 关注点在解决严重感知偏差问题,而测试的数据都是用的光照条件不变的数据集,且由于它使用的是SIFT和颜色直方图,具有旋转和尺度不变性,有很好的pose-invariance但是没有condition-invariance,就是可能对于光照变化敏感。
2012-Bags of Binary Words for Fast Place Recognition in Image Sequences
ORB-slam中使用的位置识别算法,主要优点在于二进制特征对于计算速度的优化。
主要参考翻译文章:https://blog.csdn.net/zhaodeming000/article/details/100165041
以下做一些总结:
- 此方法建立在词袋和几何验证的基础上,其主要的速度改善来源在于对带FAST关键点的BRIEF描述子的简单修改 。
- 引入词袋离散化二进制空间,利用正索引扩充词袋,派出通常的逆索引。这是第一次利用二进制词汇表进行回环检测。
- 为了确定一个循环已经被关闭,我们验证了所获得的图像匹配的时间一致性,提出了一种在查询数据库时防止在同一位置采集的图像相互竞争的技术。我们通过将那些在匹配期间描绘相同位置的图像分组来实现这一点。
实现细节
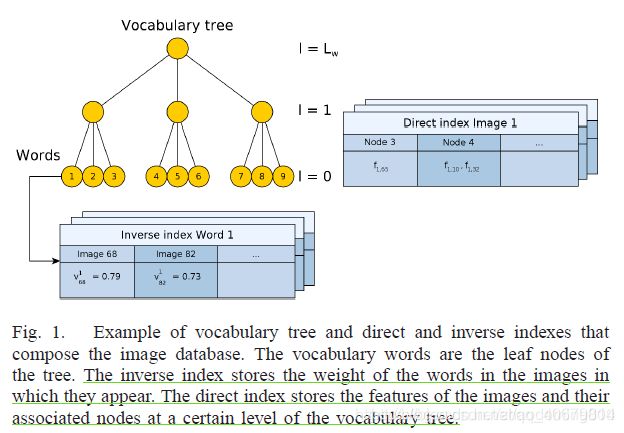
文中的词袋模型包括:词汇树,倒序索引,直接索引。
其中词汇树和倒序索引是普通的BOW中的,而直接索引是此篇文章的创新点,目的是为了在之后的几何验证阶段加快速度,只搜索同个单词的特征或者,有相同父节点的特征。而直接索引由图像数据库中的图像It,从叶子节点遍历词汇树。将特征放入对应遍历到的节点中,就组成了{节点->特征}的数据对。
这里的回环检测包括四个步骤:
A. 计算归一化的相似度指标n

B.计算matching group,就是把时间上相似的图像作为一组,以防止相似图像对查询图像产生竞争,选择H值最大的分组。

C.验证时间一致性,要查询图像的前几张图片都和候选匹配组的前几个组一致,使得组之间的时间间隔尽可能的小。
D.验证几何一致性,要想使用RANSAC基本矩阵,需要找到至少12个特征对应关系,这里利用直接索引,对不同层次下在同一个节点中的特征集合做比较,在此特征集合中找到最近邻,建立对应关系,再使用RANSAC。
RANSAC具体实施:
对当前帧和回环候选帧的匹配对进行RANSAC,用我们前面所介绍的方法计算相对位姿,然后提出外点;
最后根据内点数量与阈值条件,确定最终的回环帧;
评估
正确的回环验证 Correctness Measure
A match fired by the loop detector is a pair of query and matching timestamps. To check if it is a true positive, the ground truth is searched for an interval that contains these timestamps. The number of loop events in the ground truth is computed as the length of all the query intervals in the ground truth multiplied by the frequency at which the images of the dataset are processed.
关于查找查询输入图片真正的Ground-truth:把一对匹配图像的时间戳放入列表中,在这个列表中搜索包含这个时戳的元素。
参数的选择
把数据集分为两部分,一部分用于做训练,以确定模型的参数;另一部分用来做验证,评估模型的性能。
运行时间
越大的数据库,越是要使用越多的单词,这样可以大大提升运行时间,因为大量的单词可以使倒排索引的向量更加稀疏。
缺点
1.不能处理大视角变化的场景,这是由于提取的BRIEF特征的本质所引起的,它并不是尺度和旋转不变性的描述子,但是在ORB特征中对此方法做了改进可以实现尺度和选择不变性。
2.对于回环匹配图像和其他图像存在很大差别的数据集,不能表现的很好(可能说的就是上面的第一点)。
优点
1.速度快,毋庸置疑
2.场景中就算物体发生了变化,但是只要背景匹配上了,依旧可以检测出回环,就像是马路上一直有动态的车经过。
2015-ORB-SLAM
可参考链接:https://www.jianshu.com/p/4ce54743a4b4(文章翻译)
https://www.cnblogs.com/yepeichu/p/10793013.html (这篇讲的很清楚的回环检测的外观验证的流程)
https://www.cnblogs.com/yepeichu/p/10816825.html (这篇讲的很清楚的回环检测的几何验证的流程)
此章重点关注ORB-SLAM的闭环检测。
首先它是使用了ORB算子做追踪,闭环检测等等,
其次参考了2012的BOW2,且使用了covisibility 信息,当查询一个图像时返回几个假设(候选帧)而不是只返回一个最佳匹配。
ORBSLAM2都是在不断提高筛选条件进而缩小候选帧集。利用词袋模型检索和匹配效率极高的优势,快速完成粗检索,精细化的部分再交由几何验证去进一步确定最终的候选帧。
A、候选关键帧
我们先计算Ki的词袋向量和它在covisibility graph中相邻图像(θmin=30)的相似度,保留最低分值Smin。然后,我们检索图像识别数据库,丢掉那些分值低于Smin的关键帧。这和DBoW2中均值化分值的操作类似,可以获得好的鲁棒性,DBoW2中计算的是前一帧图像,而我们是使用的covisibility信息。另外,所有连接到Ki的关键帧都会从结果中删除。为了获得候选回环,我们必须检测3个一致的候选回(covisibility graph中相连的关键帧)。如果对Ki来说环境样子都差不多,就可能有几个候选回环。
B、计算相似变换
单目SLAM系统有7个自由度,3个平移,3个旋转,1个尺度因子 [6]。因此,闭合回环,我们需要计算从当前关键帧Ki到回环关键帧Kl的相似变换,以获得回环的累积误差。计算相似变换也可以作为回环的几何验证。
我们先计算ORB特征关联的当前关键帧的地图云点和回环候选关键帧的对应关系,具体步骤如第3部分E节所示。此时,对每个候选回环,我们有了一个3D到3D的对应关系。我们对每个候选回环执行RANSAC迭代,通过Horn方法(如论文[42])找到相似变换。如果我们用足够的有效数据找到相似变换Sil,我们就可以优化它,并搜索更多的对应关系。如果Sil有足够的有效数据,我们再优化它,直到Kl回环被接受。
读ORB-SLAM闭环检测模块的一些感悟:
首先创新点在于:结合covisibility graph的信息,对候选帧的严格筛选,一步步提高对候选帧的要求,得到最终的F(final)。
然后再进入几何验证过程,同样也是层层筛选:先进行特征匹配;再对当前帧和回环候选帧的匹配对进行RANSAC,计算相对位姿,剔除外点;利用双向优化方法根据阈值条件筛选内点;执行了多次迭代的优化,从而最终确定内点数量;根据内点数量与阈值条件,确定最终的回环帧;利用回环帧的共视图构建局部地图点,通过估算的相对位姿进行重投影匹配,确定匹配数量;根据匹配数量,确定回环检测的结果。