darknet用自己的数据进行训练
根据之前博客的内容自行收集训练数据集已经成功收集了一波标注好的数据,现在尝试利用自己的数据对yolo v2模型进行训练。
1.处理数据
由于自己的数据是pascal格式的,需要转换为darknet需要的格式,不必惊慌,官方给出了脚本,自己只需稍作修改(因为pascal格式运用较广,一般的模型框架及时不能使用pascal,也会给出pascal的转换脚本)
利用以下脚本生成train.txt(由于我的数据集不是很充足,就没有细分为训练集和验证集,而是全部作为训练集,所以没有生成val.txt,如有需要的可以适当修改代码)
#!/usr/bin/env python2
# -*- coding: utf-8 -*-
"""
Created on Wed Jul 12 17:50:26 2017
@author: seven
"""
import os
from os import listdir, getcwd
from os.path import join
if __name__ == '__main__':
source_folder='/home/seven/darknet/infrared/plate/image/'#地址是所有图片的保存地点
dest='/home/seven/darknet/infrared/train.txt' #保存train.txt的地址
file_list=os.listdir(source_folder) #赋值图片所在文件夹的文件列表
train_file=open(dest,'a') #打开文件
for file_obj in file_list: #访问文件列表中的每一个文件
file_path=os.path.join(source_folder,file_obj)
file_name,file_extend=os.path.splitext(file_obj)
#file_name 保存文件的名字,file_extend保存文件扩展名
file_num=int(file_name)
train_file.write(file_name+'\n')
train_file.close()#关闭文件生成的train.txt包含着训练集每一张图片的文件名,之后利用train.txt通过下面的脚本生成每个图像对应的(图像名).txt文件和infrared_train.txt文件。(图像名).txt文件中包含着图像中目标的位置和类别标签,infrared_train.txt文件中包含着每个图片的完整路径。
#!/usr/bin/env python2
# -*- coding: utf-8 -*-
"""
Created on Wed Jul 12 17:50:26 2017
@author: seven
"""
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
classes = ["plate"]#类别改为自己需要检测的所有类别
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_id):
in_file = open('/home/seven/darknet/infrared/plate/xml/%s.xml'%(image_id))#与图片对应的xml文件所在的地址
out_file = open('/home/seven/darknet/infrared/plate/txt/%s.txt'%(image_id),'w') #与此xml对应的转换后的txt,这个txt的保存完整路径
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size') #访问size标签的数据
w = int(size.find('width').text)#读取size标签中宽度的数据
h = int(size.find('height').text)#读取size标签中高度的数据
for obj in root.iter('object'):
# difficult = obj.find('difficult').text #没设difficult,所以屏蔽
cls = obj.find('name').text
if cls not in classes :#or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox') #访问boundbox标签的数据并进行处理,都按yolo自带的代码来,没有改动
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
image_ids = open('/home/seven/darknet/infrared/train.txt').read().strip().split()
list_file = open('/home/seven/darknet/infrared/infrared_train.txt', 'w')
for image_id in image_ids:
list_file.write('/home/seven/darknet/infrared/plate/image/%s.jpg\n'%(image_id)) #把每一用于训练或验证的图片的完整的路径写入到infrared_train.txt中 这个文件会被voc.data yolo.c调用
convert_annotation(image_id) #把图片的名称id传给函数,用于把此图片对应的xml中的数据转换成yolo要求的txt格式
list_file.close() #关闭文件至此,我们成功生成了一个文件夹的(图片名).txt文件和一个infrared_train.txt文件。将那一个文件夹的(图片名).txt文件复制到图片所在的文件夹中,对我而言为’/home/seven/darknet/infrared/plate/image’。
2.修改文档及代码
(1)修改.names
将data文件夹中的voc.names中的类别改为自己要检测的类,或新建一个.names 文件,在其中写上自己的类别。比如,我新建了plate.names文件,并在其中第一行写上plate。
(2)修改voc.data
打开cfg文件夹中的voc.data,将class修改为自己要识别的类别数,train为生成的infrared_train.txt的路径,valid为生成的infrared_val.txt(如不用测试集测试,可忽略),names修改为刚才修改的.names路径,backup设为darknet下的backup文件夹就好。我的设置如下:
classes= 1
train = /home/seven/darknet/infrared/infrared_train.txt
valid = /home/seven/darknet/infrared/infrared_val.txt
names = data/plate.names
backup = /home/seven/darknet/backup
(3)修改cfg文件
由于我使用的是tiny-yolo,所以我对tiny-yolo-voc.cfg进行修改(如使用yolo,可修改yolo-voc.2.0.cfg,修改方法一样)。batch和subdivisions可根据自己的内存大小修改,我使用默认的64和8。在文件的末尾位置找到classes,修改为classes=(你的类别数),并修改【region】上方两行的filter,计算公式为(classes+ coords+ 1)* (num)变量均在【region】中定义,我的为(1+4+1)×5=30。至于学习率之类的可以自行调整。
(4)修改.c文件
example文件夹中的yolo.c:
a.将开头的voc_names[]修改为自己的检测类别,如:char *voc_names[] = {"plate"};
b.将train_yolo中的的train_images和backup_directory改为自己的路径,如:
char *train_images = "/home/seven/darknet/infrared/infrared_train.txt";
char *backup_directory = "/home/seven/darknet/backup";c.将validate_yolo和valadate_yolo_recall的base和plist作如下修改:
char *base = "/home/seven/darknet/results/comp4_det_test_";
list *plist = get_paths("/home/seven/darknet/infrared/infrared_val.txt");d.将315行的draw_detection函数参数中的20改为自己的类别数,如draw_detections(im, l.side*l.side*l.n, thresh, boxes, probs, voc_names, alphabet, 1);
e.将348行的demo函数修改参数为自己的类别数:demo(cfg, weights, thresh, cam_index, filename, voc_names, 1, frame_skip, prefix, avg, .5, 0,0,0,0);
example文件夹中的detector.c:
511行的plist改为infrared_val.txt(若不需测试验证,可不修改)
(5)修改voc_label.py
将scripts文件夹中的classes改为自己的类别(感觉没用,以防万一的修改)
3.下载预训练模型
进入https://pjreddie.com/darknet/yolo/选取适合自己的预训练模型,如图,我选择tiny-yolo
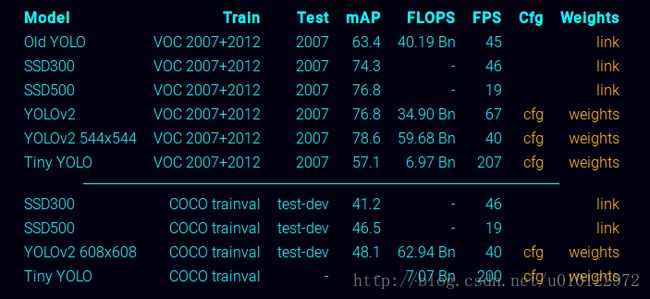
训练好的模型放在darknet文件夹根目录
4.开始训练
终端进入darknet根目录,输入下列命令
./darknet detector train cfg/voc.data cfg/yolo_voc.cfg tiny-yolo-voc.weights搞定收工!
(如果编译选择使用opencv,可能报错,终端在darknet根目录,输入make clean,然后修改makefile中的opencv=0,保存后退出,重新make,然后再输入上面的命令就好。
5.功能扩充
(1)测试:
可以用一下命令行
./darknet detector test cfg/voc.data cfg/yolo_voc.cfg backup/(文件名).weights 图像路径(如data/dog.jpg)(2)评估:
训练完后可以用测试机对模型进行评估(需要按照上面所述的生成infrared_val.txt),命令为:
./darknet detector recall cfg/voc.data cfg/yolo_voc.cfg backup/(文件名).weights选择backup中生成的.weights文件。