caffe表情识别(一):准备数据fer2013
- 官网下载
- 百度云下载(提取密码: 9f05)
下载fer2013之后,解压出的是csv格式的数据,我们需要先将数据转换成图片。

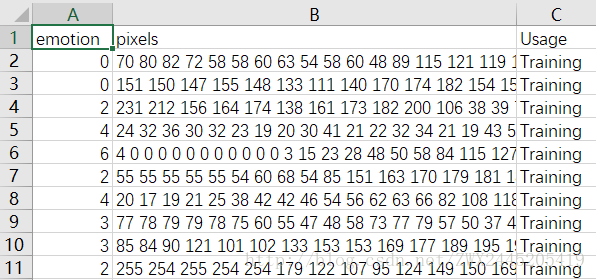
step 1: 从fer2013.csv中提取出训练集、验证集和测试集

convert_fer2013.py:
# -*- coding: utf-8 -*-
import csv
import os
database_path = r'F:\Datasets\fer2013'
datasets_path = r'.\datasets'
csv_file = os.path.join(database_path, 'fer2013.csv')
train_csv = os.path.join(datasets_path, 'train.csv')
val_csv = os.path.join(datasets_path, 'val.csv')
test_csv = os.path.join(datasets_path, 'test.csv')
with open(csv_file) as f:
csvr = csv.reader(f)
header = next(csvr)
rows = [row for row in csvr]
trn = [row[:-1] for row in rows if row[-1] == 'Training']
csv.writer(open(train_csv, 'w+'), lineterminator='\n').writerows([header[:-1]] + trn)
print(len(trn))
val = [row[:-1] for row in rows if row[-1] == 'PublicTest']
csv.writer(open(val_csv, 'w+'), lineterminator='\n').writerows([header[:-1]] + val)
print(len(val))
tst = [row[:-1] for row in rows if row[-1] == 'PrivateTest']
csv.writer(open(test_csv, 'w+'), lineterminator='\n').writerows([header[:-1]] + tst)
print(len(tst))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
注意:在Windows平台中,需要在csv.writer()中加上lineterminator='\n'不然在生存的csv文件中,每行之间会有空行,影响后续操作。在Linux平台中不需要这样做。
step 2: 将csv中的数据转化成图片
![]()
convert_csv2gray:
# -*- coding: utf-8 -*-
import csv
import os
from PIL import Image
import numpy as np
datasets_path = r'.\datasets'
train_csv = os.path.join(datasets_path, 'train.csv')
val_csv = os.path.join(datasets_path, 'val.csv')
test_csv = os.path.join(datasets_path, 'test.csv')
train_set = os.path.join(datasets_path, 'train')
val_set = os.path.join(datasets_path, 'val')
test_set = os.path.join(datasets_path, 'test')
for save_path, csv_file in [(train_set, train_csv), (val_set, val_csv), (test_set, test_csv)]:
if not os.path.exists(save_path):
os.makedirs(save_path)
num = 1
with open(csv_file) as f:
csvr = csv.reader(f)
header = next(csvr)
for i, (label, pixel) in enumerate(csvr):
pixel = np.asarray([float(p) for p in pixel.split()]).reshape(48, 48)
subfolder = os.path.join(save_path, label)
if not os.path.exists(subfolder):
os.makedirs(subfolder)
im = Image.fromarray(pixel).convert('L')
image_name = os.path.join(subfolder, '{:05d}.jpg'.format(i))
print(image_name)
im.save(image_name)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
生成的数据集目录结构如下:

- A Real-time Facial Expression Recongnizer using Deep Neural Network
- Touchy Feely: An Emotion Recognition Challenge
第一篇文献中有网络结构图,但根据我做实验的情况来看,这篇论文水分较大,达不到论文中所说的分类精度。第二篇内容比第一篇详细很多,很值得参考。
训练结果:
