DRF三 ------ 序列化
序列化
- DRF普通序列化(了解一下就行)
- 先创建模型类
- 然后再序列化
- 普通序列化里面的参数约束
- 用终端传数据
- 查数据
- DRF模型序列化(继承ModelSerializer)
- 模型类
- 序列化
- 视图(增加数据的视图)
- 路由
- 更新删除视图
- drf模型序列化高级一
- 模型类
- 序列化
- 视图
- 路由
- DRF高级序列二(基于序列化)
- StringRelatedField(和模型类的str配合使用,返回名字)
- PrimaryKeyRelatedField(显示对应模型的id)
- HyperlinkedRelatedField(在关联的模型中返回超链接)
- SlugRelatedField(可以返回对应模型的任何一个字段)
- HyperlinkedIdentityField(返回对应模型 视图的超链接)
- HyperlinkedModelSerializer(返回超链接)
- 嵌套序列化关系模型(常用)
- depth
- SerializerMethodField(自定义对应模型的属性)
- source
- to_representation
DRF普通序列化(了解一下就行)
重新创建一个新的应用
python manage.py startapp app02
创建完应用之后,要记得注册应用

先创建模型类
from django.db import models
# Create your models here.
class Article(models.Model):
title = models.CharField(verbose_name='标题', max_length=100)
vum = models.IntegerField(verbose_name='浏览量')
content = models.TextField(verbose_name='内容')
然后再序列化
先在app02下创建一个序列化文件serializers.py
在drf中,每一个模型都可以序列化
from rest_framework import serializers
#导入最开始的序列化
from .models import Article
#导入模型类
class ArticleSerializer(serializers.Serializer):
#在最普通的序列化里面,要序列化的字段、还有下面的两个方法都需要手打出来,得自己写
id = serializers.IntegerField(read_only=True)
vum = serializers.IntegerField()
content = serializers.CharField(max_length=1000)
title = serializers.CharField(required=True, max_length=100)
def create(self, validated_data):
return Article.objects.create(**validated_data)
def update(self, instance, validated_data):
instance.title = validated_data.get('title', instance.title)
#instance.title就是说,没有取到的话,就用原来的数据
instance.vum = validated_data.get('vum', instance.vum)
instance.content = validated_data.get('content', instance.content)
instance.save()
#创建序列化器对象的时候,如果没有传递instance实例,则调用save()方法的时候,create()被调用,
# 相反,如果传递了instance实例,则调用save()方法的时候,update()被调用。
return instance
之后就开始迁移文件,生成表
python manage.py makemigrations
python manage.py migrate
普通序列化里面的参数约束
read_only:True表示不允许用户自己上传,只能用于api的输出。
write_only: 与read_only对应
required: 顾名思义,就是这个字段是否必填。
allow_null/allow_blank:是否允许为NULL/空 。
error_messages:出错时,前端的信息提示。
name = serializers.CharField(required=True, min_length=6,
error_messages={
‘min_length’: ‘名字不能小于6个字符’,
‘required’: ‘请填写名字’})
label: 字段显示设置,如 label=’验证码’
help_text: 在指定字段增加一些提示文字,这两个字段作用于api页面比较有用
style: 说明字段的类型,这样看可能比较抽象,看下面例子:
#在api页面,输入密码就会以*显示
password = serializers.CharField(
style={‘input_type’: ‘password’})
#会显示选项框
color_channel = serializers.ChoiceField(
choices=[‘red’, ‘green’, ‘blue’],
style={‘base_template’: ‘radio.html’})
validators:自定义验证逻辑
用终端传数据
可以在pycharm自带的数据库里面传数据,也可以在终端传入数据
这里采用终端传入数据
python manage.py shell 打开终端
from app02.serializers import ArticleSerializer 导入模型类
from rest_framework.renderers import JSONRenderer 可以生成json数据的包
然后开始创建数据(也就是反序列化)
反序列化的关键字是data
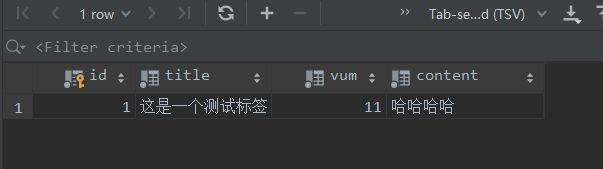
d = {"title":"这是一个测试标签","vum":11,"content":"哈哈哈哈"}
ser = ArticleSerializer(data=d)
ser.is_valid()# 验证数据是否正确,传的时候如果少一个字段,会返回false
ser.save()# 保存数据
然后这个时候去看数据库的时候(pycharm自带的),会发现有数据
查数据
有了数据之后,就在终端接着查数据
from app02.models import *
# 查多个数据(多个对象序列化)
arts = Article.objects.all()
ser = ArticleSerializer(instace=arts,many=True) # 如果多个对象序列化 需要加many
ser.data

这就是查到的数据,如何返回json数据呢
from rest_framework.renderers import JSONRenderer
json_data = JSONRenderer().render(ser.data)
json_data
这个json_data就是序列化好的json数据

查询所有的数据返回的是一个列表,然后通过https response 返回就可以了
这个就是把模型转化成json数据
这个查多个数据,也就是序列化多个数据,那单个数据可以查到吗?
单个对象的序列化
art = Article.objects.get(id=1)
ser = ArticleSerializer(art)
json_data = JSONRenderer().render(ser.data)
json_data
查询当个数据返回的是字典

当我们序列化的时候,也就是查数据的时候,要用instance传参
当我们反序列化,也就是传入数据的时候,要用data传参
DRF模型序列化(继承ModelSerializer)
ModelSerializers默认帮我们实现了创建和更新方法,简化了我们的操作,当然如果你想自己写,可以重写它。其余使用方法跟普通的序列化一样。
class ArticleSerializer(serializers.ModelSerializer):
class Meta:
model = Article
fields = ('id', 'title', 'vnum', 'content') #三者取一
#exclude = () 表示不返回字段 三者取一
#fields = '__all__': 表示所有字段 三者取一
#read_only_fields = () #设置只读字段 不接受用户修改
模型类
模型类还是和普通序列化一样,我们用同一个例子来对比一下,普通序列化和模型序列化的区别
from django.db import models
# Create your models here.
class Article(models.Model):
title = models.CharField(verbose_name='标题', max_length=100)
vum = models.IntegerField(verbose_name='浏览量')
content = models.TextField(verbose_name='内容')
序列化
接着在已经创建好的serializers.py上写
from rest_framework import serializers
#导入最开始的序列化
from .models import Article
#导入模型类
#模型序列化
class ArticleSerializer(serializers.ModelSerializer):
class Meta:
model = Article
fields = '__all__'
#序列化这个模型类里面的而全部字段
视图(增加数据的视图)
from django.shortcuts import render
from .models import *
#导入模型
from .serializers import *
#导入序列化类
from rest_framework.renderers import JSONRenderer
#转json数据
from django.http import HttpResponse
from rest_framework.parsers import JSONParser
#把json数据转成python里的数据
from django.views.decorators.csrf import csrf_exempt
#解决403错误,使用这个封装函数,把django里面的验证先去掉
# Create your views here.
@csrf_exempt
def article_list(request):
if request.method == 'GET':
#获取数据 #查询所有的数据
arts = Article.objects.all()
ser = ArticleSerializer(instance=arts,many=True)
#序列化
json_data = JSONRenderer().render(ser.data)
#反序列化,转json数据
return HttpResponse(json_data,content_type='application/json',status=200)
elif request.method == 'POST':
#接收数据,把用户输入的json数据转成python数据
data = JSONParser().parse(request)#把前端传过来的json数据转化成python里面的数据
ser = ArticleSerializer(data=data)
if ser.is_valid():
ser.save()
json_data = JSONRenderer().render(ser.data)
return HttpResponse(json_data, content_type='application/json', status=201)
#201表示创建成功数据
json_data = JSONRenderer().render(ser.errors)
return HttpResponse(json_data, content_type='application/json', status=400)
#400表示get request
路由
from django.contrib import admin
from django.urls import path
from app02 import views
#导入试图
urlpatterns = [
path('articles/', views.article_list,name='article_list'),
]
根及路由
from django.contrib import admin
from django.urls import path,include
from app01 import views
from rest_framework.routers import DefaultRouter
#使用提供的路由
route = DefaultRouter()
#把视图生成的路由注册到这个里
route.register(r'students',views.StudentViewSet)
route.register(r'groups',views.GroupViewSet)
#这样的话,他会帮我们生成对应的路由
'''
http://127.0.0.1:8000/students就会生成这样的路由
如果是获取当个学生的话,路由就是
http://127.0.0.1:8000/students/1/
'''
urlpatterns = [
path('admin/', admin.site.urls),
# path('api/',include(route.urls)),
# #这个加上api之后的路由就是http://127.0.0.1:8000/api/students
path('api/',include('app02.urls'))
]
可以通过postman看一下
这是获取数据和添加数据,还有删除和更新
更新删除视图
class JSONResponse(HttpResponse):
def __init__(self, data, **kwargs):
content = JSONRenderer().render(data)
kwargs['content_type'] = 'application/json'
super(JSONResponse, self).__init__(content, **kwargs)
#封装一个函数
@csrf_exempt
def article_detail(request,pk):
#要获取单个数据,一定要传进来一个关于这个数据的唯一标识
try:
art = Article.objects.get(pk=pk)
#查询像删除的数据,获取id
except Article.DoesNotExist:
#捕获异常,如果这个数据不存在
return HttpResponse(status=404)
if request.method == 'GET':
serializer = ArticleSerializer(instance=art)
#把查到数据序列化
return JSONResponse(serializer.data,status=200)
elif request.method == 'PUT':
data = JSONParser().parse(request)
#解析前端的数据
serializer = ArticleSerializer(instance=art,data=data)
#序列化单个数据
if serializer.is_valid():
#如果序列化好的数据存在的话
serializer.save()
#就保存起来
return JSONResponse(serializer.data,status=201)
#返回json数据
return JSONResponse(serializer.errors, status=400)
#不存在的话,就返回一个error错误
elif request.method == 'PATCH':
#表示局部更新
data = JSONParser().parse(request)
#解析前端的数据
serializer = ArticleSerializer(instance=art,data=data,partial=True)
#序列化单个数据,局部更新一定要加上partial=True,默认是false
if serializer.is_valid():
#如果序列化好的数据存在的话
serializer.save()
#就保存起来
return JSONResponse(serializer.data,status=201)
#返回json数据
return JSONResponse(serializer.errors, status=400)
#不存在的话,就返回一个error错误
elif request.method == 'DELETE':
art.delete()
#表示把查到的数据删除
return HttpResponse(status=204)
#204表示删除成功
drf模型序列化高级一
模型类
from django.db import models
# Create your models here.
class Category(models.Model):
name = models.CharField(verbose_name='分类名字',max_length=10)
class Article(models.Model):
title = models.CharField(verbose_name='标题', max_length=100)
vum = models.IntegerField(verbose_name='浏览量')
content = models.TextField(verbose_name='内容')
category = models.ForeignKey(to=Category,on_delete=models.CASCADE,related_name='articles')
之后,开始迁移
python manage.py makemigrations
python manage.py migrate
序列化
from rest_framework import serializers
#导入最开始的序列化
from .models import Article,Category
#导入模型类
#模型序列化
class ArticleSerializer(serializers.ModelSerializer):
class Meta:
model = Article
fields = '__all__'
#序列化这个模型类里面的而全部字段
class CatrgorySerializer(serializers.ModelSerializer):
class Meta:
model = Category
fields = ('id','name','articles')
#因为模型中有反向查找
视图
from django.shortcuts import render
from .models import *
from .serializers import ArticleSerializer,CatrgorySerializer
from rest_framework.renderers import JSONRenderer
from django.http import JsonResponse,HttpResponse
from rest_framework.parsers import JSONParser
from django.http import Http404
from django.views.decorators.csrf import csrf_exempt
# Create your views here.
class JSONResponse(HttpResponse):
def __init__(self, data, **kwargs):
content = JSONRenderer().render(data)
kwargs['content_type'] = 'application/json'
super(JSONResponse, self).__init__(content, **kwargs)
#封装一个函数
@csrf_exempt
def article_list(request):
if request.method == 'GET':
#请求数据,这个过程就是要把数据序列化
arts = Article.objects.all()
#查询数据
ser = ArticleSerializer(instance=arts,many=True)
#序列化查询出来的数据,instance表示你要序列化的数据,
# data表示你要反序列化的数据
#many=True 如果你序列化的字段很多,一定要加上这个
json_data = JSONRenderer().render(ser.data)
#调用data方法,把序列化好的数据取出来,
return HttpResponse(json_data,content_type='applications/json',status=200)
#注意不要忘记,告诉浏览器,返回的数据类型,
#content_type='applications/json'表示,网页上用json形式把josn_data数据展示出来
#状态码200200是响应正常的意思
elif request.method == 'POST':
#新增,也就是json数据转化为可传输数据
data = JSONParser().parse(request)
#把前端json的数据解析出来,解析成python里面的数据类型
serialize = ArticleSerializer(data=data)
#反序列化数据,注意,有颜色的这个data是关键字
if serialize.is_valid():
#校验数据,假如存在
serialize.save()
#就保存数据
json_data = JSONRenderer().render(serialize.data)
#然后再取出来数据,用json数据返回去
return HttpResponse(json_data, content_type='applications/json', status=200)
#201表示创建成功
json_data = JSONRenderer().render(serialize.errors)
#表示序列化没有成功
return HttpResponse(json_data, content_type='applications/json', status=400)
#校验不成功,就返回401未经授权
@csrf_exempt
def article_detail(request,pk):
#要获取单个数据,一定要传进来一个关于这个数据的唯一标识
try:
art = Article.objects.get(pk=pk)
#查询像删除的数据,获取id
except Article.DoesNotExist:
#捕获异常,如果这个数据不存在
return HttpResponse(status=404)
if request.method == 'GET':
serializer = ArticleSerializer(instance=art)
#把查到数据序列化
return JSONResponse(serializer.data,status=200)
elif request.method == 'PUT':
data = JSONParser().parse(request)
#解析前端的数据
serializer = ArticleSerializer(instance=art,data=data)
#序列化单个数据
if serializer.is_valid():
#如果序列化好的数据存在的话
serializer.save()
#就保存起来
return JSONResponse(serializer.data,status=201)
#返回json数据
return JSONResponse(serializer.errors, status=400)
#不存在的话,就返回一个error错误
elif request.method == 'PATCH':
#表示局部更新
data = JSONParser().parse(request)
#解析前端的数据
serializer = ArticleSerializer(instance=art,data=data,partial=True)
#序列化单个数据,局部更新一定要加上partial=True,默认是false
if serializer.is_valid():
#如果序列化好的数据存在的话
serializer.save()
#就保存起来
return JSONResponse(serializer.data,status=201)
#返回json数据
return JSONResponse(serializer.errors, status=400)
#不存在的话,就返回一个error错误
elif request.method == 'DELETE':
art.delete()
#表示把查到的数据删除
return HttpResponse(status=204)
#204表示删除成功
@csrf_exempt
def category_list(request):
if request.method == 'GET':
#请求数据,这个过程就是要把数据序列化
cat = Category.objects.all()
#查询数据
ser = CatrgorySerializer(instance=cat,many=True)
#序列化查询出来的数据,instance表示你要序列化的数据,
# data表示你要反序列化的数据
#many=True 如果你序列化的字段很多,一定要加上这个
json_data = JSONRenderer().render(ser.data)
#调用data方法,把序列化好的数据取出来,
return HttpResponse(json_data,content_type='applications/json',status=200)
#注意不要忘记,告诉浏览器,返回的数据类型,
#content_type='applications/json'表示,网页上用json形式把josn_data数据展示出来
#状态码200200是响应正常的意思
elif request.method == 'POST':
#新增,也就是json数据转化为可传输数据
data = JSONParser().parse(request)
#把前端json的数据解析出来,解析成python里面的数据类型
serialize = CatrgorySerializer(data=data)
#反序列化数据,注意,有颜色的这个data是关键字
if serialize.is_valid():
#校验数据,假如存在
serialize.save()
#就保存数据
json_data = JSONRenderer().render(serialize.data)
#然后再取出来数据,用json数据返回去
return HttpResponse(json_data, content_type='applications/json', status=200)
#201表示创建成功
json_data = JSONRenderer().render(serialize.errors)
#表示序列化没有成功
return HttpResponse(json_data, content_type='applications/json', status=400)
#校验不成功,就返回401未经授权
@csrf_exempt
def category_detail(request,pk):
#要获取单个数据,一定要传进来一个关于这个数据的唯一标识
try:
art = Category.objects.get(pk=pk)
#查询像删除的数据,获取id
except Category.DoesNotExist:
#捕获异常,如果这个数据不存在
return HttpResponse(status=404)
if request.method == 'GET':
serializer = CatrgorySerializer(instance=art)
#把查到数据序列化
return JSONResponse(serializer.data,status=200)
elif request.method == 'PUT':
data = JSONParser().parse(request)
#解析前端的数据
serializer = CatrgorySerializer(instance=art,data=data)
#序列化单个数据
if serializer.is_valid():
#如果序列化好的数据存在的话
serializer.save()
#就保存起来
return JSONResponse(serializer.data)
#返回json数据
return JSONResponse(serializer.errors, status=400)
#不存在的话,就返回一个error错误
elif request.method == 'PATCH':
#表示局部更新
data = JSONParser().parse(request)
#解析前端的数据
serializer = CatrgorySerializer(instance=art,data=data,partial=True)
#序列化单个数据,局部更新一定要加上partial=True,默认是false
if serializer.is_valid():
#如果序列化好的数据存在的话
serializer.save()
#就保存起来
return JSONResponse(serializer.data)
#返回json数据
return JSONResponse(serializer.errors, status=400)
#不存在的话,就返回一个error错误
elif request.method == 'DELETE':
art.delete()
#表示把查到的数据删除
return HttpResponse(status=204)
#204表示删除成功
路由
from django.contrib import admin
from django.urls import path,include
from app02 import views
urlpatterns = [
path('article',views.article_list,name='article-list'),
path('articles/' ,views.article_detail,name='article-detail'),
#这个表示获取单个数据,一定要注意和视图里面的参数保持一致,主键要一致
#name表示重命名
path('category', views.category_list, name='category_list'),
path('category/' , views.category_detail, name='category_detail'),
]
然后就可以去访问一下
DRF高级序列二(基于序列化)
StringRelatedField(和模型类的str配合使用,返回名字)
StringRelatedField 将返回一个对应关系 model 的 unicode() 方法的字符串。
#模型序列化
class ArticleSerializer(serializers.ModelSerializer):
class Meta:
category = serializers.StringRelatedField()
model = Article
fields = '__all__'
#序列化这个模型类里面的而全部字段
class Category(models.Model):
name = models.CharField(verbose_name='分类名字',max_length=10)
def __str__(self):
return self.name
#这块写什么返回什么,写self.name返回的是输入的名字
#比如写哈哈,那么返回的就是哈哈

category = serializers.StringRelatedField(many=True)
#如果是一查多的话,要写上many=True

在Article的模型下面加上srt方法
然后去访问标签页
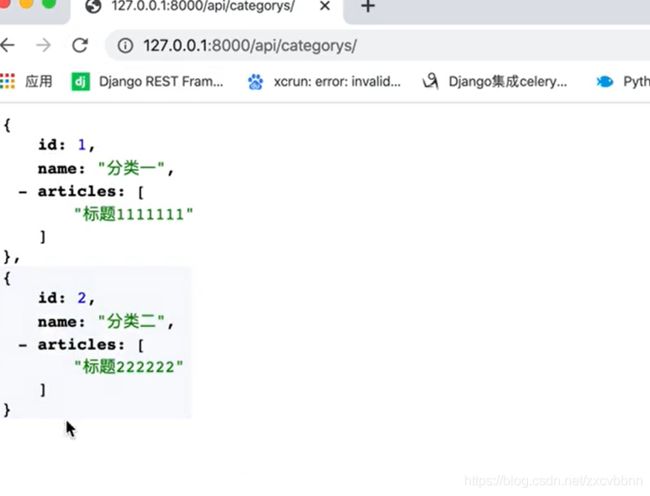
显示的就是对应的文章标题,而不是id
PrimaryKeyRelatedField(显示对应模型的id)
使用 PrimaryKeyRelatedField 将返回一个对应关系 model 的主键。
参数:
- queryset 用于在验证字段输入时模型实例查找。 关系必须明确设置 queryset,或设置 read_only = True
many 如果是对应多个的关系,就设置为 True- allow_null 如果设置为 True,则该字段将接受 None 的值或为空的关系的空字符串。默认为 False
pk_field 设置为一个字段以控制主键值的序列化/反序列化。例如,pk_field = UUIDField(format =‘hex’) 将UUID主键序列化为紧凑的十六进制表示。
class CategorySerializer(serializers.ModelSerializer):
articles = serializers.PrimaryKeyRelatedField(many=True, read_only=True)
class Meta:
model = Category
fields = '__all__'
PrimaryKeyRelatedField,如果是单个不需要加,many=True
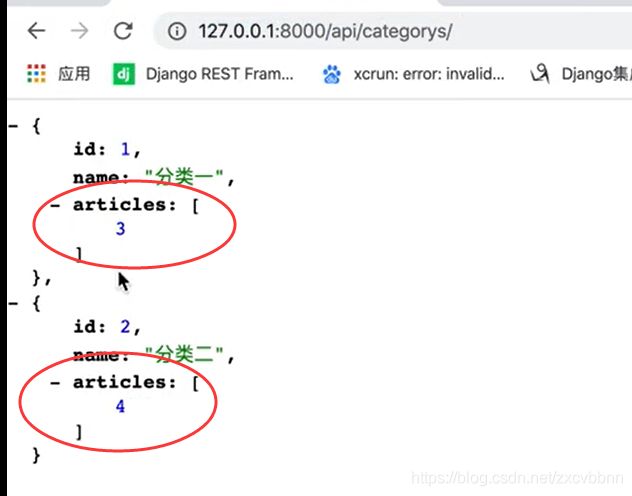
标签所对应的文章的id就会被返回,但是,其实它默认的就是返回的id
HyperlinkedRelatedField(在关联的模型中返回超链接)
使用 HyperlinkedRelatedField 将返回一个超链接(点击跳转对应页面),该链接指向对应关系 model 的详细数据,view-name 是必选参数,为对应的视图生成超链接。
参数:
- view_name 用作关系目标的视图名称。如果使用的是标准路由器类,那么它的格式为 -detail 的字符串
- queryset 验证字段输入时用于模型实例查询的查询器。关系必须明确设置 queryset,或设置 read_only = True
- many 如果应用于多对多关系,则应将此参数设置为 True
- allow_null 如果设置为 True,则该字段将接受 None 的值或为空的关系的空字符串。默认为 False
- lookup_field 应该用于查找的目标上的字段。应该对应于引用视图上的 URL 关键字参数。默认值为 pk
- lookup_url_kwarg 与查找字段对应的 URL conf 中定义的关键字参数的名称。默认使用与 lookup_field 相同的值
- format 如果使用 format 后缀,超链接字段将对目标使用相同的 format 后缀,除非使用 format 参数进行覆盖。
class CategorySerializer(serializers.ModelSerializer):
articles = serializers.HyperlinkedRelatedField(
many=True,#标签查文章有很多,所以要加上这个参数,一对一的话,不用加
read_only=True,
view_name='article_detail', #如果根及路由有别名的话,这个地方应该写成 根及路由的别名:应用及路由的别名
lookup_field='id', # 数据库字段的名字
lookup_url_kwarg="id" # 路由中参数的名字,必须和路由参数保持一致
)
class Meta:
model = Category
fields = '__all_
要想使用这个连接,必须在视图里面增加上下文,否则报错。
在视图里面加上上下文
content={‘request’:request}
添加位置在每一个序列化的地方
就在这些地方添加
这个时候在去访问

SlugRelatedField(可以返回对应模型的任何一个字段)
使用 SlugRelatedField 将返回一个指定对应关系 model 中的字段,需要参数 slug_field 中指定字段名称。可以返回模型类中的任何字段
参数:
- slug_field 应该用于表示目标的字段。这应该是唯一标识任何给定实例的字段。例如 username 。这是必选参数
- queryset 验证字段输入时用于模型实例查询的查询器。 关系必须明确设置 queryset,或设置 read_only = True
- many 如果应用于多对多关系,则应将此参数设置为 True
- allow_null 如果设置为 True,则该字段将接受 None 的值或为空的关系的空字符串。默认为 False
class CategorySerializer(serializers.ModelSerializer):
articles = serializers.SlugRelatedField(
many=True,
read_only=True,
slug_field='vum'
#这个写什么,就返回对应模型的值
)
class Meta:
model = Category
fields = '__all__'
HyperlinkedIdentityField(返回对应模型 视图的超链接)
使用 HyperlinkedIdentityField 将返回指定 view-name 的超链接的字段。
参数:
- view_name 应该用作关系目标的视图名称。如果您使用的是标准路由器类,则它将是格式
-detail的字符串。必选参数 - lookup_field 应该用于查找的目标上的字段。应该对应于引用视图上的 URL 关键字参数。默认值为 pk
- lookup_url_kwarg 与查找字段对应的 URL conf 中定义的关键字参数的名称。默认使用与 lookup_field 相同的值
- format 如果使用 format 后缀,超链接字段将对目标使用相同的 format 后缀,除非使用 format 参数进行覆盖
class ArticleSerializer(serializers.ModelSerializer):
category = serializers.HyperlinkedIdentityField(view_name="app03:category-detail", lookup_field='id')
#view_name的格式 根及路由的别名:应用及的路由别名
#lookup_field应用及的路由参数,保持一致
class Meta:
model = Article
fields = '__all__'
-------------------------------------------------
class CategorySerializer(serializers.ModelSerializer):
articles = serializers.HyperlinkedIdentityField(view_name="app03:article-detail", lookup_field='id', many=True)
class Meta:
model = Category
fields = '__all__'

HyperlinkedModelSerializer(返回超链接)
HyperlinkedModelSerializer 类与 ModelSerializer 类相似,只不过它使用超链接来表示关系而不是主键。
view_name的参数使用方法和上面一样
class ArticleSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = Article
fields = '__all__'
extra_kwargs = {
'url': {'view_name': 'app04:article-detail', 'lookup_field': 'id'},
'category': {'view_name': 'app04:category-detail', 'lookup_field': 'pk','lookup_url_kwarg':'id'},
}
class CategorySerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = Category
fields = ('id', 'name', 'articles','url')
#不写all的原因,Category里面没有article字段,但是在文章的模型中用到了反向查找,就可以这么用
extra_kwargs = {
'url': {'view_name': 'app04:category-detail', 'lookup_field': 'id'},
'articles': {'view_name': 'app04:article-detail', 'lookup_field': 'id'},
}
'''
使用extra_kwargs额外参数为ModelSerializer添加或修改原有的选项参数---字典格式
extra_kwargs = {
'vnum': {'min_value': 0, 'required': True},
}
'''
extra_kwargs 里面的写什么,什么就会返回超链接

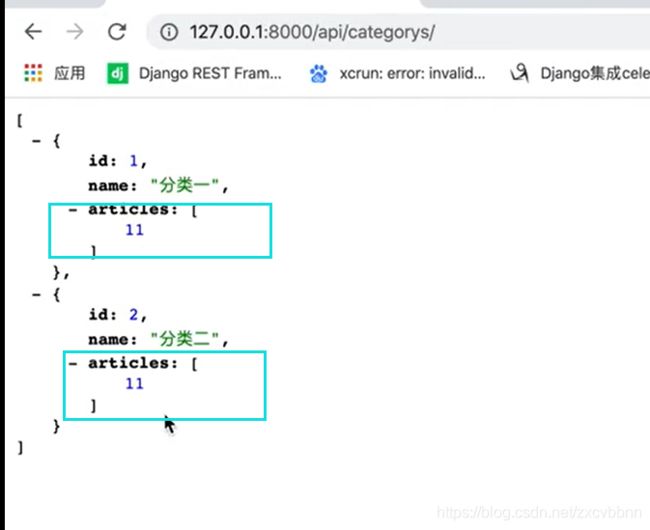
嵌套序列化关系模型(常用)
class ArticleSerializer(serializers.ModelSerializer):
class Meta:
model = Article
fields = '__all__'
class CategorySerializer(serializers.ModelSerializer):
articles = ArticleSerializer(many=True)
#如果返回的单个的话,不需要加many = true
class Meta:
model = Category
fields = '__all__'
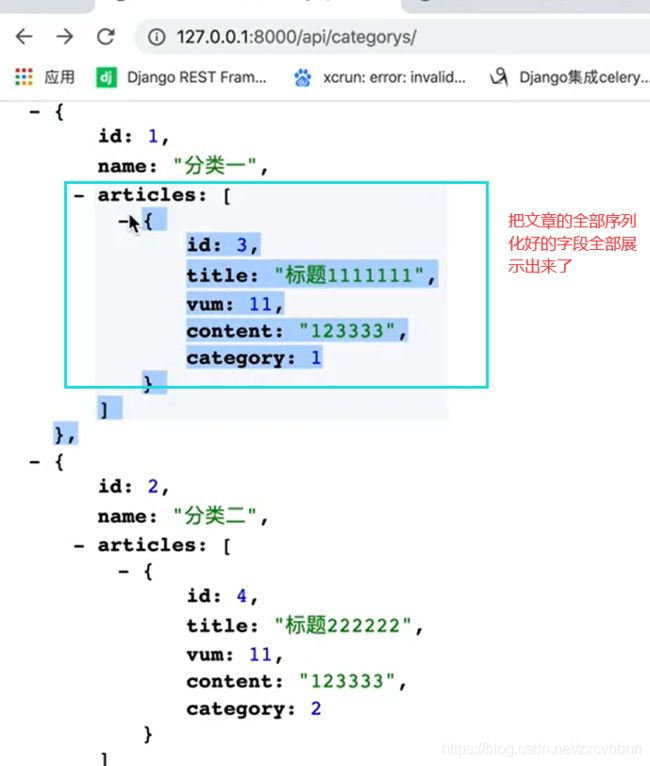
depth
这个字段可以用来深度遍历
#注意是ModelSerializer
class CategorySerializer(serializers.ModelSerializer):
articles = ArticleSerializer(many=True)
class Meta:
model = Category
fields = '__all__'
depth = 2

把相关的数据找出来,depth为几就找几层,一般建议2-3即可。
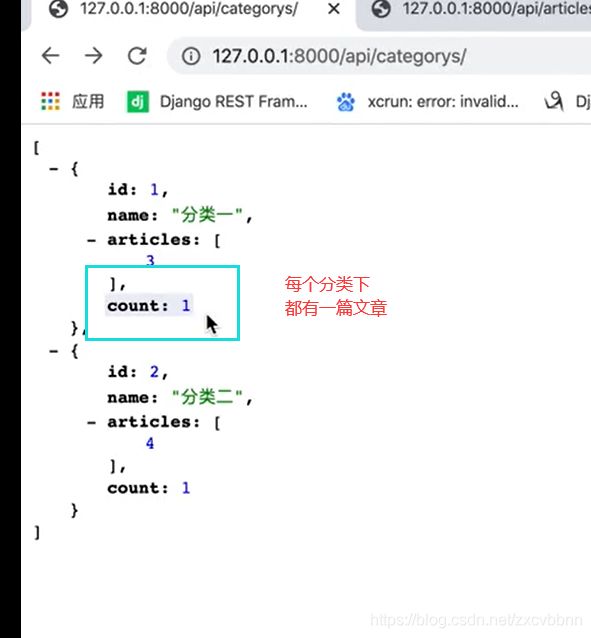
SerializerMethodField(自定义对应模型的属性)
我们可以自定义一些属性。
比如我们想看每个分类下有多少篇文章
class CategorySerializer(serializers.ModelSerializer):
articles = ArticleSerializer(many=True)
count = serializers.SerializerMethodField()
#这个是自定义属性,有了SerializerMethodField,必须实现下方的函数,那个函数也有规律
class Meta:
model = Category
fields = ('id','name','articles','count')
def get_count(self, obj):
#函数的名字是 get_加上上面自定义的属性名字
#obj表示当前分类的对象
return obj.articles.count()
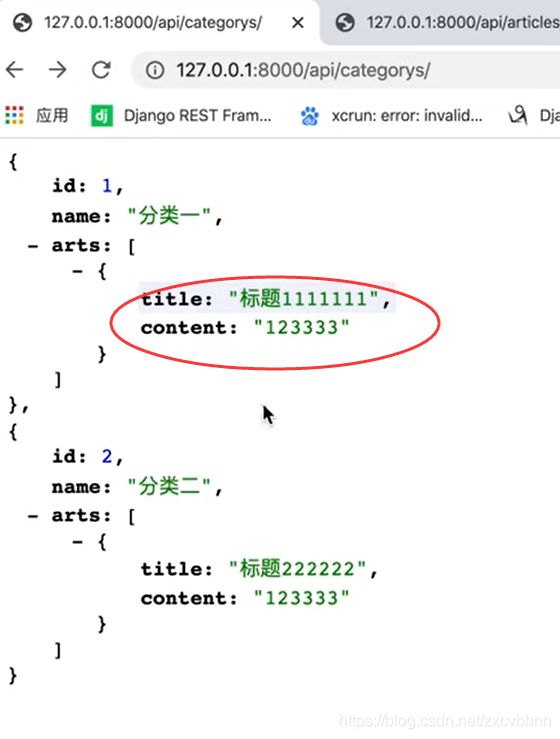
source
class ArticleSerializer(serializers.ModelSerializer):
category = serializers.CharField(source='category.id')
class Meta:
model = Article
fields = '__all__'
source=‘category.id’,上面这个指定的返回id,他返回的就是id

#这个类可以定义属性,以及想返回的值
class MyCharField(serializers.CharField):
#下面使用了这个类之后,所查到的数据都会给value,因为查找的是所有的值,所以返回的是一个列表
#所以可以定义一个空列表,进行遍历
def to_representation(self, value):
data_list = []
for row in value:
data_list.append({'title': row.title, 'content': row.content})
return data_list
class CategorySerializer(serializers.ModelSerializer):
#arts = MyCharField(source='articles.all')
#arts = serializers.CharField(source='articles_set.all')
#如果在模型中没有反向查找的话,也就可以这么写
arts = MyCharField(source='articles_set.all')
#使用上面定义的类,然后会把查到的所有文章,都给上面的参数value,因为是所有的文章,所以返回的是一个列表
class Meta:
model = Category
fields = ('id', 'name', 'arts')
利用source实现可读可写
from collections import OrderedDict
class ChoiceDisplayField(serializers.Field):
"""Custom ChoiceField serializer field."""
def __init__(self, choices, **kwargs):
"""init."""
self._choices = OrderedDict(choices)
super(ChoiceDisplayField, self).__init__(**kwargs)
# 返回可读性良好的字符串而不是 1,-1 这样的数字
def to_representation(self, obj):
"""Used while retrieving value for the field."""
return self._choices[obj]
def to_internal_value(self, data):
"""Used while storing value for the field."""
for i in self._choices:
# 这样无论用户POST上来但是CHOICES的 Key 还是Value 都能被接受
if i == data or self._choices[i] == data:
return i
raise serializers.ValidationError("Acceptable values are {0}.".format(list(self._choices.values())))
to_representation
序列化器的每个字段实际都是由该字段类型的to_representation方法决定格式的,可以通过重写该方法来决定格式。
class ArticleSerializer(serializers.ModelSerializer):
class Meta:
model = Article
fields = '__all__'
def to_representation(self, instance):
representation = super(ArticleSerializer, self).to_representation(instance)
representation['category'] = CategorySerializer(instance.category).data
representation['tags'] = TagSerializer(instance.tags, many=True).data
return representation