一、mysql
查看数据库:SHOW DATABASES;
创建数据库:CREATE DATABASE db_name;
使用数据库:USE db_name;
删除数据库:DROP DATABASE db_name;
创建表:
CREATE TABLE table_name(
id TINYINT UNSIGNED NOT NULL AUTO_INCREMENT, --id值,无符号、非空、递增——唯一性,可做主键。
name VARCHAR(60) NOT NULL,
score TINYINT UNSIGNED NOT NULL DEFAULT 0,--设置默认列值
PRIMARY KEY(id)
)ENGINE=InnoDB --设置表的存储引擎,一般常用InnoDB和MyISAM;InnoDB可靠,支持事务;MyISAM高效不支持全文检索
复制表:CREATE TABLE tb_name2 SELECT * FROM tb_name
创建临时表:CREATE TEMPORARY TABLE tb_name
查看表的结构:DESCRIBE tb_name
删除表:DROP TABLE IF EXISTS tb_name;
表重命名:ALTER TABLE name_old RENAME name_new;
更改表结构:ALTER TABLE tb_name ADD[CHANGE,RENAME,DROP]
实例
ALTER TABLE tb_name ADD COLUMN address varchar(80) NOT NULL
ALTER TABLE tb_name DROP address
ALTER TABLE tb_name CHANGE score score SMALLINT(4) NOT NULL;
插入数据:
INSERT INTO tb_name(id,name,score)
VALUES(NULL,'张三',140),(NULL,'张四',178),(NULL,'张五',134);
更新数据:UPDATE tb_name SET score=189 WHERE id=2;
删除数据:DELETE FROM tb_name WHERE id=3;
分组查询:HAVING 语句、group by 、order by:
SELECT * FROM tb_name GROUP BY score HAVING count(*)>2 order by id
Mysql支持REGEXP的正则表达式:
SELECT * FROM tb_name WHERE name REGEXP '^[A-D]' //找出以A-D 为开头的name
字符串连接:SELECT CONCAT(name,'=>',score) FROM tb_name
数学函数:AVG、SUM、MAX、MIN、COUNT;
文本处理函数:TRIM、LOCATE、UPPER、LOWER、SUBSTRING
日期:DATE()、CURTIME()、DAY()、YEAR()、NOW().....
select
current_timestamp --当前时间'YYYY-MM-DD HH:MM:SS'格式
,now()
,SUBDATE(now(),interval 60 second) --前一分钟
,ADDDATE(now(),interval 1 minute) --后一分钟
,ADDDATE(now(),interval 1 hour) --后一小时
,ADDDATE(now(),interval 1 day) --后一天
,UNIX_TIMESTAMP(now()) --时间戳
,DATE_FORMAT(now(), '%Y-%m-%d %H:%i:%S')
,date_add('2018-02-17',interval -day('2018-02-17')+1 day) --当月第一天
视图:CREATE VIEW name AS SELECT * FROM tb_name WHERE ~~ ORDER BY ~~;
存储过程:
CREATE PROCEDURE pro(
IN num INT,OUT total INT)
BEGIN
SELECT SUM(score) INTO total FROM tb_name WHERE id=num;
END;
----BEGIN...END...开始和结束,这里的存储过程两个变量,一个是IN一个是OUT,这里的OUT也是需要写上的,不写会出错
调用存储过程:create procedure 存储过程名(参数)
CALL pro(13,@total)
SELECT @total --这里就可以看到结果了;
rownum实现排序显示行号
SELECT @rownum:=@rownum+1 AS rownum, Orderstate.*
FROM (SELECT @rownum:=0) r, Orderstate ;
二、mssql
大部分同mysql
查看数据库列表:
select * from sysobjects where type='u' order by name
查询上月开始结束等日期:
--当月开始结束时间
select dateadd(d,-datepart(d,getdate())+1,convert(varchar(10),getdate(),120))
select dateadd(s,-1,dateadd(month,1,dateadd(d,-datepart(d,getdate())+1,convert(varchar(10),getdate(),120))))
--上个月开始结束时间
select dateadd(m,-1,dateadd(d,-datepart(d,getdate())+1,convert(varchar(10),getdate(),120)))
select dateadd(s,-1,dateadd(m,-0,dateadd(d,-datepart(d,getdate())+1,convert(varchar(10),getdate(),120))))
--dateadd(m,-1,dateadd(d,-datepart(d,getdate())+1,convert(varchar(10),getdate(),120))) and dateadd(s,-1,dateadd(d,-datepart(d,getdate())+1,convert(varchar(10),getdate(),120)))
--上周开始结束时间
select dateadd(d,(datepart(week,getdate())-1-1)7,DATEADD(wk,DATEDIFF(wk,0,DATEADD(yy, DATEDIFF(yy,0,getdate()),0)),0))
select dateadd(s,-1,dateadd(d,(datepart(week,getdate())-1-1)7,DATEADD(wk,DATEDIFF(wk,0,DATEADD(yy, DATEDIFF(yy,0,getdate()),0)),7)))
--查询上个月日期列表
select
序号=row_Number() over(order by number)
,日期=convert(varchar(10),dateadd(dd,number,convert(varchar(8),dateadd(m,-1,getdate()),120)+'01'),120)
from master..spt_values
where type='P'
and dateadd(dd,number,convert(varchar(8),dateadd(m,-1,getdate()),120)+'01')<=dateadd(s,-1,convert(varchar(8),getdate(),120)+'01')
跨服务器、数据链接:
--开启
--允许配置高级选项
EXEC sp_configure 'show advanced options', 1
GO
RECONFIGURE
GO
--开启xp_cmdshell服务
EXEC sp_configure 'xp_cmdshell', 1
RECONFIGURE
GO
--关闭
--允许配置高级选项
EXEC sp_configure 'show advanced options', 1
GO
RECONFIGURE
GO
--禁用xp_cmdshell
EXEC sp_configure 'xp_cmdshell', 0
GO
RECONFIGURE
GO
--在使用openrowset/opendatasource前首先要启用Ad Hoc Distributed Queries服务
--启用Ad Hoc Distributed Queries
exec sp_configure 'show advanced options',1
reconfigure
exec sp_configure 'Ad Hoc Distributed Queries',1
reconfigure
--关闭Ad Hoc Distributed Queries
exec sp_configure 'Ad Hoc Distributed Queries',0
reconfigure
exec sp_configure 'show advanced options',0
reconfigure
use local_datebase
go
select * from openrowset ---------数据库中无来源扩充行业表
('microsoft.Ace.oledb.12.0','excel 12.0;hdr=yes;database=D:\backup\desk\航空展导入来源.xls',Sheet2符号
---------注:HDR=Yes,这代表第一行是标题,不做为数据使用 ,如果用HDR=NO,则表示第一行不是标题,做为数据来使用。系统默认的是YES.
---------excel 2003:'microsoft.jet.oledb.4.0','excel 5.0
---------excel 2007:xlsx的2007版以上的为microsoft.Ace.oledb.12.0','excel 12.0
---------工作表以数字开头'select * from [3et$]'
go
链接服务器:使用OLEDB驱动程序创建SQL Server链接服务器
IF EXISTS(SELECT * FROM master..sysservers WHERE srvname='192.168.1.12')
EXEC sp_dropserver '192.168.1.12','droplogins'
EXEC sp_addlinkedserver '192.168.1.12','','SQLOLEDB','192.168.1.12'
EXEC sp_addlinkedsrvlogin '192.168.1.12','false',null,'sa','sa'
GO
row_number()实现排序显示行号:row_number() over(column partition by order by column)
不重复统计:来源不重复统计
select
来源类型=soName
,soCode
,成交量=(select count(distinct saclId) from v_SalesAuditList
where sassId=3047 and sasdId not in(1044,1047,1049,1054,1055,1058,1060,1062,1068,1070,1072,1076,1077,1079)
and saBocDate between '2014-01-01' and '2018-01-31'
--and saclId not in(select saclId from V_SalesAuditList where sasdId not in(1044,1047,1049,1054,1055,1058,1060,1062,1068,1070,1072,1076,1077,1079) and sassId=3047 and saBocDate<'2018-01-01')
and (select min(soId) from tb_Source where len(soCode)=8 and soCode in (select left((select soCode from tb_source where soId=snsoId),8) from tb_SourceNexus where sncoId=saclId))=soId
)
from tb_Source a
where len(soCode)=8
order by soCode
多行转一行:
select
产品=isnull((select STUFF((SELECT ','+waName from tb_WaySort
where exists(select 1 from tb_ProductNexus where pncoId=clId and pnwaId=waId) FOR XML PATH('')),1, 1, '') AS A
),'')
from tb_ClientMain
where clId=1000001
一行转多行:
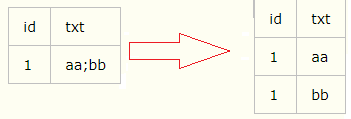
查询方法如下:
select
a.id,b.txt
from
(select id,txt=convert(xml,'
outer apply
(select txt=C.v.value('.','nvarchar(100)') from a.txt.nodes('/root/v')C(v))b
我解释下这个sql中用到的一些语法:
(1)replace函数,是将';'替换为了'
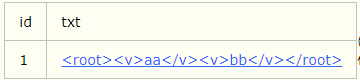
(2)在b表中,a.txt指的是a表的txt列,nodes函数的作用是根据参数中的字符串(标签)将xml转化为关系数据集,即转化为行 ,C(v)是别名,C为表明,v为列名。
通过以下语句进行查询C表的数据:
select C.v.query('.') txt
from PkTable
outer apply txt.nodes('/root/v')as C(v)

(3)C.v.value('.','nvarchar(100)'),C是表,v是列,value函数是读取标签之间的值,对于这个列子,读取的为
value的第一个参数是一个字符串文字,从 XML 实例内部检索数据。 XQuery 必须最多返回一个值。 否则,将返回错误;
value的第二个参数是指将查询结果转化为何种类型的数据。
此处,'.'表示当前目录,即
通过以下语句查询b表:
select b.txt
from
(select id,txt=convert(xml,'
outer apply
(select txt=C.v.value('.','nvarchar(100)') from a.txt.nodes('/root/v')C(v))b
b表的数据如下:

(4)最后就是outer apply了,他是先定好a表的列,然后取b表的列插入。对于这个函数,最后的查询结果为:

三、python连接数据库
import pymysql
--连接mysql,获取连接的对象
dbmysql = pymysql.connect(host='localhost', port=3306, user='root', passwd='root123', db='school', charset='utf8')
with dbmysql:
--获取连接的cursor对象,用于执行查询
cur = dbmysql.cursor()
--类似于其他语言的query函数,execute是python中的执行查询函数
cur.execute("select * from tb_Student")
--使用fetchall函数,将结果集(多维元组)存入datas里面
datas = cur.fetchall()
--依次遍历结果集,发现每个元素,就是表中的一条记录,用一个元组来显示
for data in datas:
print(data)
cur.close()
dbmysql.close()
import pymssql
--连接mysql,获取连接的对象
dbmssql = pymssql.connect(host='localhost',user='sa',password='sa',database='db_tables',charset='utf8')
with dbmssql:
--获取连接的cursor对象,用于执行查询
cur = dbmssql.cursor()
--类似于其他语言的query函数,execute是python中的执行查询函数,varchar乱码转为ncarchar正常
cur.execute("select * from tb_Student")
--使用fetchall函数,将结果集(多维元组)存入datas里面
datas = cur.fetchall()
--依次遍历结果集,发现每个元素,就是表中的一条记录,用一个元组来显示
for data in datas:
print(data)
cur.close()
dbmssql.close()
import sqlite3
conn = sqlite3.connect('sqlite.db')
cur = conn.cursor()
cur.execute("select * from tb_Student")
datas = cur.fetchall()
con.close()