5个Linux常用的系统检测工具
前言
使用Linux系统也有很长一段时间,很少想着去监控服务器的性能,想要写这篇博客也是源于想要通过这种方式将这些碎片的知识记录下来,且试用一下其内置的命令和一些附加的工具。
这些工具提供了获取系统活动的相关指标,可以使用这些工具来查找性能问题的可能原因,接下来提到的是一些基本的命令,用于系统分析和服务器调试等,例如
1. 找出系统瓶颈
2. 磁盘(存储)瓶颈
3. CPU和内存瓶颈
4. 网络瓶颈
1. top - 进程活动监控命令
top命令会显示Linux的进程,从图中可以看出它提供了一个运行中系统的实时动态图,显示了实际的进程活动,默认情况下,会显示服务器上运行的CPU占用率最高的任务,并且每五秒更新一次(可更改),top的详细命令和参数意思可以参考这篇博客 。
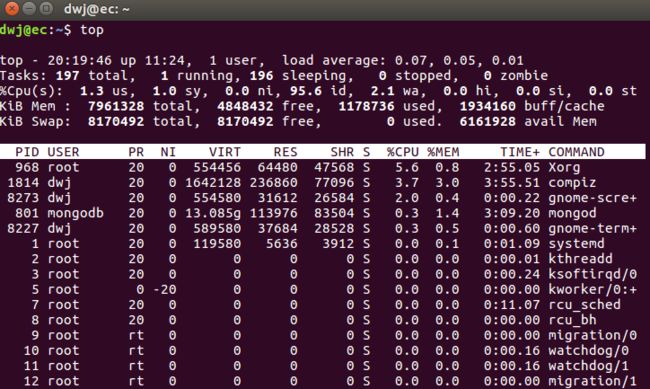
图中主要参数含义:
1. up 11:24 是系统运行时间,格式是,时:分
2. load average:0.07,0.05,0.01 系统负载,即任务队列的平均长度,是那个值分别是前1分钟、5分钟、15分钟到现在的平均值
3. zombie 是僵尸进程
4. Mem 是物理内存总量,buffers 是用作内存缓存的内存量
5. Swap 是交换区的总量,cached是换成的交换区总量
6. PR 优先级;
7. NI nice值,负值表示高优先级,正值表示低优先级;
8. RES j进程使用的、未被换出的物理内存大小,单位kb;
9. SHR 共享内存大小,单位kb;
10. S 进程状态:D=不可中断的睡眠状态、R=运行、S=睡眠、T=跟踪/停止、Z=僵尸进程
使用方法
top [-] [d] [p] [q] [c] [C] [S] [s] [n]
d 指定屏幕信息刷新之间的时间间隔。当然用户可以使用s交互命令来改变。
p 通过指定监控进程ID来仅仅监控某个进程的状态。
q 该选项将使top没有任何延迟的进行刷新。如果调用程序有超级用户权限,那么top将以尽可能高的优先级运行。
S 指定累计模式
s 使top命令在安全模式中运行。这将去除交互命令所带来的潜在危险。
i 使top不显示任何闲置或者僵死进程。
c 显示整个命令行而不只是显示命令名快捷键
top [-] [d] [p] [q] [c] [C] [S] [s] [n]
t 显示汇总信息
m 是否显示内存信息
A 根据各种系统资源的利用率对进程进行排序,有助于快速识别系统中性能不加的任务
f 进行top交互式配置屏幕,根据需求设置top的显示,默认情况下仅显示比较重要的
PID、USER、PR、NI、VIRT、RES、SHR、S、%CPU、%MEM、TIME+、COMMAND 列
o 交互式调地调整top每一列的顺序
r 调整优先级(renice)
k 杀掉进程(kill)
z 切换到彩色或者黑白模式2. vmstat - 虚拟内存统计
vmstat 虚拟内存统计,显示有关进程、内存、分页、块IO、中断和CPU活动等信息。具体信息可以参考这篇博客
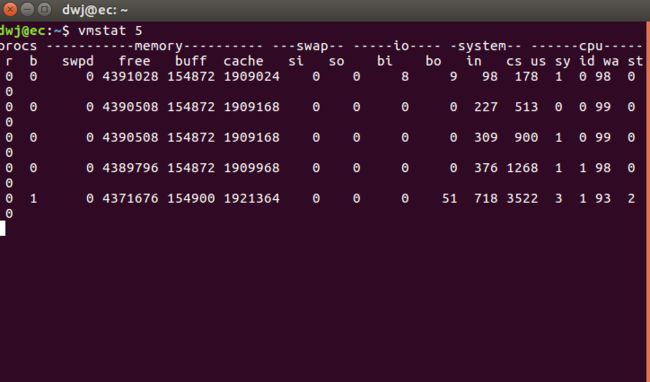
注:一般vmstat工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔数,单位是秒,第二个参数是采样的次数,如:
vmstat 3 2
## 参数1=3 表示间隔3秒;参数2=2,表示采样2次
vmstat 5
## 表示vmstat每2秒采集数据,一直采集,直到我结束程序(如上图)图中主要参数含义:
1.r 表示运行队列(就是说多少个进程真的分配到CPU),当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
2.b 表示阻塞的进程
3.swpd 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
4.free 空闲的物理内存的大小
5.buff Linux系统是用来存储,目录里面有权限等的缓存
6.cache cache直接用来记忆我们打开的文件,给文件做缓冲,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。
7.si 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。
8.so 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
9.bi 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备。
10.bo 块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
11.in 每秒CPU的中断次数,包括时间中断
12.cs 每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目。
13.us 用户CPU时间。
14.sy 系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
15.id 空闲 CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
16.wt 等待IO CPU时间。
其他命令
sudo vmstat -m
##显示slab缓存的利用率
vmstat -a
## 获取有关活动和非活动内存页面的信息3. w - 找出登录的用户以及他们在做什么
w 命令显示当前在该系统上的用户及其进程,具体参考这篇博客
语 法:w [-fhlsuV][用户名称]
补充说明:执行这项指令可得知目前登入系统的用户有那些人,以及他们正在执行的程序。单独执行w
指令会显示所有的用户,您也可指定用户名称,仅显示某位用户的相关信息。
参 数:
-f 开启或关闭显示用户从何处登入系统。
-h 不显示各栏位的标题信息列。
-l 使用详细格式列表,此为预设值。
-s 使用简洁格式列表,不显示用户登入时间,终端机阶段作业和程序所耗费的CPU时间。
-u 忽略执行程序的名称,以及该程序耗费CPU时间的信息。
-V 显示版本信息。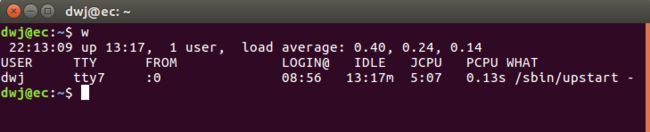
4. ps - 报告当前系统的进程状态
ps命令用于报告当前系统的进程状态。可以搭配kill指令随时中断、删除不必要的程序。
语 法:ps [选项]
参 数:
-a 显示所有终端机下执行的程序,除了阶段作业领导者之外
a 显示现行终端机下的所有程序,包括其他用户的程序
-A 显示所有程序
c 列出程序时,显示每个程序真正的指令名称,而不包含路径,选项或常驻服务的标示
-C 指定执行指令的名称,并列出该指令的程序的状况
-e 此选项的效果和指定"A"选项相同
e 列出程序时,显示每个程序所使用的环境变量
f 用ASCII字符显示树状结构,表达程序间的相互关系
-H 显示树状结构,表示程序间的相互关系
r 只列出现行终端机正在执行中的程序
-T 显示现行终端机下的所有程序
u 以用户为主的格式来显示程序状况
-au 显示较详细的资讯
-aux 显示所有包含其他使用者的行程
-help 显示帮助信息
-version 显示版本
注:由于ps命令能够支持的系统类型相当多,所以选项也多得离谱,其实还有很多不常用的选项没有列出来。感兴趣的可以参考博客。
5. netstat - 检验各端口的网络连接情况
netstat命令用于显示TP,TCP,UDP和ICMP等协议相关的统计数据,一般用于检验本机各端口的网络连接情况。
语 法:netstat [选项]
参 数:
-a 显示所有选项,默认不显示LISTEN相关
-t 仅显示TCP相关选项
-u 仅显示UDP相关选项
-n 拒绝显示别名,能显示数字的全部转化成数字
-l 仅列出有在Listen的服务状态
-p 显示建立相关连接的程序名
-r 显示路由信息,路由表
-e 显示扩展信息,例如uid等
-s 按各个协议进行统计
-c 每隔一个固定时间,执行该netstat命令
注: LISTEN和LISTENING的状态只有用-a或者-l才能看到
常用的查看网络TCP网络连接命令为netstat -ntlp ,我们能查看其连接状态,IP地址,以及连接的端口号等信息,效果如下图所示: