哈夫曼编码对字符串的压缩与解压缩(Java)
最近学习韩顺平老师主讲的“图解java 数据结构与算法”的哈夫曼编码这一章节时,在编码实现上遇到了些许问题,本文主要记述一下问题及自己的解决方案,如有更优解还请指点。
目录
一、压缩的思路
二、解压缩的思路
三、代码实现遇到的问题
四、解决方案
五、代码
一、压缩的思路
- 将数据先转换成byte数组;
- 在对该数组进行遍历,将每个byte元素转换成哈夫曼编码的字符串并拼接到StringBuilder中;
- 对哈夫曼编码进行遍历,每8位(也就是一个字节)转换成byte类型,最终转存为压缩后的byte数组。
二、解压缩的思路
- 逐个遍历压缩后的byte数组的元素;
- 对每个元素(byte数值),先与256(1 0000 0000)进行按位或补齐高位,转换为二进制字符串后截取末8位得到哈夫曼编码字符串并拼接至StringBuilder;
- 解码,将哈夫曼编码表map进行反转,由“压缩前的byte数值为key,哈夫曼编码字符串为value”转为“哈夫曼编码字符串为key,压缩前的byte数值为value”,根据这个map将读取哈夫曼编码StringBuilder并还原为压缩前的byte数值。
三、代码实现遇到的问题
- 需要压缩的数据经过哈夫曼编码得到的编码字符串在长度上不一定能被8整除,而在压缩存储时,每8个编码字符转换为1个byte的数据存入byte数组,通常情况下数组内最后一个元素都是长度不满8位的编码转换所得;
- 韩老师的代码中,对于长度为n的压缩数组,前n-1个元素按照解压缩思路中的第2步进行解码,而最后一个元素则是不补位、直接转为数值直接拼接到编码字符串;
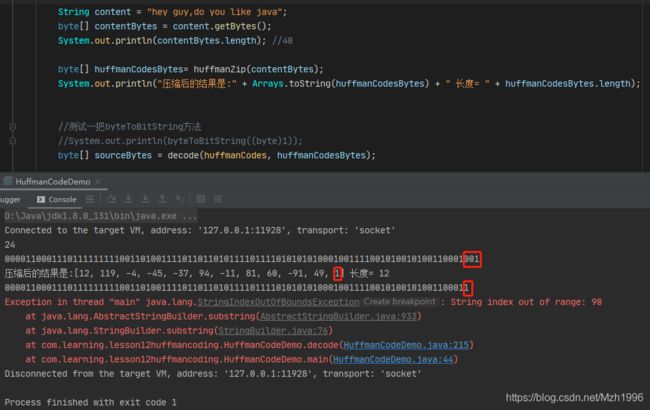
- 但是在实际运行时存在问题:假设哈夫曼编码串末尾的编码为“001”,存到byte数组时的值为1,而在解压缩时由于是压缩后byte数组的最后一个元素,直接转为字符串编码“1”,显然这不是我们想要的“001”。在之后根据编码还原数据会造成编码失配,如下图所示
四、解决方案
矛盾所在就是如何处理对末尾不满8位的编码,自己想了一个笨办法:
若哈夫曼编码的长度不能被8整除,则对于将未满8位的编码暂存到静态变量中,在解码还原时再添加至还原内容的末尾处(也可以记录末尾编码的长度,根据此长度对补位后的字符串进行截取)。运行结果如下:
五、代码
哈夫曼编码
import java.util.*;
/**
* 哈夫曼编码
*/
public class HuffmanCode {
public static void main(String[] args) {
// 字符串转为byte数组
String content = "hey,do you like java as much as i like";
System.out.printf("原始长度为 %d\n", content.length());
byte[] bytes = content.getBytes();
// 哈夫曼压缩
byte[] huffmanCodes = huffmanCompress(bytes);
// 哈夫曼解压缩
byte[] decodeResult = decompress(codeTable, huffmanCodes);
System.out.println(new String(decodeResult));
}
/**
* 编码表
*/
private static Map codeTable;
/**
* 暂存可能不足一个字节的字符编码
*/
private static String lastByte = "";
/**
* 将原始byte数组进行哈夫曼压缩
*
* @param bytes 原始数组
* @return 经过哈夫曼压缩的byte数组
*/
public static byte[] huffmanCompress(byte[] bytes) {
// step1 根据序列构建哈夫曼树
List nodeList = getNodes(bytes);
HuffmanTreeNode root = HuffmanTree.createHuffTree(nodeList);
// step2 获取哈夫曼编码表
codeTable = HuffmanTree.getCodingTable(root);
// step3 根据编码表压缩byte数组
return transfer(bytes, codeTable);
}
/**
* 将byte数组转为哈夫曼树结点的list
*
* @param bytes byte数组
* @return 结点list
*/
private static List getNodes(byte[] bytes) {
// 字符与出现次数(即哈夫曼树的权)的映射
Map map = new HashMap<>(32);
// 遍历bytes,将字符与其出现次数放入map
for (byte b : bytes) {
map.merge(b, 1, Integer::sum);
}
// 把map中的键值对转换成node加入到list中
List nodeList = new ArrayList<>();
for (Map.Entry entry : map.entrySet()) {
nodeList.add(new HuffmanTreeNode(entry.getKey(), entry.getValue()));
}
return nodeList;
}
/**
* 将原始byte数组根据编码表转换为哈夫曼编码
*
* @param codeTable 编码表
* @param origin 原始数组
* @return 哈夫曼编码后的byte数组
*/
private static byte[] transfer(byte[] origin, Map codeTable) {
System.out.println(Arrays.toString(origin));
// 将原数组转换成Huffman编码字符
StringBuilder huffmanStr = new StringBuilder();
for (byte item : origin) {
huffmanStr.append(codeTable.get(item));
}
// 压缩数组的长度
int len = huffmanStr.length() / 8;
if (huffmanStr.length() % 8 != 0) {
// 编码长度不能被8整除,保存多余的不足8位的部分
lastByte = huffmanStr.substring(len * 8);
}
System.out.printf("lastByte = %s\n", lastByte);
// 压缩存储的byte数组
byte[] huffmanCode = new byte[len];
for (int i = 0; i < huffmanCode.length; i++) {
huffmanCode[i] = (byte) Integer.parseInt(huffmanStr.substring(i * 8, i * 8 + 8), 2);
}
System.out.printf("压缩后的长度为 %d\n", "".equals(lastByte) ? len : len + 1);
return huffmanCode;
}
/**
* 封装解压缩的方法
*
* @param bytes 经过压缩的byte数组
* @return 解压后的byte数组
*/
public static byte[] decompress(byte[] bytes) {
return decompress(codeTable, bytes);
}
/**
* 将一个byte转为二进制字符串
*
* @param b 一个byte
* @return b对应的二进制字符串(补码)
*/
private static String byteToString(byte b) {
// 使用int暂存b
int temp = b;
// 补高位,和256(1 0000 0000)进行按位或
temp |= 256;
String str = Integer.toBinaryString(temp);
return str.substring(str.length() - 8);
}
/**
* 对压缩数据进行解码
*
* @param codeTable 编码表
* @param huffmanCode 压缩的数组
* @return 原字符串对应的byte数组
*/
private static byte[] decompress(Map codeTable, byte[] huffmanCode) {
System.out.println(Arrays.toString(huffmanCode));
// 先得到压缩数组对应的编码字符串
StringBuilder stringBuilder = new StringBuilder();
for (byte value : huffmanCode) {
stringBuilder.append(byteToString(value));
}
stringBuilder.append(lastByte);
// 把字符串按编码表进行解码(先将编码表反转,根据编码找原数值)
Map map = new HashMap<>(32);
for (Map.Entry entry : codeTable.entrySet()) {
map.put(entry.getValue(), entry.getKey());
}
// 扫描StringBuilder
List byteList = new ArrayList<>();
/*
* 此处i借助count这个增量来移动
* 若在每一轮循环时i++会导致漏扫描字符
*/
for (int i = 0; i < stringBuilder.length(); ) {
int count = 1;
Byte b;
while (true) {
String str = stringBuilder.substring(i, i + count);
b = map.get(str);
if (b != null) {
byteList.add(b);
i += count;
break;
}
count++;
}
}
// 将list赋值给array
byte[] bytes = new byte[byteList.size()];
for (int i = 0; i < bytes.length; i++) {
bytes[i] = byteList.get(i);
}
return bytes;
}
} 哈夫曼树
import java.util.*;
/**
* 哈夫曼树
*/
public class HuffmanTree {
public static void main(String[] args) {
int[] array = {13, 7, 8, 3, 29, 6, 1};
// 获取哈夫曼树的根
HuffmanTreeNode root = createHuffTree(arrToList(array));
// 先序遍历此哈夫曼树
preOrder(root);
}
/**
* 权值数组转为哈夫曼树
*
* @param arr 权值的数组
* @return 结点list
*/
public static List arrToList(int[] arr) {
List nodes = new ArrayList<>();
for (int value : arr) {
nodes.add(new HuffmanTreeNode(value));
}
return nodes;
}
/**
* 创建哈夫曼树
*
* @param nodes 结点list
* @return 创建的哈夫曼树的根
*/
public static HuffmanTreeNode createHuffTree(List nodes) {
/* 步骤如下:
* (1)对序列进行排序(升序)
* (2)从结点序列中取出头两个结点(权最小的两个)
* (3)两个结点权相加作为新节点的权,新节点加入序列中
* (4)重复(1)(2)(3)直至nodes中仅剩一个结点,即序列中的元素都已加入到哈夫曼树中
*/
while (nodes.size() > 1) {
// 排序(从小到大)
Collections.sort(nodes);
// 取出权最小的两个结点,权之和赋给新结点
HuffmanTreeNode left = nodes.get(0);
HuffmanTreeNode right = nodes.get(1);
HuffmanTreeNode parent = new HuffmanTreeNode(left.getWeight() + right.getWeight());
parent.setLeft(left);
parent.setRight(right);
// 将用到的两个子节点去除
nodes.remove(left);
nodes.remove(right);
nodes.add(parent);
}
// 最后nodes中仅剩的结点即为哈夫曼树的根
return nodes.get(0);
}
/**
* 先序遍历
*
* @param root 根结点
*/
public static void preOrder(HuffmanTreeNode root) {
if (root == null) {
System.out.println("树为空");
} else {
root.preOrder();
}
}
/**
* 字符与编码的映射
*/
public static Map codeMap = new HashMap<>(32);
/**
* 重载方法,根据根结点获取哈夫曼树的编码表
*
* @param root 根结点
* @return 字符与编码的映射
*/
public static Map getCodingTable(HuffmanTreeNode root) {
// 从根节点开始,递归遍历哈夫曼树,将叶子结点的哈夫曼编码存入映射
getCodingTable(root, "", new StringBuilder());
return codeMap;
}
/**
* 获取节点的哈夫曼编码并存入映射
*
* @param node 当前结点
* @param path 路径(向左 0;向右 1)
* @param lastCode 父结点的编码
*/
private static void getCodingTable(HuffmanTreeNode node, String path, StringBuilder lastCode) {
if (node != null) {
// 父结点的编码 + 路径 = 当前结点的哈夫曼编码
StringBuilder curCode = new StringBuilder(lastCode);
curCode.append(path);
if (node.getData() == null) {
// 非叶子结点,向左向右递归
getCodingTable(node.getLeft(), "0", curCode);
getCodingTable(node.getRight(), "1", curCode);
} else {
// 叶子结点,data域作为键,编码作为value存入映射,回溯
codeMap.put(node.getData(), curCode.toString());
}
}
}
}
哈夫曼树结点
/**
* 哈夫曼树结点
*/
public class HuffmanTreeNode implements Comparable {
/**
* 数据域
*/
private Byte data;
/**
* 结点权值
*/
private Integer weight;
/**
* 左子节点
*/
private HuffmanTreeNode left;
/**
* 右子节点
*/
private HuffmanTreeNode right;
public Integer getWeight() {
return weight;
}
public void setWeight(Integer weight) {
this.weight = weight;
}
public HuffmanTreeNode getLeft() {
return left;
}
public void setLeft(HuffmanTreeNode left) {
this.left = left;
}
public HuffmanTreeNode getRight() {
return right;
}
public void setRight(HuffmanTreeNode right) {
this.right = right;
}
public Byte getData() {
return data;
}
public void setData(Byte data) {
this.data = data;
}
public HuffmanTreeNode(Integer value) {
weight = value;
}
public HuffmanTreeNode(Byte data, Integer value) {
this.weight = value;
this.data = data;
}
@Override
public String toString() {
return "Node[" +
"data=" + (data == null ? null : (char) data.byteValue()) +
", weight=" + weight +
']';
}
/**
* 重写Comparable接口,比较结点关键字的大小
*
* @param node
* @descriptions:
* (1) 重写的compareTo关系到Collections.sort()如何排序
* (2) 若为【当前对象属性 - 传入对象属性】,则为升序
* (3) 若为【传入对象属性 - 当前对象属性】,则为降序
* @return
*/
@Override
public int compareTo(HuffmanTreeNode node) {
return this.weight - node.weight;
}
/**
* 先序遍历
*/
public void preOrder() {
// 访问当前结点
System.out.println(this.toString());
// 遍历左子树
if (this.getLeft() != null) {
this.getLeft().preOrder();
}
// 遍历右子树
if (this.getRight() != null) {
this.getRight().preOrder();
}
}
}