proxmox 5.2.1集群崩溃初步恢复
目录
环境:
现象:
解决方法:
环境:
pve1、pve2、pve3、pve4、pve5、pve6六台物理机组成proxmox集群,其中pve1上2个VM,pve2上2个VM,pve3上2个VM,pve4上6个VM,pve5上6个VM,pve6上8个VM,地址段(内网):10.180.8.*
现象:
六台物理机都可以正常启动,且浏览器管理控制台(webgui)可以正常访问,但是pve1、pve2和pve3上面的VM无法启动,启动时从控制台看到错误信息为:
a. TASK ERROR: start failed: command '/usr/bin/kvm -id 108 -name hdps -chardev 'socket,id=qmp,path=/var/run/qemu-server/108.qmp,server,nowait' -mon 'chardev=qmp,mode=control' -pidfile /var/run/qemu-server/108.pid -daemonize -smbios 'type=1,uuid=45b80ee2-0029-4a14-9782-89c58a56879f' -smp '4,sockets=2,cores=2,maxcpus=4' -nodefaults -boot 'menu=on,strict=on,reboot-timeout=1000,splash=/usr/share/qemu-server/bootsplash.jpg' -vga std -vnc unix:/var/run/qemu-server/108.vnc,x509,password -cpu kvm64,+lahf_lm,+sep,+kvm_pv_unhalt,+kvm_pv_eoi,enforce -m 12288 -device 'pci-bridge,id=pci.2,chassis_nr=2,bus=pci.0,addr=0x1f' -device 'pci-bridge,id=pci.1,chassis_nr=1,bus=pci.0,addr=0x1e' -device 'piix3-usb-uhci,id=uhci,bus=pci.0,addr=0x1.0x2' -device 'usb-tablet,id=tablet,bus=uhci.0,port=1' -device 'virtio-balloon-pci,id=balloon0,bus=pci.0,addr=0x3' -iscsi 'initiator-name=iqn.1993-08.org.debian:01:fa73da4586f' -drive 'file=/var/lib/vz/template/iso/CentOS-7-x86_64-Minimal-1804.iso,if=none,id=drive-ide2,media=cdrom,aio=threads' -device 'ide-cd,bus=ide.1,unit=0,drive=drive-ide2,id=ide2,bootindex=200' -device 'virtio-scsi-pci,id=scsihw0,bus=pci.0,addr=0x5' -drive 'file=/dev/pve/vm-108-disk-1,if=none,id=drive-scsi0,format=raw,cache=none,aio=native,detect-zeroes=on' -device 'scsi-hd,bus=scsihw0.0,channel=0,scsi-id=0,lun=0,drive=drive-scsi0,id=scsi0,bootindex=100' -netdev 'type=tap,id=net0,ifname=tap108i0,script=/var/lib/qemu-server/pve-bridge,downscript=/var/lib/qemu-server/pve-bridgedown,vhost=on' -device 'virtio-net-pci,mac=86:61:72:7A:CF:FD,netdev=net0,bus=pci.0,addr=0x12,id=net0,bootindex=300'' failed: got timeout
b. malformed JSON string, neither tag, array, object, number, string or atom, at character offset 0 (before "(end of string)") at /usr/share/perl5/PVE/Tools.pm line 949,
chunk 1.
TASK ERROR: VM 108 not runningc. stopped: unable to read tail (got 0 bytes)
d. TASK ERROR: Failed to run vncproxy.
e. TASK ERROR: connection timed out
f. TASK ERROR: volume 'local:iso/CentOS-7-x86_64-Minimal-1804.iso' does not exist
解决方法:
1、重新上传错误提示信息中的系统ISO(CentOS-7-x86_64-Minimal-1804.iso)文件到pve节点上,直接通过浏览器管理界面上传。上传成功后重新启动VM还是报错,错误为b或者a。

2、按照proxmox集群雪崩进行处理:将pve节点从集群中退出,然后登录浏览器控制台进行启动。具体过程如下:
a. 在待隔离节点上停止 pve-cluster 服务的命令
systemctl stop pve-cluster.service
systemctl stop corosync.service
b. 上一步执行成功后,执行将待隔离节点的集群文件系统设置为本地模式的命令
pmxcfs -l
c. 上一步执行成功后,执行删除 corosync 配置文件的命令
rm /etc/pve/corosync.conf
rm -rf /etc/corosync/*
d. 前3步都执行成功后,执行重新启动集群文件系统服务的命令
killall pmxcfs
systemctl start pve-cluster.service
前四步成功的截图:

e. 登录浏览器控制台查看pve状态,并重新启动VM并监控结果,成功的截图如下:
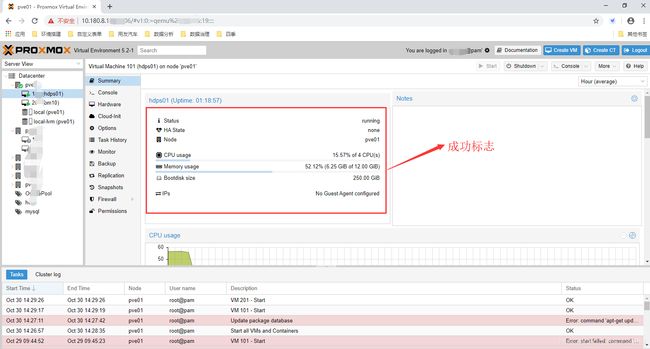
备注:必须每部都执行成功,否则要重复上个步骤。