[toc]
- tomcat相关资源下载
演化
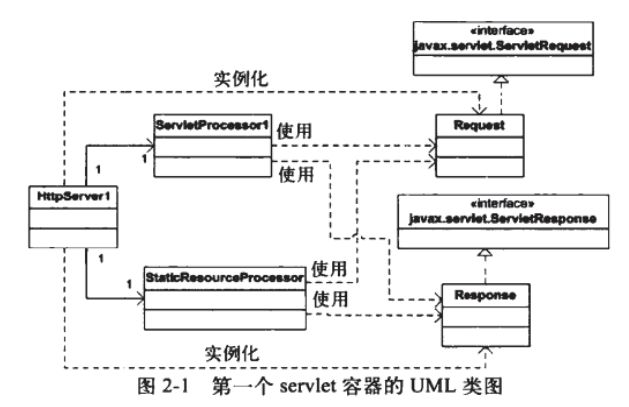
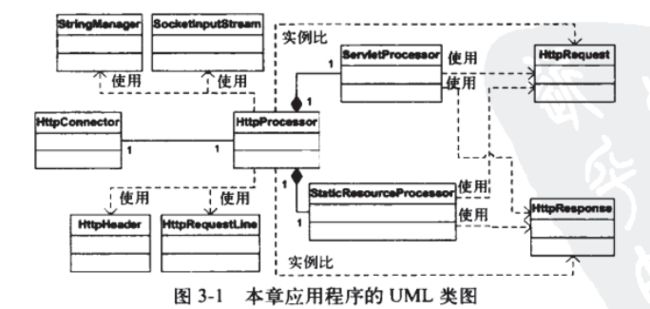
HttpConnector 的run方法执行
socket=serverSocket.accept(); 然后将socket传到HttpProcessor中,由process方法new Request和Response。
也就是说连接器(及其支持类Processor)完成 接受socket请求并生成request和reponse,然后在容器里完成 静态资源调用或者servlet的实例化及其service方法的调用。(如下uml关系)

书中的servlet类关系


外观模式
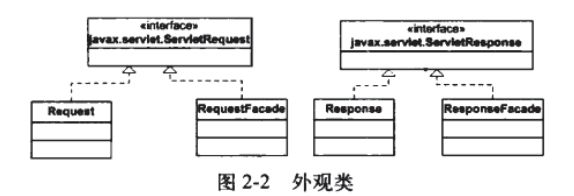
为了防止Request里的一些继承之外的方法被不安全访问,可以借鉴这种方式,在RequestFacade 的构造函数里
public class RequestFacade implements ServletRequest {
private ServleLRequest request = null;
public RequestFacade(Request request) {
this.request = request;
}
RequestFacade只实现ServletRequest的方法
RequestFacade requestFacade = new RequestFacade(request);
servlet.service((ServletRequest) requestFacade, (ServletResponse) responseFacade);
如此一来在service方法里访问不到Request的其他方法了。
线程专用
public class HttpConnector implements Runnable {
boolean stopped;
private String scheme = "http";
public String getScheme() {
return scheme;
}
public void run() {
。。。。。。。。
}
public void start() {
Thread thread = new Thread(this);
// thread = new Thread(this, threadName);
thread.start();
}
}
如此便可优雅的启动线程
HttpConnector connector = new HttpConnector();
connector.start();
break 标记处
boolean flag = true;
loop: {
if (flag) {
break loop;
}
System.out.println("in loop");
}
System.out.println("out loop");
processor对象池
用到的属性
/**
* The set of processors that have ever been created.
*/
private Vector created = new Vector();
/**
* The current number of processors that have been created.
* 也是HttpProcessor的id
*/
private int curProcessors = 0;
/**
* The minimum number of processors to start at initialization time.
*/
protected int minProcessors = 5;
/**
* The maximum number of processors allowed, or <0 for unlimited.
* 小于0 是无限制!
*/
private int maxProcessors = 20;
/**
* The set of processors that have been created but are not currently
* being used to process a request.
* 已经创建但现在没有被用于处理请求。该栈中的都是可以使用的。
*/
private Stack processors = new Stack();
- HttpConnector的start方法,其中会创建minProcessors数量的processor。并通过recycle方法,将其push进栈processors,以便循环使用。
// Create the specified minimum number of processors
while (curProcessors < minProcessors) {
// 万一出现maxProcessors 0) && (curProcessors >= maxProcessors))
break;
HttpProcessor processor = newProcessor();
recycle(processor);
}
- 在HttpConnector的newProcessor方法中new HttpProcessor 并启动其线程。并且
curProcessors++, created.addElement(processor);curProcessors做为HttpProcessor的id。
private HttpProcessor newProcessor() {
HttpProcessor processor = new HttpProcessor(this, curProcessors++);
if (processor instanceof Lifecycle) {
try {
// 启动processor
((Lifecycle) processor).start();
} catch (LifecycleException e) {
log("newProcessor", e);
return (null);
}
}
created.addElement(processor);
return (processor);
}
- 然后我们看HttpConnector的run方法。主要就是等待socket连接,这里需要注意
socket.setTcpNoDelay(tcpNoDelay);,这个是关闭Nagle算法,防止神奇的40ms延时.
// Loop until we receive a shutdown command
while (!stopped) {
socket = serverSocket.accept();
if (connectionTimeout > 0)
socket.setSoTimeout(connectionTimeout);
// 关闭Nagle算法,防止神奇的40ms延时
socket.setTcpNoDelay(tcpNoDelay);
当收到一个socket连接的时候,需要分配processor,主要是通过createProcessor方法来创建或者复用HttpProcessor,HttpProcessor的assign方法来将socket传递到HttpProcessor,进行后续的处理。
// Hand this socket off to an appropriate processor
HttpProcessor processor = createProcessor();
// 没有可用处理器就关闭socket。
if (processor == null) {
try {
log(sm.getString("httpConnector.noProcessor"));
socket.close();
} catch (IOException e) {
;
}
continue;
}
processor.assign(socket);
// The processor will recycle itself when it finishes
- HttpConnector的createProcessor方法
synchronized (processors) {
if (processors.size() > 0) {
// 重用已经存在的Processor
return ((HttpProcessor) processors.pop());
}
if ((maxProcessors > 0) && (curProcessors < maxProcessors)) {
// 未满最大值,就new一个
return (newProcessor());
} else {
if (maxProcessors < 0) {
// <0 代表无上限。
return (newProcessor());
} else {
return (null);
}
}
}
** 到这里我们已经明白了,Processor对象池重用(也可以叫做线程池)。**
然后我们要看看HttpProcessor是怎么运行的,以及自己怎么可持续地处理任务。
关键属性
/**
* Is there a new socket available?
*/
private boolean available = false;
- HttpProcessor的run。一开始会阻塞在 await(),等待连接器分配socket。处理完请求后调用
connector.recycle(this);把自己放进栈processors里去
// Process requests until we receive a shutdown signal
while (!stopped) {
// Wait for the next socket to be assigned
Socket socket = await();
if (socket == null)
continue;
// Process the request from this socket
try {
process(socket);
} catch (Throwable t) {
log("process.invoke", t);
}
// Finish up this request
connector.recycle(this);
}
available开始是false,所以阻塞在wait();
private synchronized Socket await() {
// Wait for the Connector to provide a new Socket
while (!available) {
try {
wait();
} catch (InterruptedException e) {
}
}
// Notify the Connector that we have received this Socket
Socket socket = this.socket;
available = false;// 此处由于已经拿到了分配的socket的引用,所以可以接下一个了。当然,理论上要等processor调用recyle才能下一个。
notifyAll();
if ((debug >= 1) && (socket != null))
log(" The incoming request has been awaited");
return (socket);
}
前面子分析HttpConnector的run方法的时候,run()里面调用了 processor.assign(socket);于是我们再看assign。
由于
synchronized void assign(Socket socket) {
// Wait for the Processor to get the previous Socket
// 这种情况应该不存在。这里的处理是保险手法,防止漏掉要处理的socket。
while (available) {
try {
wait();
} catch (InterruptedException e) {
}
}
// Store the newly available Socket and notify our thread
this.socket = socket;
available = true;
notifyAll();
if ((debug >= 1) && (socket != null))
log(" An incoming request is being assigned");
}
由于接收socket和处理socket分别在不同的线程里,所以可以同时处理较多的请求
生命周期(观察者模式)
首先,我们编程讲究面向接口编程。这样易于扩展。
我们看到书中,列如
SimpleContext implements Context, Pipeline, Lifecycle
SimpleWrapper implements Wrapper, Pipeline, Lifecycle
SimpleContext 实现Lifecycle后,将生命周期的功能添加了进来,而不是直接在所有start和stop的地方println。
同时 生命周期也是个非常好的观察者模式的实现。
首先我们看uml

- 实现LifeCycle的都称为一个组件(被观察者)。一个组件会做以下 的事情包括LifecycleSupport的事情。
// 我们关心的event
BEFORE_START_EVENT, START_EVENT,AFTER_START_EVENT, BEFORE_STOP_EVENT, STOP_EVENT, AFTER_STOP_EVENT.
addLifecycleListener
findLifecycleListeners
removeLifecycleListener
start
stop
- 支持类LifecycleSupport 维护一个
LifecycleListener listeners[]监听者数组。 为实现LifeCycle的类提供以下支持。
addLifecycleListener(LifecycleListener listener)
findLifecycleListeners()
fireLifecycleEvent(String type, Object data)// 通知观察者
removeLifecycleListener(LifecycleListener listener)
- 实现LifecycleListener是一个监听器(观察者)
流程:
- 向组件添加我们定义的监听器(观察者,比如SimpleContextLifecycleListener);
- 实现了LifeCycle的组件调用start(),LifecycleSupport的fireLifecycleEvent,通知观察者发生的事件。
在这里作为最顶层容器的SimpleContext ,会调自己start,还会间接调用两个子Wrapper容器 的start ,还有SimpleLoader的start等。
类加载器
自定义类加载器
对于java.lang.ClassLoader的loadClass(String name, boolean resolve)方法的解析来看,可以得出以下2个结论:
- 如果不想打破双亲委派模型,那么只需要重写findClass方法即可
- 如果想打破双亲委派模型,那么就重写整个loadClass方法
class MyLoader extends ClassLoader {
@Override
public Class loadClass(String name) throws ClassNotFoundException {
try {
String filename = name.substring(name.lastIndexOf(".") + 1) + ".class";
InputStream is = getClass().getResourceAsStream(filename);
if (is == null) {
return super.loadClass(name);
}
byte[] b = new byte[is.available()];
is.read(b);
return defineClass(name, b, 0, b.length);
} catch (IOException e) {
throw new ClassNotFoundException(name);
}
}
}
public class ClassLoadTest {
public static void main(String[] args) throws Exception {
ClassLoader myloader = new MyLoader();
Object object = myloader.loadClass("xyy.test.ClassLoadTest").newInstance();
Object object1 = new ClassLoadTest();
System.out.println(object.getClass());
System.out.println(object.getClass().getClassLoader());
System.out.println(object1.getClass().getClassLoader());
System.out.println(object instanceof xyy.test.ClassLoadTest);
}
}
java类加载为什么需要双亲委派模型这样的往返模式?
- 委派模型对于安全性是非常重要的
- 恶意的意图有人能写出一类叫做 java.lang.Object,可用于
访问任何在硬盘上的目录。 因为 JVM 的信任 java.lang.Object 类,它不会关注这方面的活动。因此,如果自定义 java.lang.Object 被允许加载,安全管理器将很容易瘫痪。幸运的是,这将不会发生,因为委派模型会阻止这种情况的发生。
当自定义 java.lang.Object 类在程序中被调用的时候, system 类加载器将该请求委派给 extension 类加载器,然后委派给 bootstrap 类加载器。这样 bootstrap类加载器先搜索的核心库,找到标准 java.lang.Object 并实例化它。这样,自定义 java.lang.Object 类永远不会被加载。
参考我写的另一篇总结:传送门
Digester(xml 解析)
用digester优雅解决多环境配置的问题。
主要知道怎么使用:
- 创建标签对象
- 设置对象属性
- 创建子标签,设置子标签属性(同上)
- 关联方法。
- 进行解析。
对于如上xml的解析代码:
public class Test02 {
public static void main(String[] args) {
String path = System.getProperty("user.dir") + File.separator + "etc";
File file = new File(path, "employee2.xml");
Digester digester = new Digester();
// add rules
digester.addObjectCreate("employee", "ex15.pyrmont.digestertest.Employee");
digester.addSetProperties("employee");
digester.addObjectCreate("employee/office", "ex15.pyrmont.digestertest.Office");
digester.addSetProperties("employee/office");
digester.addSetNext("employee/office", "addOffice");
digester.addObjectCreate("employee/office/address", "ex15.pyrmont.digestertest.Address");
digester.addSetProperties("employee/office/address");
digester.addSetNext("employee/office/address", "setAddress");
try {
Employee employee = (Employee) digester.parse(file);
ArrayList offices = employee.getOffices();
Iterator iterator = offices.iterator();
System.out.println("-------------------------------------------------");
while (iterator.hasNext()) {
Office office = (Office) iterator.next();
Address address = office.getAddress();
System.out.println(office.getDescription());
System.out.println("Address : " + address.getStreetNumber() + " " + address.getStreetName());
System.out.println("--------------------------------");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
或者将规则配置抽取成RuleSetBase的继承类EmployeeRuleSet。
public class EmployeeRuleSet extends RuleSetBase {
public void addRuleInstances(Digester digester) {
// add rules
digester.addObjectCreate("employee", "ex15.pyrmont.digestertest.Employee");
digester.addSetProperties("employee");
digester.addObjectCreate("employee/office", "ex15.pyrmont.digestertest.Office");
digester.addSetProperties("employee/office");
digester.addSetNext("employee/office", "addOffice");
digester.addObjectCreate("employee/office/address", "ex15.pyrmont.digestertest.Address");
digester.addSetProperties("employee/office/address");
digester.addSetNext("employee/office/address", "setAddress");
}
}
Test02: 修改
Digester digester = new Digester();
digester.addRuleSet(new EmployeeRuleSet());
关闭钩子(优雅的清理代码)
关闭钩子实际上是java虚拟机层面的东西,我们主要用来应对应用程序非正常关闭的情况(如ctrl+c)。
我们要做的就是写一个线程,Runtime.getRuntime().addShutdownHook在run方法中处理我们要清理的工作。
然后扔给虚拟机,当应用程序关闭的时候,会去调用这个线程要做的事。
demo:
public class ShutdownHookDemo {
public void start() {
System.out.println("Demo");
ShutdownHook ShutdownHook = new ShutdownHook();
Runtime.getRuntime().addShutdownHook(ShutdownHook);
}
public static void main(String[] args) {
ShutdownHookDemo demo = new ShutdownHookDemo();
demo.start();
try {
System.in.read();
}
catch(Exception e) {
}
}
private class ShutdownHook extends Thread {
public void run() {
// do some shutdown works
System.out.println("Shutting down");
}
}
}