大端小端与数字的二进制存储
部分1:大端小端概念
摘自:https://jocent.me/2017/07/25/big-little-endian.html
计算机系统中内存是以字节为单位进行编址的,每个地址单元都唯一的对应着1个字节(8 bit)。这可以应对char类型数据的存储要求,因为char类型长度刚好是1个字节,但是有些类型的长度是超过1个字节的(字符串虽然是多字节的,但它本质是由一个个char类型组成的类似数组的结构而已),比如C/C++中,short类型一般是2个字节,int类型一般4个字节等。因此这里就存在着一个如何安排多个字节数据中各字节存放顺序的问题。正是因为不同的安排顺序导致了大端存储模式和小端存储模式的存在。
1. 概述
1.1 定义假如有一个4字节的数据为 0x12345678(十进制:305419896,0x12为高字节,0x78为低字节),若将其存放于地址 0x4000 8000中,则有:
内存地址 0x4000 8000(低地址) 0x4000 8001 0x4000 8002 0x4000 8003(高地址)大端模式 0x12(高字节) 0x34 0x56 0x78(低字节)
小端模式 0x78(低字节) 0x56 0x34 0x12(高字节)
明显可以看出规律,即大端“高低低高”,小端“高高低低”:大端模式:是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中
小端模式,是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中
说明:0x代表16进制,由于16为2的4次方,刚好可以用4位半个字节表示;,或者说两个16进制数用一个字节表示。所以对于16进制的存储可以说:一个16进制数占4位,或者说两个16进制数占一个字节。比如对于int 0x12345678,0x12、0x34、0x56、0x78各占一个字节,直接翻译二进制为0001、0010,0011、0100,0101、0110,0111、1111;这种翻译方法与将0x12345678先转为10进制,再换算为二进制结果一致。
1.2 特点为什么截然相反的大小端存储模式能够并存至今?在标准化备受推崇的今天,为什么大小端谁都没有被另外一个所同化?我想这除了历史的惯性使然,还与它们各自的优缺点有关。
大端模式优点:符号位在所表示的数据的内存的第一个字节中,便于快速判断数据的正负和大小
小端模式优点:1. 内存的低地址处存放低字节,所以在强制转换数据时不需要调整字节的内容(注解:比如把int的4字节强制转换成short的2字节时,就直接把int数据存储的前两个字节给short就行,因为其前两个字节刚好就是最低的两个字节,符合转换逻辑); 2. CPU做数值运算时从内存中依顺序依次从低位到高位取数据进行运算,直到最后刷新最高位的符号位,这样的运算方式会更高效
其各自的优点就是对方的缺点,正因为两者彼此不分伯仲,再加上一些硬件厂商的坚持(见1.3节),因此在多字节存储顺序上始终没有一个统一的标准
1.3 现状
Intel的80×86系列芯片使用小端存储模式
ARM芯片默认采用小端,但可以切换为大端
MIPS芯片采用大端,但可以在大小端之间切换
在网络上传输的数据普遍采用的都是大端
2. 判断
方法一:通过将多字节数据强制类型转换成单字节数据,再通过判断起始存储位置是数据高字节还是低字节进行检测
// @Ret: 大端,返回true; 小端,返回false
bool IsBigEndian_1()
{
int nNum = 0x12345678;
char cLowAddressValue = *(char*)&nNum;
// 低地址处是高字节,则为大端
if ( cLowAddressValue == 0x12 ) return true;
return false;
}方法二:利用联合体union的存放顺序是所有成员都从低地址开始存放这一特性进行检测
// @Ret: 大端,返回true; 小端,返回false
bool isBigEndian_2()
{
union uendian
{
int nNum;
char cLowAddressValue;
};
uendian u;
u.nNum = 0x12345678;
if ( u.cLowAddressValue == 0x12 ) return true;
return false;
}3.1 大小端转换
// 实现16bit的数据之间的大小端转换
#define BLSWITCH16(A) ( ( ( (uint16)(A) & 0xff00 ) >> 8 ) | \
( ( (uint16)(A) & 0x00ff ) << 8 ) )
// 实现32bit的数据之间的大小端转换
#define BLSWITCH32(A) ( ( ( (uint32)(A) & 0xff000000) >> 24) |\
(((uint32)(A) & 0x00ff0000) >> 8) | \
(((unit32)(A) & 0x0000ff00) << 8) | \
(((uint32)(A) & 0x000000ff) << 32) )3.2 网络字节序与主机字节序的转换
方法三:使用内存查看器
转自:https://blog.csdn.net/shuiniu1224/article/details/21997221
查看内存是使用VS2010进行编码的一个非常基本的技能了,快速而准确地查看内存,可以帮助你准确分析代码中各变量的取值,以及存储状态,帮助你发现程序中的BUG,改进代码的健壮性。
如何查看内存?继续采用以上的例程进行说明,将程序F5到第13行,再单步到下一句
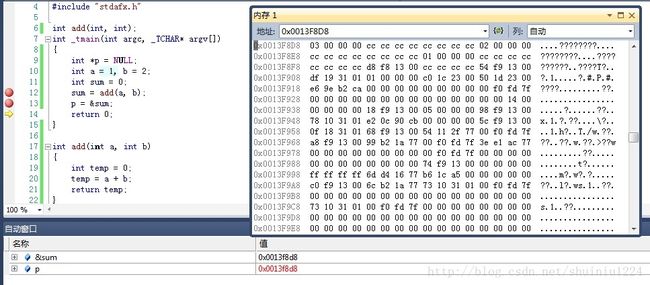
图3
按下ALT+6,此时我们可以看到内存1的窗口,我们从自动窗口中先找到指针p的地址,然后将地址复制到内存地址栏中,回车,即可看到此时地址中的值。内存窗口中左边的灰色值代表地址,右边则表示地址中存储的值。我们可以看到p地址对应的值为03,但后面还有000000跟着,其实因为我们存储的是一个整数值,需要4个字节存储,因此就算P中结果是3,也同样占用了4个字节。
这里还需要注意的一个概念是,大端法存储和小端法存储的概念。回到上面图中我们可以看出,内存地址从左至右,从上至下是依次增大的。我们这个值3其实正确的读法应该是从右至左读取的,即0x00000003,03是在最低位,而03也是存储在内存地址中的低地址中的,因此这是小端法存储,大端法则刚好相反。需要了解这方面更多信息的人,一定要上网查找更多资料多学习,本文就不再详述。
部分2:数字存储与大端小端结合
例题1
union Aunion
{
short k;
char t[2];
}val;
int main()
{
val.t[0] = 5;
val.t[1] = 1;
printf("%d", val.k);
return 0;
}输出的值是多少?
5的二进制为0000 0101,1二进制为0000 0001,所以排列顺序为0000 0101 0000 0001,(内存中:地址由小到大,并且每个地址单元都唯一的对应着1个字节(8 bit))。若为小端,则val.k在取出时,5、1的二进制被解释为0000 0001 0000 0101,其10进制数为261;若为大端,则val.k在取出时,5、1被解释为0000 0101 0000 0001,位2861。
例题2
int main()
{
char a = -1;
unsigned char b = -1;
printf("%d\n", a);
printf("%d\n", b);
return 0;
}求输出到屏幕的数
首先明确整数的存储方式:正整数直接存储其二进制形式,位数不够时,在其二进制数左边补0;对于负整数,先求出其正数的二进制,然后对此二进制数求补码即可。
所以对于-1计算方法为:
1的二进制 :0000 0001
对上述求补码:1111 1111
所以字符a、b都是存储的1111 1111,由于a是有符号的char,故取1111 1111补码,为0000 0001,输出1;b是无符号的char,故输出为1111 1111对应的数字255。
float、double的存储方式:先将该数转为对应的二进制,在写成二进制对应的科学计数法,之后存储该数的三部分信息,分别是符号、指数、尾数(小数点后边的数,小数点前边的数必为1);
符号正为0,负为1,指数采用余码方式(使得没有指数部分没有复数)float为余127码(指数加上127),double为余1023码(指数加上11023),尾数部分可以看成是正整数的存储方式;
float - 符号占1位,指数占8位,尾数占23位,double - 符号占1位,指数占11位,尾数占52位。