主从原理,一主多从架构
主从架构总结
主从原理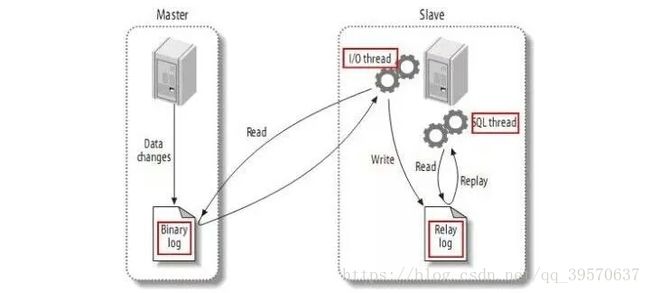
用binlog做主从,redolog只支持innodb
过程
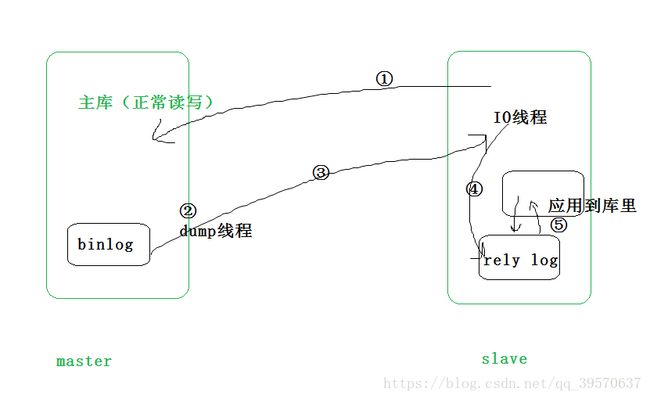
①start slave后从库启动io线程连接主库,请求读日志
②dump线程根据请求信息读取指定位置后的日志
③完成后就响应成功,没有确认机制
④IO线程收到信息,将受到的日志依次写入relay log
⑤sql线程检测到relay log更新,就解析增加部分的relaylog内容
即执行这部分sql,应用到自己的库要分离看io thread 和sql thread
备份从库的时候,可以关闭sql thread,io thread 正常运行
主从之间的延迟
传输延迟
主库产生大量日志(并行产生)
1、Dump是单线程,,没有能力读取速度如此之快的binlog
2、网络延迟
sar -n DEV 1io 线程
[root@localhost][(none)]> show processlist;dump 线程
mysql> pager grep -i "dump";3、从库的io 线程没有能力及时写入relaylog
提高从库的写入性能,最好的办法就是使用raid 卡,带有写缓存
4、要判断binlog 的生成速度
5、可以采用mixed 这种方式,因为row 可能会导致binlog 暴增。
如何看线程状态:
Linux 层面:ps -To pcpu,tid -C mysqld | sort -r -k1 | more
mysql> select * from performance_schema.threads where THREAD_OS_ID=2483;
top:H如何解决传输延迟:
1、增加物理读的能力
1、使用raid 卡(最好是RAID 10)或者磁盘阵列
2、使用PCIe 闪卡
2、增加网络带宽
3、增加写能力,使用raid 卡+写缓存(raid+写flash)
4、可以采用mixed 这种方式,因为row 可能会导致binlog 暴增
应用延迟
应用延迟的原因:
1、从库只有一个sql 线程,因此速度自然会慢
2、sql 有问题
通过慢查询日志来确认问题(开启查询时间全表扫描两个选项)
3、从库性能问题
show global status like ‘%rows%’;
不要只是查看时间差距、还要查看日志的量差距
通过线程状态去确认线程是否繁忙,是否达到100 的繁忙top H
如何解决应用延迟:
在5.7 里面可以采取并行复制:
slave-parallel-type = LOGICAL_CLOCK(一定要打开这个基于逻辑时间并行,
如果是别的下面这个参数就不管用了)
slave-parallel-workers = 16(从库启16 个并行线程,去恢复主库发过来的事
务,起了半同步,传输延迟就非常小,开启多线程,整个应用速度大幅提升,基
本实现了主从的完全同步,可以增大)
slave_preserve_commit_order=1(这个一定要是1、表示主库上事务提交的顺
序在从库上也按照这个顺序提交,因为并行之后十几个线程去应用,但是要保证
事务提交的顺序要不然事务就不一致了)
slave_transaction_retries=128(并行就意味着会有锁,当锁超时的时候,在这
个事务回滚之前,我试着再执行128 次,保证因为并行产生的锁,不至于已被锁
就马上回滚事务,而是再尝试执行128 次)
如何看传输延迟:
1,在主库上show master status\G,查看当前的binlog 点:
mysql> show master status \G
*************************** 1. row ***************************
File: mysqlserver.000007
Position: 222393531
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set:
1 row in set (0.00 sec)
mysql>2,在从库上show slave status\G,看从库IO 线程读到主库binlog 的位置:
mysql> show slave status \G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.35.23
Master_User: backup
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysqlserver.000007
Read_Master_Log_Pos: 217636200
mysql>3,1-2 的值表示主从库之间的传输延迟。
2、时间延迟
时间延迟计算方式:
传输过来的binlog 的时间-正在应用的binlog 的时间。
假设在某一个时间点出现了海量的ml,可能会出现主从应用延迟也就是
Seconds_Behind_Master 越来越大。
这个时候还是要同时去比较一下日志量的差距。
确认从库的性能问题的时候,要配合tps 和rows 去看:
mysql> show global status like '%rows%';
+--------------------------+---------+
| Variable_name | Value |
+--------------------------+---------+
| Innodb_rows_deleted | 3024 |
| Innodb_rows_inserted | 5134444 |
| Innodb_rows_read | 85069 |
| Innodb_rows_updated | 82021 |
| Not_flushed_delayed_rows | 0 |
| Sort_rows | 0 |
主从之间的延迟主要在应用延迟上:
1、主库的海量dml
2、row 模式,没有主键
3、row 模式,没有主键、没有高效索引
4、row 模式,没有主键、没有索引
5、从库单线程执行应用
如何处理:
1、特殊处理主库的海量dml
2、将所有的没有主键的表建立一个唯一键索引(联合唯一键索引)
3、最好给表加上主键(动作非常大,一定要谨慎)
4、将模式改成mixed
5、5.7 开始,一个很好的改进就是可以并行应用
并行度一般不超过cpu 的核数,最大不要超过2 倍
slave-parallel-type = LOGICAL_CLOCK
slave-parallel-workers = 16
#slave_preserve_commit_order=1
slave_transaction_retries=128但是对于上面的经典SQL,并行也解决不了。
因为主库一个线程产生的sql,因为row 模式到了从库以后变成很多的
sql,这些sql 只能被从库的一个线程执行,因此速度没有提升。
5.7 的新特性
现对于异步方式,主库提交成功,dump 线程及时发现,即时传送到从库,如
果主库出现问题,会出现部分binlog 没有传输到从库。
保证传输同步,但是不保证应用同步
主库的一些海量操作,例如批量、ddl操作,最好避免直接在生产上操作,如果非要做,可以在主库临时关闭回话级别的binlig,主从同时执行批量或者ddl前提是主从没有明显的延迟
主从搭建以及从库启动io线程,sql apply线程 监控主从线程工作状态
主从相关命令
change master to//从库连接主库的时候,跳过主库的一些binlog
binlog删除策略,可以使用过期参数或者purge定期删除
relaylog会自动清除,不需要关心
主从的几种架构:
1、一主多从
优点:主从间的传输延迟会小一些
缺点:产生太多binlog dump 线程,会加重主库的IO 负载
2、多级复制(级联复制)
多级复制的优缺点:
优点:主上就一个dump 线程,从主上不承担读binlog 的内容,只负责把主
上的binlog 传送到从库上。要把从主的表和各种都设置成BLACKHOLE 引擎,
从主应用日志产生的数据都被丢到黑洞里去,只需要从主在应用主库的binlog
时产生的binlog,所以设置log_slave_updates=on,从主开启binlog,才能在从
主应用主上的日志的时候把产生的binlog 传送到(二级)从库上。
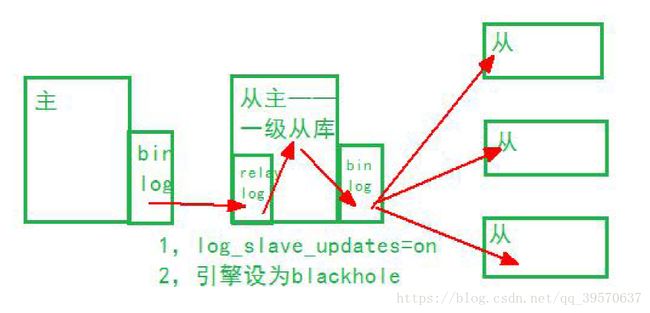
多级复制中一级从库的设置要点:
1、设置log_slave_updates=on,从主开启binlog
2、把从主的引擎设置成BLACKHOLE
缺点:二级从库的延迟会大一些,在从主那里又应用产生binlog,造成了延
迟。