关于freespace的调研
1.freespace的介绍:
汽车可行驶的区域,包括避开其他车辆,行人和马路边,如紫色和绿色的区域。
PSPnet在Cityscape上的结果

Multinet在KITTI上的结果

2.调研的方法:
fcn方法的介绍:
-
论文的创新点:主要用到三个技术:
-
卷积化:将最后的三层全连接层改为卷基层,最好得到的heatmap热图
-
上采样:对得到的heatmap图进行放大,得到和原来图片同等大小的图
-
跳跃结构:通过保留pool3,pool4层的featuremap对最后的输出图进行优化,实际上就是不断的与进行上采样后的heatmap进行混合(相加)。
-
框架中特殊层:
跳跃结构的最后几层结构如下:
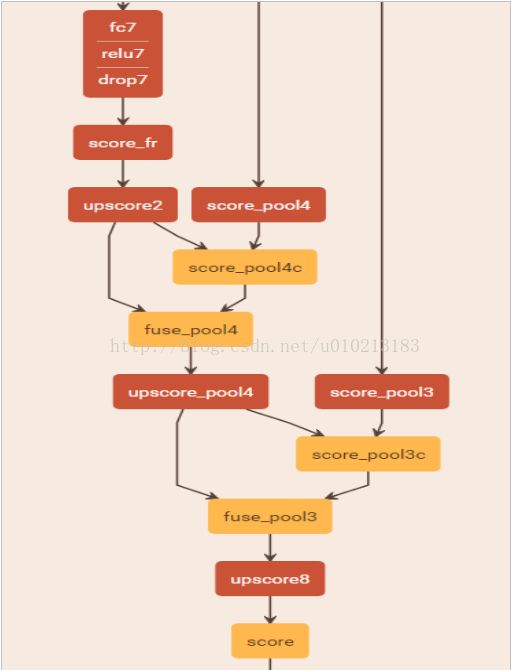
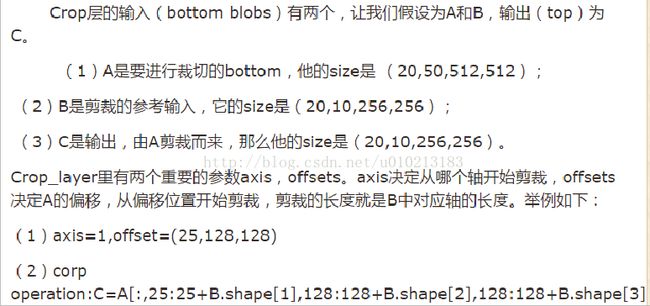
(其中score_fr,score_pool4, score_pool3是卷积操作卷积核大小1*1,个数为60即类别数;upscore2,upscore_pool4,upcrop8是反卷积
,大小为4*4,步长为2,score_pool4c,score_pool3c,score都是对图像进行裁剪(axis决定从哪个轴开始剪裁,offsets决定A的偏移,
从偏移位置开始剪裁,剪裁的长度就是B中对应轴的长度。fuse_pool4,fuse_pool3指的是特征的融合操作))。
逐个像素计算softmax分类的损失,保留了像素的空间位置和标签。FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的featuremap进行上采样,使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测,同时保留了原始输入图像中的空间信息,最后在上采样的特征图上进行逐像素分类。最后一层的输出的维数表示的是类别的个数(0-59为60类)。
但是我们按照上面的方法把这张图片load进来之后,label就是一个(1,500,334)的二维数据(严格来说是三维),每个位置的数值正是原图在这个位置的类别。
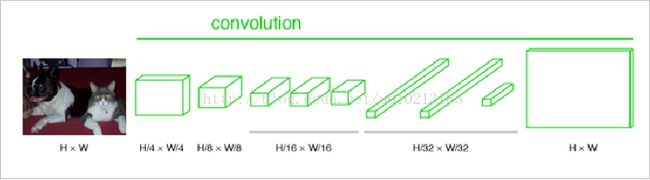
(每张H*W的图片上的像素值是计算每个像素属于每个类别的概率值)就是最后通过逐个像素地求其在60张图像该像素位置的最大数值描述(概率)作为该像素的分类。
| 0.2 |
0.3 |
... |
|
|
|
|
| 0.1 |
|
|
|
|
|
|
| 0.3 |
|
|
|
|
|
|
| |
|
|
|
|
|
|
| |
|
|
|
|
|
|
| |
|
|
|
|
|
|
| |
|
|
|
|
|
|
最后的H*W的图
PSPnet方法的介绍:
-
论文的创新点:
Cityscapes数据集的定义:

-
Road:汽车开车的地面,即所有车道,所有方向,所有街道。此标签不包括路牙。
-
Sidewalk:部分地面指定为行人或骑自行车者。通常比道路高,位于路边。
-
Parking:停车场。
-
Railtrack:汽车无法驾驶的各种轨道,例如地铁和火车轨道。
主要贡献:
1.提出pyramidscene parsing network(金字塔模型)
2.提出effectiveoptimization strategy for deep ResNet [13] based on deeply supervisedloss(基于深度监督误差的Resnet优化策略)
作者提出加入一个额外的loss,这样网络可分为两个相对简单的优化部分了
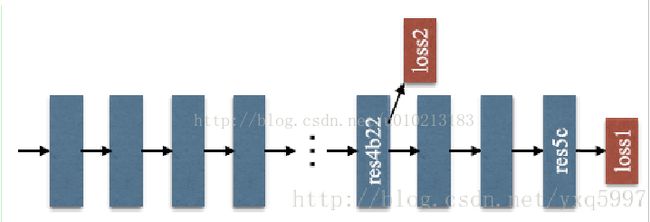
2.框架中特殊层:
最近的工作:一路是基于多尺度(因为高层一般对应的是语义信息而低层对应的事位置信息),另一路是structureprediction[3],采用CRF作为后处理。
有论文指出globalaverage pooling with FCN可以改善分割效果,但本文发现在复杂场景下并不有效,因此提出了不同区域的上下文聚合的方法。
介绍金字塔池化模块:
金字塔池化模块:4层
最粗的一层是globalpooling,得到一个singlebin,其他的层得到的是sub-region,这样池化之后得到的featuremap是不同尺寸的。
接下来对每个金字塔level做一个一个1*1卷积,将contextrepresentation的维度变成原来的1/N,N是金字塔的层数。
然后直接对低维的featuremap进行上采样,得到原图尺寸。
最后,不同层的feature连接后经过卷积conv输出。
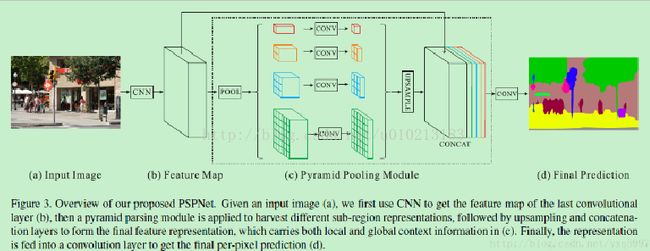
网络框架:
-
基于Deeplab的CNN卷积网络,采用一个pre-trained网络ResNet[13],并加入dilatednetwork来提取featuremap,得到的featuremap的尺寸是原始图的1/8。
-
采用4层金字塔模型,最后通过卷积后连接起来。
其中连接层也就是concatlayer(官方文档如下):

3.结果的分析:
1)基于VGG-net的fcn-8s网络
结果:马路边被检测为可行驶区域,可行驶区域检测效果不好,但是可以任意大小图片输入
2)基于Resnet的PSPnet网络:
3.1直接缩小到713*713大小的输入
结果:很多可行驶区域未检测出
3.2长边固定到713,将短边按比例缩小,不足的区域加入pad
结果:马路边被检测为可行驶区域,远处行人未检测出
3.3短边固定到713,将长边按比例缩小,按固定步长切割原图放入,最后按权重取平均
结果:比前两种都较好,但是还是有马路边被检测为可行驶区域,速度比前两种慢
3.4放大到指定的大小,在分成八块进行融合
结果:有车辆未检测出(失败)
3.5将图片切为上下部分,将下部分有路面的放入进行检测
结果:道路检测失败
需要指定大小输入,要考虑图片长宽的比例
3)multinet(未测试)
4.展望
1)训练方向:
1.两类的方向:
数据:KITTI是两类数据(除了路面就是背景)
数据集大小:1000张左右的数据
2.多类的方向:
数据:Cityscape是多类的数据集(包括车辆,行人)
数据集大小:5000张精标记和20000张粗标记
数据:VOC数据集
数据集大小:
2)预处理方向:
辅助车道线检测的算法,这样减少马路边被检测为可行驶区域