python web py入门-3-URL映射
本文介绍URL映射,在介绍映射之前,我们先了解下什么是URL? URL(Uniform/Universal Resource Locator的缩写,统一资源定位符)是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。知道了什么是URL,那么URL映射就好理解。白话说就根据URL的匹配规则去寻找对应的页面。
1.URL三种映射
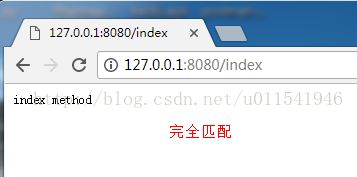
1) URL完全匹配,格式: /index
解释,在浏览器输入http://localhost:8080/index,那么会完全匹配“/index”这样的页面。
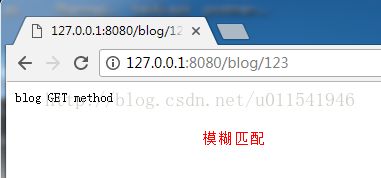
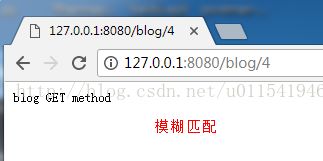
2)URL模糊匹配,格式:/index\d+
解释:这里意思是以"/index"开头,后面跟着一个数字或者多个数字这样的URL进行匹配,例如,浏览器输入:http://localhost:8080/index123 或者http://localhost:8080/index4,这种模糊匹配,一般是需要用到正则表达式。
3)URL带组匹配,格式 /index(\d+)
解释:这个带组匹配和上面模糊匹配好像,就因为在正则表达式外部添加一个括号,就表示匹配一组。
2.修改我们之前的hello.py内容,来练习一下URL映射
import web
urls = (
'/index', 'index',
'/blog/\d+', 'blog',
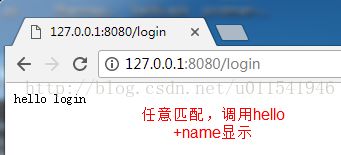
'/(.*)', 'hello'
)
app = web.application(urls, globals())
class hello:
def GET(self, name):
return 'hello '+ name
class index:
def GET(self):
return 'index method'
class blog:
def GET(self):
return 'blog GET method'
def POST(self):
return 'blog POST method'
if __name__ == "__main__":
app.run()
3. 测试运行不同URL,去验证设置的匹配是否成功
3.1 完全匹配
3.2 模糊匹配
3.3 任意匹配