hadoop、hive、sqoop、spark、livy、jdk单节点伪分布式集群一键部署shell脚本
ards.1.0安装说明
注:脚本tgz包后续上传,欢迎留言与我交流讨论
一、使用说明
本脚本可实现快速自动安装(hadoop-2.7.3/hive-1.1.0/sqoop-1.4.6/spark-2.3.0/livy/jdk1.8)集群功能,提前阅读以下说明(脚本内亦有提示)有助于您使用此脚本
1、脚本经centos6.5、centos7.4/7.5测试安装正常,脚本内输入错误可使用Ctrl+Backspace进行删除
2、要求服务器上有安装好的mysql并设置登陆账号和密码,脚本执行中按会提示输入mysql用户名和密码
3、服务器需配置正确的hostname(hostname前面不可跟回环地址127.0.0.1)例:
[root@SHELL2 tgz]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.110.133 SHELL24、可解压tar包至任意位置(命令:tar -zxvf ardh.spark.1.0.tgz)
5、脚本当前状态为自动获取系统JAVA_HOME,默认安装位置为/data/arbd
6、如需修改默认安装参数请编辑下面两个配置文件或在脚本执行时输入:(实际安装中优先级为:脚本输入 > 配置 > 脚本自动获取)
7、编辑ardh-spark/conf/jvm.conf的JAVA_HOME参数(置则为空则自动获取系统环境变量)
[root@SHELL2 tgz]# cd ardh-hbase/
[root@SHELL2 ardh-ardh-spark]# vi conf/jvm.confJAVA_HOME=修改后:wq保存退出编辑8、编辑ardh-spark/conf/env.conf的安装位置参数:arbdDir(置则为空则默认安装在/data/arbd下)
[root@SHELL2 ardh-spark]# vi conf/env.conf
#软件安装位置,绝对路径,末尾不要带/
arbdDir=
#mysql数据库主机名(本机请输入localhost)
host_name=
#自定义的mysql中hive的元数据库名称(如hive)
d_name=
#mysql数据库用户名(如root)
u_name=
#mysql数据库密码
ps_word=修改后:wq保存退出编辑9、编辑ardh-spark/conf/env.conf有关hive元数据库的参数
操作参考第8条10、切换至root用户,(命令:su - root)
11、用source方式执行脚本!!!(命令:source ./setup.sh)
12、JDK版本要求1.8,若选择自动获取系统JAVA_HOME且系统未安装JDK1.8,会触发JDK安装选项(默认位置:/usr/java下)
13、脚本内按中文提示操作即可,需要注意的是首次安装hadoop需要输入两个yes:

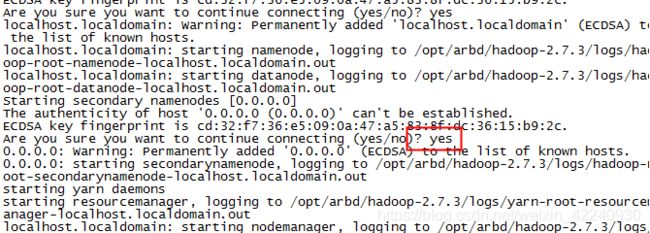
14、配置hive元数据库时脚本中会提示输入mysql的hostname(本机就用localhost)、自定义的hive元数据库名、用户名和密码
15、只要不更改安装位置,重复执行setup.sh即可重装整套软件。若更改安装位置,需手动清空/etc/profile的hadoop、hive环境变量,再执行setup.sh
16、已按上面说明操作,仍然安装出错可能存在的原因:
(1)环境变量配置异常:检查/etc/profile
(2)检查配置文件格式:jvm.conf与env.conf
(3)未在setup.sh所在目录执行脚本:cd到ardh-spark目录
二、安装架构
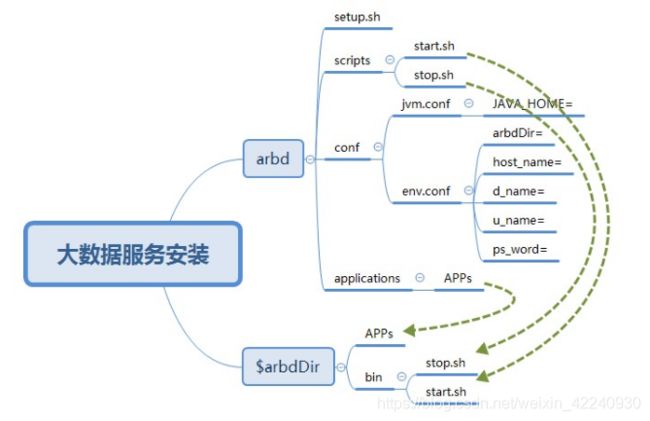
三、配置列表:
以下配置中带$的变量脚本中都会自行使用当前服务器实际值或配置值替换,除$JAVA_HOME外$带_的变量为手动输入的参数
(一)、hadoop部分
1、core-site.xml
fs.defaultFS
hdfs://$hostname:8020
hadoop.tmp.dir
${arbdDir}/hadoop-2.7.3/data/tmp
2、hadoop-env.sh
export JAVA_HOME=$JAVA_HOME
export HADOOP_CONF_DIR=${arbdDir}/hadoop-2.7.3/etc/hadoop/3、hdfs-site.xml
dfs.replication
1
dfs.namenode.name.dir
${arbdDir}/hadoop-2.7.3/data/namenode
dfs.datanode.data.dir
${arbdDir}/hadoop-2.7.3/data/datanode
dfs.permissions
false
dfs.webhdfs.enabled
true
4、mapred-env.sh
export JAVA_HOME=$JAVA_HOME5、mapred-site.xml
mapreduce.framework.name
yarn
6、slaves
$hostname7、yarn-env.sh
export JAVA_HOME=$JAVA_HOME8、yarn-site.xml
yarn.resourcemanager.address
$hostname:8032
yarn.nodemanager.aux-services
mapreduce_shuffle
9、hadoop-daemon.sh
HADOOP_PID_DIR=${arbdDir}/hadoop-2.7.3/pids10、yarn-deamon.sh
YARN_PID_DIR=${arbdDir}/hadoop-2.7.3/pids(二)、hive部分
1、hive-env.sh
HADOOP_HOME=${arbdDir}/hadoop-2.7.3
export HIVE_CONF_DIR=${arbdDir}/hive-1.1.0/conf2、hive-site.xml
javax.jdo.option.ConnectionURL
jdbc:mysql://$host_name:3306/$database_name?createDatabaseIfNotExist=true&useSSL=false
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
$user_name
javax.jdo.option.ConnectionPassword
$pass_word
hive.querylog.location
${arbdDir}/hive-1.1.0/tmp/username
hive.exec.local.scratchdir
${arbdDir}/hive-1.1.0/tmp/username
hive.downloaded.resources.dir
${arbdDir}/hive-1.1.0/tmp/${hive.session.id}_resources
hive.server2.logging.operation.log.location
${arbdDir}/hive-1.1.0/tmp/logs
3、创建hadoop配置文件(core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml)软连接到hive/conf下
ln -sf ${arbdDir}/hadoop-2.7.3/etc/hadoop/core-site.xml ${arbdDir}/hive-1.1.0/conf/core-site.xml
ln -sf ${arbdDir}/hadoop-2.7.3/etc/hadoop/hdfs-site.xml ${arbdDir}/hive-1.1.0/conf/hdfs-site.xml
ln -sf ${arbdDir}/hadoop-2.7.3/etc/hadoop/yarn-site.xml ${arbdDir}/hive-1.1.0/conf/yarn-site.xml
ln -sf ${arbdDir}/hadoop-2.7.3/etc/hadoop/mapred-site.xml ${arbdDir}/hive-1.1.0/conf/mapred-site.xml4、lib目录下添加
mysql-connector-java-5.1.38-bin.jar(三)、sqoop部分
1、sqoop-env.sh
export HADOOP_COMMON_HOME=${arbdDir}/hadoop-2.7.3
export HADOOP_MAPRED_HOME=${arbdDir}/hadoop-2.7.32、lib目录下添加
ojdbc5.jar(四)、spark部分
1、spark-env.sh
export SPARK_PID_DIR=${arbdDir}/spark-2.3.0/pids
export JAVA_HOME=$JAVA_HOME
#export SCALA_HOME=${arbdDir}/scala-2.11.8
export HADOOP_HOME=${arbdDir}/hadoop-2.7.3
SPARK_LOCAL_IP=$localIP
SPARK_CONF_DIR=${arbdDir}/spark-2.3.0/conf
HADOOP_CONF_DIR=${arbdDir}/hadoop-2.7.3/etc/hadoop
YARN_CONF_DIR=${arbdDir}/hadoop-2.7.3/etc/hadoop
SPARK_MASTER_HOST=$hostname2、slaves
$hostname3、创建hive-site.xml配置文件软连接到spark/conf下
ln -sf ${arbdDir}/hive-1.1.0/conf/hive-site.xml ${arbdDir}/spark-2.3.0/conf/hive-site.xml(五)、livy部分
1、livy-env.sh
SPARK_HOME=${arbdDir}/spark-2.3.0
HADOOP_CONF_DIR=${arbdDir}/hadoop-2.7.3/etc/hadoop
LIVY_PID_DIR=${arbdDir}/livy/pids四、脚本原文
(1)setup.sh
#!/bin/bash
source /etc/profile
lpath=$(pwd)
arbd1='JAVA_HOME=/usr/java/jdk1.8.0_181'
arbd2='HADOOP_HOME=/opt/arbd/hadoop-2.7.3'
arbd3='PATH=$JAVA_HOME/bin:$PATH'
arbd4='CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar'
arbd5='export JAVA_HOME PATH CLASSPATH'
check_user(){
if [ "$EUID" == "0" ]
then
echo "当前用户为root"
else
echo "请切换至root用户"
read -p "ctrl+c退出"
clear
exit
fi
}
input_javahome(){
chmod 777 ./conf/jvm.conf
#为避免JAVA_HOME与系统环境变量JAVA_HOME冲突,不采用source方式加载配置文件
#source ./conf/jvm.conf
JAVAHOME=`cat ./conf/jvm.conf | grep JAVA_HOME | awk -F'=' '{ print $2 }'`
if [ ! $JAVAHOME ]
then
echo "./conf/jvm.conf未配置JAVA_HOME参数"
echo "默认值JAVA_HOME=$JAVA_HOME"
check_javahome
JAVA_HOME=$JAVA_HOME
sleep 1
else
echo "将使用配置文件jvm.conf安装,JAVA_HOME参数值为:$JAVAHOME"
JAVA_HOME=$JAVAHOME
sleep 1
fi
echo "是否输入并应用新的JAVA_HOME?(ctrl+Backspace为删除)"
echo "是==>输入新的JAVA_HOME 否==>直接回车"
read read1
if [ "$read1" = "" ]
then
JAVA_HOME=$JAVA_HOME
else
while !([[ "$read1" =~ ^/ ]])
do
echo "路径错误,请输入正确的绝对路径"
read read1
done
JAVA_HOME=$read1
echo "配置文件jvm.conf已更新"
echo "将使用新的JAVA_HOME=$JAVA_HOME进行安装"
sed -i 's#JAVA_HOME.*#JAVA_HOME='"$JAVA_HOME"'#g' ./conf/jvm.conf
fi
}
input_arbdDir(){
chmod 777 ./conf/env.conf
source ./conf/env.conf
#否则换行符严重影响后续操作
arbdDir=$(echo $arbdDir | sed 's/\r//')
if [ ! $arbdDir ]
then
echo $arbdDir
echo "./conf/env.conf未配置安装位置参数"
echo "将使用默认安装位置/data/arbd进行安装"
arbdDir=/data/arbd
sleep 1
else
echo "读取配置文件env.conf"
echo "将使用配置文件arbdDir=$arbdDir进行安装"
arbdDir=$(echo $arbdDir | sed 's/\r//')
sleep 1
fi
echo "是否输入新的安装位置?(ctrl+Backspace为删除)"
echo "是==>输入一个绝对路径(结尾不带/) 否==>直接回车"
read read2
if [ "$read2" = "" ]
then
arbdDir=$(echo $arbdDir | sed 's/\r//')
else
while !([[ "$read2" =~ ^/ ]])
do
echo "路径错误,请输入正确的绝对路径"
read read2
done
arbdDir=$read2
echo "配置文件env.conf已更新"
echo "将使用新的路径arbdDir=$arbdDir进行安装"
sed -i 's#arbdDir.*#arbdDir='"$arbdDir"'#g' ./conf/env.conf
fi
sleep 1
if [ -d "$arbdDir" ] ; then
echo "文件夹$arbdDir存在!"
else
echo "文件夹$arbdDir不存在,正在创建..."
arbdDir=$(echo $arbdDir | sed 's/\r//')
mkdir -p $arbdDir
fi
arbdDir=$(echo $arbdDir | sed 's/\r//')
echo "设置安装位置中。。。"
sleep 1
chmod 777 ./scripts/start.sh
chmod 777 ./scripts/stop.sh
sed -i 's#arbdDir=.*#arbdDir='"$arbdDir"'#g' ./scripts/start.sh
sed -i 's#arbdDir=.*#arbdDir='"$arbdDir"'#g' ./scripts/stop.sh
sleep 1
sed -i '/>hadoop.tmp.dir'"$arbdDir"'/hadoop-2.7.3/data/tmp|}' ./applications/hadoop-2.7.3/etc/hadoop/core-site.xml
sleep 0.5
sed -i 's#HADOOP_CONF_DIR=.*#HADOOP_CONF_DIR='"$arbdDir"'/hadoop-2.7.3/etc/hadoop/#g' ./applications/hadoop-2.7.3/etc/hadoop/hadoop-env.sh
sleep 0.5
sed -i '/>dfs.namenode.name.dir'"$arbdDir"'/hadoop-2.7.3/data/namenode|}' ./applications/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
sleep 0.5
sed -i '/>dfs.datanode.data.dir'"$arbdDir"'/hadoop-2.7.3/data/datanode|}' ./applications/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
sleep 0.5
sed -i 's#export HIVE_CONF_DIR=.*#export HIVE_CONF_DIR='"$arbdDir"'/hive-1.1.0/conf#g' ./applications/hive-1.1.0/conf/hive-env.sh
sleep 0.5
sed -i 's#HADOOP_HOME=.*#HADOOP_HOME='"$arbdDir"'/hadoop-2.7.3#g' ./applications/hive-1.1.0/conf/hive-env.sh
sleep 0.5
sed -i '#>hive.querylog.location<#{n;s|.*| '"$arbdDir"'/hive-1.1.0/tmp/username |}' ./applications/hive-1.1.0/conf/hive-site.xml
sleep 0.5
sed -i '#>hive.exec.local.scratchdir<#{n;s|.*| '"$arbdDir"'/hive-1.1.0/tmp/username |}' ./applications/hive-1.1.0/conf/hive-site.xml
sleep 0.5
sed -i '#>hive.downloaded.resources.dir<#{n;s|.*| '"$arbdDir"'/hive-1.1.0/tmp/${hive.session.id}_resources |}' ./applications/hive-1.1.0/conf/hive-site.xml
sleep 0.5
sed -i '#>hive.server2.logging.operation.log.location<#{n;s|.*| '"$arbdDir"'/hive-1.1.0/tmp/logs |}' ./applications/hive-1.1.0/conf/hive-site.xml
sleep 0.5
sed -i 's#export HADOOP_COMMON_HOME=.*#export HADOOP_COMMON_HOME='"$arbdDir"'/hadoop-2.7.3#g' ./applications/sqoop-1.4.6/conf/sqoop-env.sh
sleep 0.5
sed -i 's#export HADOOP_MAPRED_HOME=.*#export HADOOP_MAPRED_HOME='"$arbdDir"'/hadoop-2.7.3#g' ./applications/sqoop-1.4.6/conf/sqoop-env.sh
sleep 0.5
sed -i 's#HADOOP_HOME=.*#HADOOP_HOME='"$arbdDir"'/hadoop-2.7.3#g' ./applications/spark-2.3.0/conf/spark-env.sh
sleep 0.5
sed -i 's#SPARK_CONF_DIR=.*#SPARK_CONF_DIR='"$arbdDir"'/spark-2.3.0/conf#g' ./applications/spark-2.3.0/conf/spark-env.sh
sleep 0.5
sed -i 's#HADOOP_CONF_DIR=.*#HADOOP_CONF_DIR='"$arbdDir"'/hadoop-2.7.3/etc/hadoop#g' ./applications/spark-2.3.0/conf/spark-env.sh
sleep 0.5
sed -i 's#YARN_CONF_DIR=.*#YARN_CONF_DIR='"$arbdDir"'/hadoop-2.7.3/etc/hadoop#g' ./applications/spark-2.3.0/conf/spark-env.sh
sleep 0.5
sed -i 's#SPARK_HOME=.*#SPARK_HOME='"$arbdDir"'/spark-2.3.0#g' ./applications/livy/conf/livy-env.sh
sleep 0.5
sed -i 's#HADOOP_CONF_DIR=.*#HADOOP_CONF_DIR='"$arbdDir"'/hadoop-2.7.3/etc/hadoop#g' ./applications/livy/conf/livy-env.sh
}
host_conf(){
echo "正在更改配置中hostname为当前主机名:$(hostname)..."
sed -i "/>fs.defaultFShdfs://$(hostname):8020|}" $arbdDir/hadoop-2.7.3/etc/hadoop/core-site.xml
#sleep 0.5
#sed -i "/>dfs.namenode.http-address$(hostname):50070|}" $arbdDir/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
sleep 0.5
sed -i "/>yarn.resourcemanager.address$(hostname):8032|}" $arbdDir/hadoop-2.7.3/etc/hadoop/yarn-site.xml
sleep 0.5
sed -i "s/localhost/$(hostname)/" $arbdDir/hadoop-2.7.3/etc/hadoop/slaves
sleep 0.5
#sed -i "/>hive.metastore.uristhrift://$(hostname):9083|}" $arbdDir/hive-1.1.0/conf/hive-site.xml
sleep 0.5
sed -i "s/localhost/$(hostname)/" $arbdDir/spark-2.3.0/conf/slaves
sleep 0.5
local_ip=$(/sbin/ifconfig -a|grep inet|grep -v 127.0.0.1|grep -v inet6|awk '{print $2}'|tr -d "addr:")
sed -i "s/SPARK_LOCAL_IP=.*/SPARK_LOCAL_IP=${local_ip}/" $arbdDir/spark-2.3.0/conf/spark-env.sh
sleep 0.5
sed -i "s/SPARK_MASTER_HOST=.*/SPARK_MASTER_HOST=$(hostname)/" $arbdDir/spark-2.3.0/conf/spark-env.sh
}
check_cp(){
arbdDir=$(echo $arbdDir | sed 's/\r//')
if [[ $(jps) =~ " NameNode" || $(jps) =~ "Worker" && $(jps) =~ "NodeManager" ]]
then
echo "关闭集群中..."
source $arbdDir/bin/stop.sh
fi
sleep 1
if [ -d "$arbdDir" ] ; then
echo "文件夹$arbdDir存在!正在拷贝hadoop至$arbdDir..."
\cp -rf $(pwd)/applications/hadoop-2.7.3 $arbdDir/
sleep 1
echo "正在拷贝hive至$arbdDir..."
\cp -rf $(pwd)/applications/hive-1.1.0 $arbdDir/
sleep 1
echo "正在拷贝sqoop至$arbdDir..."
\cp -rf $(pwd)/applications/sqoop-1.4.6 $arbdDir/
sleep 1
echo "正在拷贝spark至$arbdDir..."
\cp -rf $(pwd)/applications/spark-2.3.0 $arbdDir/
sleep 1
echo "正在拷贝livy至$arbdDir..."
\cp -rf $(pwd)/applications/livy $arbdDir/
sleep 1
echo "拷贝完毕"
else
echo "文件夹$arbdDir不存在,正在创建..."
mkdir $arbdDir
echo "文件夹$arbdDir创建完毕,正在拷贝hadoop至$arbdDir..."
\cp -rf $(pwd)/applications/hadoop-2.7.3 $arbdDir/
sleep 1
echo "正在拷贝hive至$arbdDir..."
\cp -rf $(pwd)/applications/hive-1.1.0 $arbdDir/
sleep 1
echo "正在拷贝sqoop至$arbdDir..."
\cp -rf $(pwd)/applications/sqoop-1.4.6 $arbdDir/
sleep 1
echo "正在拷贝spark至$arbdDir..."
\cp -rf $(pwd)/applications/spark-2.3.0 $arbdDir/
sleep 1
echo "正在拷贝livy至$arbdDir..."
\cp -rf $(pwd)/applications/livy $arbdDir/
sleep 1
echo "拷贝完毕"
fi
if [ -d "$arbdDir/bin" ] ; then
echo "文件夹$arbdDir/bin存在!"
else
echo "文件夹$arbdDir/bin不存在,正在创建..."
arbdDir=$(echo $arbdDir | sed 's/\r//')
mkdir -p $arbdDir/bin
fi
echo "正在拷贝start.sh/stop.sh至$arbdDir/bin..."
\cp -rf ./scripts/start.sh $arbdDir/bin/
\cp -rf ./scripts/stop.sh $arbdDir/bin/
echo "完毕"
}
check_javahome(){
if [ "$JAVA_HOME" = "" ]
then
echo "未配置JAVA_HOME环境变量!手动在/etc/profile中配置!"
read -p "按回车键退出"
clear
exit 1
fi
if [ "$JAVA_HOME" != "" ]
then
JAVA_HOME=$JAVA_HOME
echo "JAVA_HOME:$JAVA_HOME"
fi
}
check_fwall(){
echo "注:防火墙检查功能暂不支持ubuntu系统"
service iptables status 1>/dev/null 2>&1
if [[ $? -ne 0 && `firewall-cmd --state` != 'running' ]]; then
echo "防火墙已关闭"
else
read -p "防火墙未关闭,关闭防火墙及selinux请按回车" comde
echo "正在关闭防火墙..."
echo "----本操作若提示xxx not (be) found、没有那个文件或目录为正常现象----"
/sbin/service iptables stop
/sbin/chkconfig iptables off
/sbin/service iptables status
systemctl stop firewalld.service
systemctl disable firewalld.service
firewall-cmd --state
setenforce 0
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
echo "防火墙已关闭-------------------------------------------------------"
fi
#ufw status
#wfw disable
}
auth_load(){
read -p "是否配置单节点免密登陆?:(y/n)" startnow
while !([ "$startnow" = "Y" ]||[ "$startnow" = "y" ]||[ "$startnow" = "N" ]||[ "$startnow" = "n" ])
do
echo "输入错误,请输入大写或者小写的y或n"
read startnow
done
if [ "$startnow" = "Y" ]||[ "$startnow" = "y" ]
then
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
fi
}
java_export(){
echo ${arbd1}>>/etc/profile
echo ${arbd3}>>/etc/profile
echo ${arbd4}>>/etc/profile
echo ${arbd5}>>/etc/profile
sleep 1
echo "jdk1.8配置完成"
source /etc/profile
echo "环境变量生效"
}
java_install(){
if [ -d "/usr/java" ] ; then
echo "文件夹/usr/java存在!正在拷贝数据至/usr/java..."
\cp -rf $(pwd)/applications/jdk1.8.0_181 /usr/java/jdk1.8.0_181
sleep 1
java_export
else
echo "文件夹/usr/java不存在!正在创建...正在拷贝数据至/usr/java..."
mkdir /usr/java
echo "正在拷贝数据至/usr/java..."
\cp -rf $(pwd)/applications/jdk1.8.0_181 /usr/java/jdk1.8.0_181
sleep 1
java_export
fi
}
java_conf(){
sed -i "s#^export JAVA_HOME=.*#export JAVA_HOME=$JAVA_HOME#" $arbdDir/hadoop-2.7.3/etc/hadoop/hadoop-env.sh
sleep 1
sed -i "s#^export JAVA_HOME=.*#export JAVA_HOME=$JAVA_HOME#" $arbdDir/hadoop-2.7.3/etc/hadoop/mapred-env.sh
sleep 1
sed -i "s#^export JAVA_HOME=.*#export JAVA_HOME=$JAVA_HOME#" $arbdDir/hadoop-2.7.3/etc/hadoop/yarn-env.sh
echo "HADOOP配置完成"
sleep 1
sed -i "s#^export JAVA_HOME=.*#export JAVA_HOME=$JAVA_HOME#" $arbdDir/spark-2.3.0/conf/spark-env.sh
echo "SPARK配置完成"
sleep 1
}
check_jdk(){
check_results=`java -version 2>&1`
if [[ $check_results =~ 'version "1.8' ]]
then
echo "当前jdk版本为1.8,符合要求"
else
echo "jdk版本需要1.8,请安装jdk1.8"
while true
do
echo "-------------请选择操作--------------"
echo "1)退出shell后,手动更改jdk版本。*建议*"
echo "2)shell脚本自动安装并配置jdk1.8*请勿重复安装*"
echo "0)跳过。注:jdk版本低于1.8将导致spark不可用"
echo "-------------------------------------"
read -p "请选择 : " comdk
case $comdk in
1)
break
;;
2)
java_install
;;
0)
break
;;
*)
continue
;;
esac
echo "操作完成,请按回车键继续..."
read t
break
done
fi
}
hadoop_export(){
if grep -q '$HADOOP_HOME/bin' /etc/profile && grep -q '$HADOOP_HOME/sbin' /etc/profile
then
echo 'HADOOP_HOME已配置'
elif grep -q '$JAVA_HOME/bin:' /etc/profile
then
echo "正在添加hadoop环境变量..."
sed -i '/JAVA_HOME=/a\zrarbd-' /etc/profile
sleep 1
echo "正在添加hive环境变量..."
sed -i 's#zrarbd-#HADOOP_HOME='"$arbdDir"'/hadoop-2.7.3\nHIVE_HOME='"$arbdDir"'/hive-1.1.0#' /etc/profile
#sed -i 's#zrarbd-#HADOOP_HOME=/opt/arbd/hadoop-2.7.3#' /etc/profile
sleep 1
sed -i 's#$JAVA_HOME/bin:#$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:#g' /etc/profile
sleep 1
sed -i '/$JAVA_HOME\/bin:/a\export HADOOP_HOME HIVE_HOME' /etc/profile
sleep 0.5
source /etc/profile
echo "环境变量生效"
elif grep -q ':$JAVA_HOME/bin' /etc/profile
then
echo "正在添加hadoop环境变量..."
sed -i '/JAVA_HOME=/a\zrarbd-' /etc/profile
sleep 1
echo "正在添加hive环境变量..."
sed -i 's#zrarbd-#HADOOP_HOME='"$arbdDir"'/hadoop-2.7.3\nHIVE_HOME='"$arbdDir"'/hive-1.1.0#' /etc/profile
#sed -i 's#zrarbd-#HADOOP_HOME='"$arbdDir"'/hadoop-2.7.3#' /etc/profile
sleep 1
sed -i 's#:$JAVA_HOME/bin#:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin#g' /etc/profile
sleep 1
sed -i '/:$JAVA_HOME\/bin/a\export HADOOP_HOME HIVE_HOME' /etc/profile
sleep 1
source /etc/profile
echo "环境变量生效"
else
echo '错误!请正确配置JAVA_HOME和PATH!'
fi
}
hadoop_format(){
if [ -d "$arbdDir/hadoop-2.7.3/data/datanode" ] ; then
echo "$arbdDir/hadoop-2.7.3/data/datanode已存在,正在删除"
rm -rf $arbdDir/hadoop-2.7.3/data/datanode/*
ls $arbdDir/hadoop-2.7.3/data/datanode/
fi
if [ -d "$arbdDir/hadoop-2.7.3/data/namenode" ] ; then
echo "$arbdDir/hadoop-2.7.3/data/namenode已存在,正在删除"
rm -rf $arbdDir/hadoop-2.7.3/data/namenode/*
ls $arbdDir/hadoop-2.7.3/data/namenode/
fi
rm -rf $arbdDir/hadoop-2.7.3/data/tmp/*
ls $arbdDir/hadoop-2.7.3/data/tmp/
sleep 1
echo "已删除临时文件"
sleep 1
echo "开始初始化Hadoop"
sleep 1
cd $arbdDir/hadoop-2.7.3
yes | hdfs namenode -format
echo "初始化Hadoop完成"
cd $lpath
sleep 1
}
check_jps(){
echo "检查jps进程中..."
if [[ $(jps) =~ " NameNode" && $(jps) =~ "SecondaryNameNode" && $(jps) =~ "DataNode" ]]
then
echo "HDFS启动成功"
elif [[ $(jps) =~ " NameNode" ]]
then
echo "DataNode启动失败"
else
echo "NameNode启动失败"
fi
if [[ $(jps) =~ "NodeManager" && $(jps) =~ "ResourceManager" ]]
then
echo "YARN启动成功"
elif [[ $(jps) =~ "NodeManager" ]]
then
echo "ResourceManager启动失败"
else
echo "NodeManager启动失败"
fi
if [[ $(jps) =~ "Master" && $(jps) =~ "Worker" ]]
then
echo "SPARK启动成功"
elif [[ $(jps) =~ "Master" ]]
then
echo "Worker启动失败"
else
echo "Master启动失败"
fi
if [[ $(jps) =~ "LivyServer" ]]
then
echo "Livy启动成功"
else
echo "Livy启动失败"
fi
}
run_test(){
echo "正在HDFS功能测试(若无报错则功能正常),请稍后..."
$arbdDir/hadoop-2.7.3/bin/hdfs dfs -mkdir /testInput
sleep 1
$arbdDir/hadoop-2.7.3/bin/hdfs dfs -put $arbdDir/hadoop-2.7.3/README.txt /testInput
sleep 1
echo "正在运行MR任务测试,请稍后..."
$arbdDir/hadoop-2.7.3/bin/yarn jar $arbdDir/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /testInput /testOutput
sleep 1
echo "WordCount测试结果:"
$arbdDir/hadoop-2.7.3/bin/hdfs dfs -cat /testOutput/*
sleep 1
$arbdDir/hadoop-2.7.3/bin/hdfs dfs -rm -r /testInput
$arbdDir/hadoop-2.7.3/bin/hdfs dfs -rm -r /testOutput
sleep 1
echo "正在使用spark自带jar包运行测试,请稍后..."
if [[ $($arbdDir/spark-2.3.0/bin/run-example SparkPi 2>&1 | grep "Pi is") =~ "Pi is roughly 3.1" ]]
then
echo "spark jar包结果达到预期,功能测试正常"
else
$arbdDir/spark-2.3.0/bin/run-example SparkPi
echo "spark功能测试异常"
read -p "按回车键退出"
clear
fi
#echo "正在测试sqoop功能..."
echo "正在测试hive功能..."
if [[ $host_name == ''||$u_name == ''||$ps_word == ''||$d_name == '' ]] ; then
read -p "请输入mysql数据库主机名(本机请输入localhost):" host_name
read -p "请输入自定义的mysql中hive的元数据库名称:" d_name
read -p "请输入mysql数据库用户名:" u_name
read -p "请输入mysql数据库密码:" ps_word
fi
$arbdDir/hive-1.1.0/bin/hive -e "show tables;"
mysql -h${host_name} -u${u_name} -p${ps_word} -e "desc ${d_name}.TABLE_PARAMS;" 2>&1 | grep "doesn't exist"
rtstatus=$?
echo $rtstatus
if [ $rtstatus -ne 0 ]; then
echo "hive配置mysql元数据库成功!"
else
echo "hive配置mysql元数据库失败!"
fi
}
hive_conf(){
host_name=$(echo $host_name | sed 's/\r//')
if [ ! $host_name ]
then
echo "未配置mysql数据库主机名"
read -p "请输入mysql数据库主机名(本机请输入localhost):" host_name
echo "配置文件env.conf已更新"
sed -i 's#host_name.*#host_name='"$host_name"'#g' ./conf/env.conf
else
echo "将使用配置文件host_name=$host_name进行安装"
host_name=$(echo $host_name | sed 's/\r//')
sleep 1
fi
d_name=$(echo $d_name | sed 's/\r//')
if [ ! $d_name ]
then
echo "未配置hive的元数据库名称"
read -p "请输入自定义的mysql中hive的元数据库名称(如hive):" d_name
echo "配置文件env.conf已更新"
sed -i 's#d_name.*#d_name='"$d_name"'#g' ./conf/env.conf
else
echo "将使用配置文件d_name=$d_name进行安装"
d_name=$(echo $d_name | sed 's/\r//')
sleep 1
fi
u_name=$(echo $u_name | sed 's/\r//')
if [ ! $u_name ]
then
echo "未配置mysql数据库用户名"
read -p "请输入mysql数据库用户名:" u_name
echo "配置文件env.conf已更新"
sed -i 's#u_name.*#u_name='"$u_name"'#g' ./conf/env.conf
else
echo "将使用配置文件u_name=$u_name进行安装"
u_name=$(echo $u_name | sed 's/\r//')
sleep 1
fi
ps_word=$(echo $ps_word | sed 's/\r//')
if [ ! $ps_word ]
then
echo "未配置mysql数据库密码"
read -p "请输入mysql数据库密码" ps_word
echo "配置文件env.conf已更新"
sed -i 's#ps_word.*#ps_word='"$ps_word"'#g' ./conf/env.conf
else
echo "将使用配置文件ps_word=$ps_word进行安装"
ps_word=$(echo $ps_word | sed 's/\r//')
sleep 1
fi
sleep 1
#read -p "请输入mysql数据库主机名(本机请输入localhost):" host_name
#read -p "请输入自定义的mysql中hive的元数据库名称(如hive):" d_name
sed -i "/>javax.jdo.option.ConnectionURLjdbc:mysql://${host_name}:3306/${d_name}?createDatabaseIfNotExist=true\&useSSL=false|}" $arbdDir/hive-1.1.0/conf/hive-site.xml
#read -p "请输入mysql数据库用户名:" u_name
sed -i "/>javax.jdo.option.ConnectionUserName${u_name}|}" $arbdDir/hive-1.1.0/conf/hive-site.xml
#read -p "请输入mysql数据库密码" ps_word
sed -i "/>javax.jdo.option.ConnectionPassword${ps_word}|}" $arbdDir/hive-1.1.0/conf/hive-site.xml
sleep 1
echo "创建软连接hive-site.xml到spark/conf"
ln -sf $arbdDir/hive-1.1.0/conf/hive-site.xml $arbdDir/spark-2.3.0/conf/hive-site.xml
echo "创建hadoop配置软连接到hive/conf"
ln -sf $arbdDir/hadoop-2.7.3/etc/hadoop/core-site.xml $arbdDir/hive-1.1.0/conf/core-site.xml
ln -sf $arbdDir/hadoop-2.7.3/etc/hadoop/hdfs-site.xml $arbdDir/hive-1.1.0/conf/hdfs-site.xml
ln -sf $arbdDir/hadoop-2.7.3/etc/hadoop/yarn-site.xml $arbdDir/hive-1.1.0/conf/yarn-site.xml
ln -sf $arbdDir/hadoop-2.7.3/etc/hadoop/mapred-site.xml $arbdDir/hive-1.1.0/conf/mapred-site.xml
sleep 1
echo "连接mysql创建元数据库中..."
echo "若提示ERROR Can't drop database '${d_name}'; database doesn't exist为正常现象"
mysql -h${host_name} -u${u_name} -p${ps_word} -e "drop database ${d_name};"
mysql -h${host_name} -u${u_name} -p${ps_word} -e "create database ${d_name} character set latin1;"
sleep 1
mysql -h${host_name} -u${u_name} -p${ps_word} -e "GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '${ps_word}' WITH GRANT OPTION;"
mysql -h${host_name} -u${u_name} -p${ps_word} -e "FLUSH PRIVILEGES;"
echo "创建元数据库完成"
}
start_now(){
read -p "是保持集群启动状态?:(y/n)" startnow
while !([ "$startnow" = "Y" ]||[ "$startnow" = "y" ]||[ "$startnow" = "N" ]||[ "$startnow" = "n" ])
do
echo "输入错误,请输入大写或者小写的y或n"
read startnow
done
#if [ "$startnow" = "Y" ]||[ "$startnow" = "y" ]
#then
# source $arbdDir/bin/start.sh
#fi
if [ "$startnow" = "N" ]||[ "$startnow" = "n" ]
then
source $arbdDir/bin/stop.sh
fi
}
check_conf(){
echo "******************************正式安装前请确认**********************************"
echo "*** 1、已使用source方式执行此脚本!!!!! (source ./setup.sh)* *"
echo "*** 2、已检查过conf目录配置文件内容! (脚本输入 > 配置 > 脚本自动获取)* *"
echo "*** 3、已配置正确的hostname (hostname前面不可跟回环地址127.0.0.1)* *"
echo "********************************************************************************"
read -p "是否已按上述要求进行操作?:(y/n)" startnow
while !([ "$startnow" = "Y" ]||[ "$startnow" = "y" ]||[ "$startnow" = "N" ]||[ "$startnow" = "n" ])
do
echo "输入错误,请输入大写或者小写的y或n"
read startnow
done
if [ "$startnow" = "Y" ]||[ "$startnow" = "y" ]
then
clear
fi
if [ "$startnow" = "N" ]||[ "$startnow" = "n" ]
then
exit
fi
}
check_conf
check_user
input_javahome
input_arbdDir
check_jdk
check_fwall
auth_load
check_cp
hadoop_export
java_conf
host_conf
hadoop_format
hive_conf
source $arbdDir/bin/start.sh
run_test
start_now(2)start.sh
#!/bin/bash
arbdDir=
check_jps(){
echo "检查jps进程中..."
if [[ $(jps) =~ " NameNode" && $(jps) =~ "SecondaryNameNode" && $(jps) =~ "DataNode" ]]
then
echo "HDFS启动成功"
elif [[ $(jps) =~ " NameNode" ]]
then
echo "DataNode启动失败"
else
echo "NameNode启动失败"
fi
if [[ $(jps) =~ "NodeManager" && $(jps) =~ "ResourceManager" ]]
then
echo "YARN启动成功"
elif [[ $(jps) =~ "NodeManager" ]]
then
echo "ResourceManager启动失败"
else
echo "NodeManager启动失败"
fi
if [[ $(jps) =~ "Master" && $(jps) =~ "Worker" ]]
then
echo "SPARK启动成功"
elif [[ $(jps) =~ "Master" ]]
then
echo "Worker启动失败"
else
echo "Master启动失败"
fi
if [[ $(jps) =~ "LivyServer" ]]
then
echo "Livy启动成功"
else
echo "Livy启动失败"
fi
}
all_start(){
echo "hadoop启动中。。。"
echo "**********若为第一次启动,需按提示输入两次yes**********"
$arbdDir/hadoop-2.7.3/sbin/start-all.sh
echo "spark启动中。。。"
$arbdDir/spark-2.3.0/sbin/start-all.sh
echo "livy启动中。。。"
$arbdDir/livy/bin/livy-server start
}
all_start
check_jps(3)stop.sh
#!/bin/bash
arbdDir=
check_jps(){
echo "检查jps进程中..."
if [[ $(jps) =~ " NameNode" || $(jps) =~ "SecondaryNameNode" || $(jps) =~ "DataNode" ]]
then
echo "HDFS未关闭"
else
echo "HDFS已关闭"
fi
if [[ $(jps) =~ "NodeManager" || $(jps) =~ "ResourceManager" ]]
then
echo "YARN未关闭"
else
echo "YARN已关闭"
fi
if [[ $(jps) =~ "Master" || $(jps) =~ "Worker" ]]
then
echo "SPARK未关闭"
else
echo "SPARK已关闭"
fi
if [[ $(jps) =~ "LivyServer" ]]
then
echo "Livy未关闭"
else
echo "Livy已关闭"
fi
}
all_stop(){
echo "livy关闭中。。。"
$arbdDir/livy/bin/livy-server stop
echo "spark关闭中。。。"
$arbdDir/spark-2.3.0/sbin/stop-all.sh
echo "hadoop关闭中。。。"
$arbdDir/hadoop-2.7.3/sbin/stop-all.sh
}
all_stop
check_jps(4)jvm.conf
JAVA_HOME=(5)env.conf
#软件安装位置,绝对路径,末尾不要带/
arbdDir=
#mysql数据库主机名(本机请输入localhost)
host_name=
#自定义的mysql中hive的元数据库名称(如hive)
d_name=
#mysql数据库用户名(如root)
u_name=
#mysql数据库密码
ps_word=