数据备份简介
在信息技术与数据管理领域,备份是指将文件系统或数据库系统中的数据加以复制,一旦发生灾难或者错误操作时,得以方便而及时地恢复系统的有效数据和正常运作。在实际备份过程中,最好将重要数据制作三个或三个以上的备份,并且放置在不同的场所异地备援,以供日后回存之用。
备份有两个不同的目的,其主要的目的是在数据丢失后恢复数据,无论数据是被删除还是被损坏。备份的第二个目的是根据用户定义的数据保留策略从较早的时间恢复数据,通常在备份应用程序中配置需要备份多长时间的数据副本。
由于备份系统至少会包含一个被认为值得保存的所有数据的副本,因此对数据存储的要求可能会很高,组织此存储空间和管理备份过程可能是一项复杂的任务。如今,有许多不同类型的数据存储设备可用于进行备份,还可以通过许多不同的方式来安排这些设备以提供地理冗余,数据安全性和可移植性。
在将数据发送到其存储位置之前,会选择,提取和操作它们,目前已经有许多不同的技术来优化备份过程,其中包括处理打开的文件(open files)和实时数据源的优化,以及压缩,加密和重复数据删除等。每个备份方案都应包括演习过程,以验证正在备份的数据的可靠性,更重要的是要认识到任何备份方案中涉及的限制和人为因素。
Table Store备份需求分析
对于存储系统而言,数据的安全可靠永远是第一位的,要保障数据尽可能高的可靠性,需要从两个方面保障:
- 存储系统本身的数据可靠性:表格存储(Table Store)是阿里云自研的面向海量结构化数据存储的Serverless NoSQL多模型数据库,提供了99.9999999%的数据可靠性保证,在业界属于非常非常高的标准了。
- 误操作后能恢复数据:误操作永远都无法避免,要做的是当误操作发生的时候能尽快恢复,那么就需要有备份数据存在。对于备份,有两种方案,一个是部署同城或异地灾备,这种代价高费用高,更多的用于社会基础信息或金融信息。另一种是将数据备份到另一个价格更低廉的系统,当万一出现误操作的时候,可以有办法恢复就行。一般可以选择文件存储系统,比如阿里云OSS。
Table Store备份恢复方案简介
下图为Table Store备份恢复的逻辑结构图,基于全增量一体的通道服务我们可以很容易的构建一整套的数据备份和数据恢复方案,同时具备了实时增量备份能力和秒级别的恢复能力。只要提前配置好备份和恢复的计划,整个备份恢复系统可以做到完全的自动化进行。

Table Store备份恢复方案实战
目前表格存储虽然未推出官方的备份和恢复功能,但是笔者会step-by-step的带大家基于表格存储的通道服务设计属于自己的专属备份恢复方案,实战步骤会分为备份和恢复两部分。
1. 备份
- 预准备阶段:需要确定待备份的数据源和备份的目的源,在此次的实战中,分别对应着TableStore的表和OSS的Bucket。
- 确定备份计划和策略
- 使用通道服务SDK编写代码
- 执行备份策略并监测备份过程
2. 恢复
- 执行文件恢复
确定备份计划和策略
备份策略需要确定备份内容、备份时间和备份方式,目前常见的备份策略主要有以下几类。
- 全量备份(Full Backup): 把硬盘或数据库内的所有文件、文件夹或数据进行一次性的复制。
- 增量备份(Incremental Backup): 对上一次的全量备份或增量备份后更新的数据进行的备份。
- 差异备份(Differential Backup): 提供运行全量备份后变更文件的备份。
- 选择式备份:对系统数据的一部分进行的备份。
- 冷备份:系统处于停机或维护状态下的备份。这种情况下,备份的数据与系统该时段的数据应该完全一致。
- 热备份:系统处于正常运转状态下的备份。这种情况下,由于系统中的数据可能随时在更新,备份的数据相对于系统的真实数据可能会有一定的滞后。
在此次的实战中,笔者对于备份计划和策略的选择如下(这里可以根据自己的需求进行自定义设计,然后利用通道服务的SDK来完成相应的需求)。
- 备份内容:TableStore 数据表
-
备份时间:
- 全量备份定期执行(时间可调,默认为一周)。
- 增量备份根据配置定期执行,表格存储的通道服务可以保障数据的严格有序性,每个增量文件是流式append的,可随时被消费。
- 备份方式:全量备份+增量备份,热备份。
使用通道服务SDK编写代码
这部分会结合代码片段的形式讲解,详细的代码后续会开源出去(链接会更新在本文中),尽请期待。在进行实战之前,推荐先阅读通道服务Java SDK的 使用文档。
- 创建一个全量+增量类型的Tunnel,这里可以使用SDK或者官网控制台进行创建。
private static void createTunnel(TunnelClient client, String tunnelName) {
CreateTunnelRequest request = new CreateTunnelRequest(TableName, tunnelName, TunnelType.BaseAndStream);
CreateTunnelResponse resp = client.createTunnel(request);
System.out.println("RequestId: " + resp.getRequestId());
System.out.println("TunnelId: " + resp.getTunnelId());
}- 了解通道服务自动化数据处理框架
在通道服务的快速开始里,我们可以看到用户只需要传入处理数据的process函数和shutdown函数即可完成自动化的数据处理。在process函数的入参中会带有List,而StreamRecord包装的正是TableStore里每一行的数据,包括Record的类型,主键列,属性列,用户写入Record的时间戳等。 - 设计TableStore每一行数据的持久化格式
本次实战中我们使用CSV文件格式,当然你也可以用pb或者其它格式,CSV的优点是可读性比较强,每一行数据会对应CSV文件的一行,持久化的格式如下图所示,CSV文件会有四列, TimeStamp列是数据写入TableStore的时间戳(全量时都为0,增量备份为具体的时间戳),RecordType是数据行的操作类型(PUT, UPDATE和DELETE),PrimaryKey为主键列的JSON字符串表示,RecordColumns为属性列的JSON字符串表示。
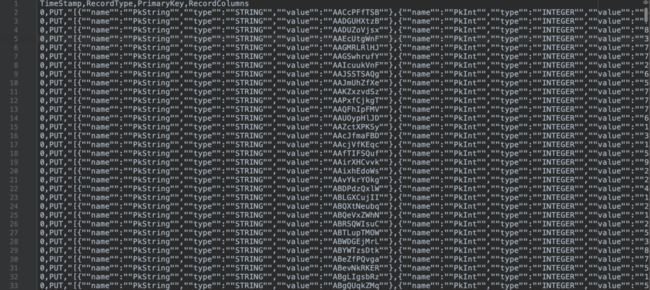
转换部分的核心代码参见如下代码片段,笔者处理这部分用的是univocity-parsers(CSV)和Gson库,有几个地方需要特别注意下:1). Gson反序列化Long类型会转为Number类型,可能会造成进度丢失,有若干解决办法,笔者采用的是将其转为String类型序列化。2). 对于binary类型的数据的特殊处理,笔者进行了base64的编解码。3). 可以直接流式写入OSS中,减少本地持久化的消耗。
this.gson = new GsonBuilder().registerTypeHierarchyAdapter(byte[].class, new ByteArrayToBase64TypeAdapter())
.setLongSerializationPolicy(LongSerializationPolicy.STRING).create();
// ByteArrayOutputStream到ByteArrayInputStream会有一次array.copy, 可考虑用管道或者NIO channel.
public void streamRecordsToOSS(List records, String bucketName, String filename, boolean isNewFile) {
if (records.size() == 0) {
LOG.info("No stream records, skip it!");
return;
}
try {
CsvWriterSettings settings = new CsvWriterSettings();
ByteArrayOutputStream out = new ByteArrayOutputStream();
CsvWriter writer = new CsvWriter(out, settings);
if (isNewFile) {
LOG.info("Write csv header, filename {}", filename);
List headers = Arrays.asList(RECORD_TIMESTAMP, RECORD_TYPE, PRIMARY_KEY, RECORD_COLUMNS);
writer.writeHeaders(headers);
System.out.println(writer.getRecordCount());
}
List totalRows = new ArrayList();
LOG.info("Write stream records, num: {}", records.size());
for (StreamRecord record : records) {
String timestamp = String.valueOf(record.getSequenceInfo().getTimestamp());
String recordType = record.getRecordType().name();
String primaryKey = gson.toJson(
TunnelPrimaryKeyColumn.genColumns(record.getPrimaryKey().getPrimaryKeyColumns()));
String columns = gson.toJson(TunnelRecordColumn.genColumns(record.getColumns()));
totalRows.add(new String[] {timestamp, recordType, primaryKey, columns});
}
writer.writeStringRowsAndClose(totalRows);
// write to oss file
ossClient.putObject(bucketName, filename, new ByteArrayInputStream(out.toByteArray()));
} catch (Exception e) {
e.printStackTrace();
}
} 执行备份策略并监测备份过程
- 运行通道服务的自动化数据框架,挂载上一步中设计的备份策略代码。
public class TunnelBackup {
private final ConfigHelper config;
private final SyncClient syncClient;
private final CsvHelper csvHelper;
private final OSSClient ossClient;
public TunnelBackup(ConfigHelper config) {
this.config = config;
syncClient = new SyncClient(config.getEndpoint(), config.getAccessId(), config.getAccessKey(),
config.getInstanceName());
ossClient = new OSSClient(config.getOssEndpoint(), config.getAccessId(), config.getAccessKey());
csvHelper = new CsvHelper(syncClient, ossClient);
}
public void working() {
TunnelClient client = new TunnelClient(config.getEndpoint(), config.getAccessId(), config.getAccessKey(),
config.getInstanceName());
OtsReaderConfig readerConfig = new OtsReaderConfig();
TunnelWorkerConfig workerConfig = new TunnelWorkerConfig(
new OtsReaderProcessor(csvHelper, config.getOssBucket(), readerConfig));
TunnelWorker worker = new TunnelWorker(config.getTunnelId(), client, workerConfig);
try {
worker.connectAndWorking();
} catch (Exception e) {
e.printStackTrace();
worker.shutdown();
client.shutdown();
}
}
public static void main(String[] args) {
TunnelBackup tunnelBackup = new TunnelBackup(new ConfigHelper());
tunnelBackup.working();
}
}- 监测备份过程
备份过程的监控可以通过表格存储控制台或者 DescribeTunnel 接口完成,DescribeTunnel接口可以实时获取当前Tunnel下每一个Channel的Client(可以自定义), 消费总行数和消费位点等信息。比如用户有下午2点-3点的数据需要同步,若DescribeTunnel获取到的消费位点为下午2点半,则表示备份到一半了,若获取到的消费位点为下午3点,则代表2点-3点的数据已经备份完毕了。
执行文件恢复
在数据备份完成后,我们可以根据需求进行全量的恢复和部分数据的恢复,来降低RTO。在恢复数据时,可以有一些措施来优化恢复的性能:
- 从OSS下载时,可以使用流式下载或者分片下载的方式,必要时可以增加并发。
- 写入TableStore时,可以使用并发BatchWrite的方式。
下图为Restore的实例代码(略去若干细节),首先根据需求算出需要下载的文件名(和备份策略对应),然后用OSS的流式下载读取相应的文件,最后用并发的BatchWrite方式写入TableStore的恢复表中。
public class TunnelRestore {
private ConfigHelper config;
private final SyncClient syncClient;
private final CsvHelper csvHelper;
private final OSSClient ossClient;
public TunnelRestore(ConfigHelper config) {
this.config = config;
syncClient = new SyncClient(config.getEndpoint(), config.getAccessId(), config.getAccessKey(),
config.getInstanceName());
ossClient = new OSSClient(config.getOssEndpoint(), config.getAccessId(), config.getAccessKey());
csvHelper = new CsvHelper(syncClient, ossClient);
}
public void restore(String filename, String tableName) {
csvHelper.parseStreamRecordsFromCSV(filename, tableName);
}
public static void main(String[] args) {
TunnelRestore restore = new TunnelRestore(new ConfigHelper());
restore.restore("FullData-1551767131130.csv", "testRestore");
}
}总结
本文首先介绍了Table Store备份的需求,接着介绍了使用表格存储的通道服务进行数据备份和恢复的原理,最后结合实际的代码片段讲述了如何一步步的构建Tabel Store数据备份恢复方案。
参考链接
本文作者:琸然
本文为云栖社区原创内容,未经允许不得转载。