人脸检测——RetinaFace解读
《RetinaFace: Single-stage Dense Face Localisation in the Wild》
论文地址:https://arxiv.org/pdf/1905.00641.pdf
开源代码:
https://github.com/deepinsight/insightface/tree/master/RetinaFace (mxnet)
https://github.com/1996scarlet/faster-mobile-retinaface
https://github.com/biubug6/Pytorch_Retinaface
https://github.com/bleakie/RetinaDetector
基于caffe-c++的实现:https://github.com/wzj5133329/retinaface_caffe
1、摘要
RetinaFace 是今年(2019年)5月份出现的人脸检测算法,当时取得了state-of-the-art,作者也开源了代码,过去了两个月,目前仅以极其微弱的精度差屈居第二名,但因为第一名的AInnoFace算法(来自北京创新奇智公司)没有开源,所以目前RetinaFace可称得上是目前最强的开源人脸检测算法。
虽然在未受控制的人脸检测方面取得了巨大进步,但野外准确有效的面部定位仍然是一个开放的挑战。这篇文章提出了一个强大的单阶段人脸检测器,名为RetinaFace,它利用联合监督和自我监督的多任务学习,在各种人脸尺度上执行像素方面的人脸定位。具体来说,我们在以下五个方面做出了贡献:
(1)我们在WIDER FACE数据集上手动注释五个面部标志,并在这个额外的监督信号的帮助下观察硬面检测的重要改进。
(2)我们进一步增加了一个自监督网格解码器分支,用于与现有的受控分支并行地预测像素三维形状的面部信息。
(3)在WIDER FACE硬测试装置上,RetinaFace的性能优于现有技术平均预测(AP)1.1%(达到AP等于91.4%)。
(4)在IJB-C测试集上,RetinaFace使最先进的方法(ArcFace)能够改善他们在面部验证中的结果(FAR = 1e-6的TAR = 89.59%)。
(5)通过采用轻量级骨干网络,RetinaFace可以在单个CPU内核上实时运行,以实现VGA分辨率的显示。
2、网络结构
截止2019年8月,原始模型尚未全部开源,目前开源的简化版是基于传统物体检测网络RetinaNet的改进版,添加了SSH网络的检测模块,提升检测精度,作者提供了三种基础网络,基于ResNet的ResNet50和ResNet152版本能提供更好的精度,以及基于mobilenet(0.25)的轻量版本mnet,检测速度更快。
2.1、简化版mnet结构
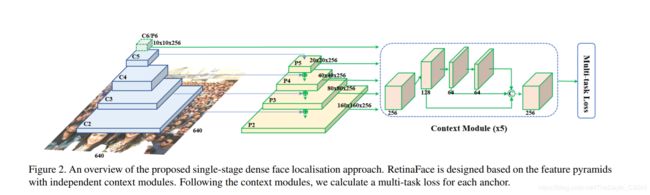
RetinaFace的mnet本质是基于RetinaNet的结构,采用了特征金字塔的技术,实现了多尺度信息的融合,对检测小物体有重要的作用,RetinaNet的结构如下:

简化版的mnet与RetinaNet采用了相同的proposal策略,即保留了在feature pyramid net的3层特征图每一层检测框分别proposal,生成3个不同尺度上的检测框,每个尺度上又引入了不同尺寸的anchor大小,保证可以检测到不同大小的物体。
简化版mnet与RetinaNet的区别除了在于主干网络的选择上使用了mobilenet做到了模型的轻量化,最大的区别在于检测模块的设计。
mnet使用了SSH检测网络的检测模块,SSH检测模块由SSH上下文模块组成。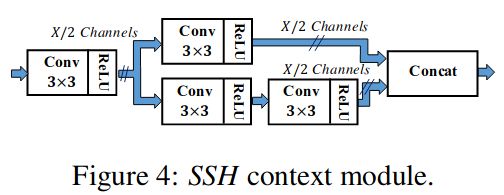
上下文模块的作用是扩张预检测区域的上下文信息。上下文模块和conv叠加后生成分类头和回归头得到网络的输出结合组成了一个检测模块。如下图所示:

mnet网络在使用SSH检测模块的同时实现了多任务学习,即在分类和回归的基础上加入了目标点的回归。官方的网络结构采用了5个目标点的学习,后续也可以修改为更多目标点,比如AFLW中的21个目标点以及常用的68或者106个目标点。
原版RetinaFace论文中的检测分支图如下:
注意:在开源简化版的不包含self-supervision部分,但是有5个关键点的extra-supervision部分

Lcls:人脸分类loss
Lbox:人脸框回归loss
Lpts:人脸关键点回归loss,五点
Lpixel:自监督3D Mesh Renderer稠密人脸回归
特征金字塔网络结构:单阶稠密人脸定位,多任务loss学习。