
阿里妹导读:搜索,推荐和广告是互联网内容提供商进行价值创造的核心业务,在阿里巴巴的电子商务交易平台上,搜索,推荐和广告业务同样具有举足轻重的意义和价值。现在,阿里推荐技术又双叒优化了,新的推荐技术,新的体验,一起来看。
一. 背景
搜索、推荐和广告看似业务形态不同,其实技术组成却是非常相通的。从推荐的视角看,搜索可以认为是一种带query相关性约束的推荐,而广告则是叠加了广告主营销意愿(价格)约束的推荐,所以推荐技术的创新对推动搜索、推荐和广告业务技术的整体发展具有基础性的作用。
从技术演进的角度,推荐算法近年来也在不断地更新换代。从限定在一个有限的历史兴趣范畴内推荐的第一代基于统计的启发式规则方法(代表算法Item-based Collaborative Filtering, Item-CF)到第二代基于内积模型的向量检索方法,推荐技术打开了候选子集检索范围的天花板。然而,向量检索方法限定了内积模型这种用户-商品偏好度量方式,无法容纳更加先进的打分模型(例如带有Attention结构的深度网络)。
为了在全库检索和效率约束的基础上进一步打开推荐技术中模型能力的天花板,此前阿里妈妈精准定向广告业务团队自主提出了新一代任意深度学习+树型全库检索推荐算法(Tree-based Deep Model,TDM),在大规模推荐问题上取得了显著的效果提升。最近,该团队针对大规模推荐问题的研究取得了最新的成果,介绍了如何通过数据驱动的方式,实现模型、索引、检索算法的联合优化。基于这一最新研究成果整理的论文,已经被NeurIPS 2019会议接收。
二. 现有体系存在的问题
如下图所示,在大规模任务中,搜索,推荐和广告的系统通常由模型,索引和检索算法三大组件组成。模型计算单个用户-商品的偏好概率,索引将所有商品有序地组织在一起,检索算法根据模型的输出在索引中召回最终的推荐结果。三者共同决定了召回质量且存在内在联系。

然而,以推荐为例,现有的推荐体系对模型索引和检索的相互联系往往没有做充分的考量。从联合调优这一视角出发,对现有的几代推荐体系的代表算法存在问题分析如下:
1.在Item-CF中,倒排索引根据Item之间某种自定义的相似度量建立,检索过程则是根据用户历史行为在倒排索引中查询候选集后排序截断,模型在排序过程中对候选集中的Item根据某种自定义的规则进行打分。在系统中,模型和检索被规则固化,没有学习调优。
2.在向量检索的模式中,系统会分别为用户和商品学习一个向量表达,其内积作为用户对商品的偏好程度的预测。检索等价于用户向量在商品向量集合中的kNN最近邻检索,在大规模问题中,可以采用近似的最近邻索引结构来加速检索。在建立向量检索推荐系统的过程中,模型训练的目标是准确的预测单个用户-商品的偏好概率,而kNN检索索引建立的目标则最小化近似误差,二者的优化方向并不一致。同时,内积形式的偏好预测表达能力有限,无法容纳更加先进的打分模型。
3.在TDM中,我们通过交替迭代优化模型和树结构再加之无参数的逐层beam search检索过程进行了模型、索引和检索联合优化上的实践和创新。然而在TDM中,模型的优化和树结构索引的学习二者的优化目标也不完全一致,这可能导致二者的优化相互牵制而导致最终整体效果次优。特别是对于树结构索引,模型训练样本的构造和检索路径的选择与树结构具有更加紧密的联系,因此其质量好坏尤为重要。
综上分析,本文针对当前大规模推荐方法中存在的问题,提出了一种统一目标下的模型、索引、检索联合优化的算法JTM(Joint Optimization of Tree-based Index and Deep Model),打破系统各模块独立优化带来的相互掣肘,使得整体推荐效能达到最优。
三. 端到端联合学习的深度树匹配推荐技术
JTM继承了TDM树结构索引+任意深度用户-商品偏好打分模型的系统框架,通过联合优化和层次化特征建模取得了大幅超越TDM的推荐精度。为了更好地理解JTM,我们首先简单了解一下TDM的原理。
3.1 深度树推荐模型TDM
推荐系统的任务是从候选集(例如,商品库)中选出用户当前偏好的一个子集。当候选集的规模很大时,如何快速有效地从全库中做推荐是一个具有挑战性的问题。TDM创造性地采用树结构作为索引结构并进一步地令用户对树上节点的偏好满足下面的近似最大堆性质:

其中 p(l)(n|u) 是用户 u 对节点 n 偏好概率的真值,α(l)是第 l 层内偏好概率分布的归一化项。这样的建模保证了第 l 层节点中偏好概率最大的 k个节点一定包含在第 l−1 层的top-k节点的子节点中。基于这一建模,TDM将推荐问题转换为树结构中自上而下的层次化的检索问题。下图给出了TDM候选子集的生成过程。
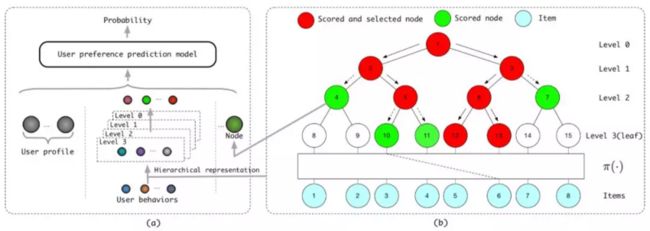
首先,候选集中的每个商品都被分配到树的一个不同叶子节点上,如图(b)所示。树上的非叶子节点可以看做是它的子节点集合的一个抽象。图(a)给出了用户对节点的偏好概率的计算过程,用户信息和待打分的节点首先被向量化为深度打分网络(例如,全连接网络,attention网络等等)的输入,网络的输出作为用户对该节点的偏好概率。在检索top-k的候选子集即top-k叶子节点的过程中,我们采用自顶向下的逐层beam search方法。在第l层中,我们只对第l−1层被选中的k个节点的子节点进行打分和排序来选择第l层的k个候选。图(b)给出了检索过程的示意。
通过采用树结构作为索引,对一个用户的偏好子集进行top1检索的时间复杂度为O(log(N)),其中 N 为全部候选集的大小。这一复杂度也与用户偏好打分模型的结构无关。同时,近似最大堆的假设将模型学习的目标转化为用户-节点偏好分布的学习,这使得TDM能够打破最近邻检索模式带来的内积形式的用户偏好打分的限制,赋能任意复杂打分模型,从而极大的提升了推荐的准确率。
3.2 JTM中的联合优化框架
从检索过程中可以看到,TDM的推荐准确率由用户偏好打分模型 M 和树索引结构 T 共同决定,且二者是相互耦合的关系。具体地,给定 n 对正样本 ,即用户 u(i)对商品c(i)感兴趣,树结构 T 决定了模型 M 需要选择哪些非叶子节点来对用户 u(i)返回商品c(i) 。在统一目标下联合优化 M 和 T 能够避免二者优化方向的冲突造成的整体结果次优。为此,在JTM中,我们在一个共同的损失函数下联合优化 M 和 T 。我们首先构造联合优化的目标函数。
记 p(π(c)|u;π)为用户u对叶子节点 π(c) 的偏好概率,其中 π(⋅) 是把候选集中的商品投射到树的叶子节点上的投影函数。π(c) 决定了候选集中的商品在树结构上的索引顺序。如果 (u,c) 是一个正样本,我们有 p(π(c)|u;π)=1。同时在近似最大堆的假设下,对 π(c) 的所有祖先节点,其偏好概率也为1,即。其中 bj(⋅) 是把一个节点投影到其在第 j 层的祖先节点的投影函数,lmax 为树 T 的层数。记 为模型 M 返回的用户 u 对节点 π(c) 的偏好概率的估计值,其中 θ 为模型的参数。给定 n 对正样本,我们希望联合优化 π 和 θ 来拟合上述的用户对树上节点的偏好分布。为此,我们希望 π 和 θ 最小化如下的全局经验损失函数:

在求解中,由于优化 π 是一个组合优化问题,很难和 θ 用基于梯度的优化算法同时优化。因此,我们提出交替优化 θ 和 π 的联合优化框架,如下图所示。优化 θ 和 π 的目标一致性促进了整个算法的收敛。事实上,如果模型学习和树学习能够同时使得损失函数下降,那么整个算法一定会收敛,因为 {L(θt,πt)} 是下界为0的单调下降序列。

在模型训练中,minθL(θ,π) 是为了求解得到每层的用户-节点偏好打分模型。得益于树结构和近似最大堆的性质,我们只需要在模型训练中拟合训练集中的用户-节点偏好分布,这使得我们可以使用任意复杂的神经网络模型,同时 minθL(θ,π) 可以用流行的算法例如SGD、Adam求解。采样策略如Noise-contrastive estimation (NCE)可以用来加速计算中的归一化项。
树结构学习是在给定模型参数的情况下求解 maxπ−L(θ,π) ,这是一个组合优化问题。事实上,给定树的形状时(为了便于表达,我们假定树的形状是完整二叉树。我们提出的优化算法可以方便地推广到多叉树的情况),maxπ−L(θ,π) 等价于寻找候选集和所有叶子节点之间的一个最优匹配,这进一步等价于一个带权二部图的最大匹配。分析过程如下:
若第k个商品ck被分配到第m个叶子节点 nm 上,即 π(ck)=nm,我们可以计算如下的权重:
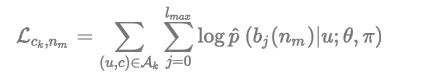
其中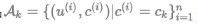
为目标商品为 ck 的训练样本集合。把树的叶子节点和候选集作为顶点,叶子节点和候选集之间的全连接作为边,把 Lck,nm 作为 ck 和 nm 之间边的权重,我们可以构造一个带权二部图V ,如2.1节的流程图(b)所示。在这种情况下,每个可能的 π(⋅) 都是 V 的一个匹配,同时我们有
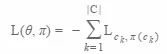
C 为所有ck的集合。因此,maxπ−L(θ,π) 等价于求解 V 的最大权匹配。
对于大规模的候选集,传统的求解最大权匹配的算法例如匈牙利算法由于复杂度太高而难以使用。即使是最简单的贪婪算法,计算和存储所有的权重的成本也是无法接受的。为解决这一问题,我们利用树结构提出了一种分段式树学习算法。相比于直接将所有商品分配到叶子节点中,我们在树中自上而下地一步步实现商品到节点的分配。记:


不断重复这一过程,直至每个商品被分配到叶子节点上为止。整个算法的流程如下图所示:

3.3 层次化用户兴趣表达
本质上,JTM(和TDM)是对推荐系统中索引结构和检索方式的一种深度改造。树结构的每一层可以看做是商品不同粒度上的聚合表示,JTM通过树上自顶向下的逐层相关性检索,从粗到细地找到用户信息匹配的最佳候选子集,这也与人类视角选择偏好商品的过程相契合。通过联合考虑模型和索引结构,JTM和TDM将一个复杂的大规模推荐任务分解为若干个级联的子检索任务,在上层的检索任务中,只需要在一个更粗的粒度上做圈选,且每层圈选的候选集远小于候选集全集,其训练难度将大大缩小。可以预见,当子检索任务的解足够理想时,其级联后的检索结果将超越直接在候选集中圈选候选集的效果。
事实上,树结构本身提供了候选集的一个层次结构,因为每个非叶子节点都是其所有子节点的一个学习到的抽象,这启发我们在训练模型 M 做每层的子检索任务时对用户行为特征做最利于模型学习的精准层次建模。
具体而言,用户历史行为的每个商品都是一个ID类离散特征,在模型训练中,每个商品和树上的节点都被嵌入到一个连续特征空间并与模型同时优化。从每个非叶子节点是其子节点的抽象这一点出发,给定用户行为序列c={c1,c2,⋯,cm} ,我们提出用 cl={bl(π(c1)),bl(π(c2)),⋯,bl(π(cm))}联合目标节点以及用户的其他特征来生成模型 M 在第 l 层检索的输入。通过这种方式,用户行为过的商品在第 l 层的祖先节点被用作了用户抽象化的行为序列。这主要带来了两方面的好处:
1.层间的独立性。
传统的在每层检索中共用用户行为序列的embedding会在训练 M 作为每层的用户偏好打分模型时引入噪声,这是因为 M 在每层的训练目标是不同的。一个直接的解决办法是在每层赋予每个商品一个单独的embedding来联合训练。但是这会极大的增加参数量。我们提出的层次化用户行为特征使用对应层节点的embedding生成 M 的输入,从而在没有增加参数总量的同时实现了层间embedding学习的独立。
2.用户的精准建模。
M 在检索过程中逐层选择最终候选子集的从粗到细的抽象。我们提出的层次化用户行为特征表达抓住了这一检索过程的本质,用当前层的节点对用户行为进行了适当的抽象,从而增加了用户偏好的可预测性,减少了过粗或者过细的特征表达带来的混淆。
四. 实验效果
4.1 实验设置
我们使用了Amazon Books和UserBehavior两个大型公开数据集来进行方法的效果评估。Amazon Books是用户在Amazon上的行为记录,我们选择了其中最大的Books这一子类目。UserBehavior为阿里开源的淘宝用户行为数据集。数据集的规模如下:

在实验中,我们比较了下面几种方法:
- Item-CF: 基本的协同滤波算法,被广泛应用于个性化推荐任务中。
- YouTube product-DNN: 应用于Youtube视频推荐的向量内积检索模型。
- HSM: 层次Softmax模型,被广泛应用于NLP领域,作为归一化概率计算的一种替代.
- TDM: 我们此前的工作深度树匹配推荐技术。
- DNN: TDM模型去掉树结构后的版本。该方法不使用索引结构,在预测时会对全量候选集进行打分,再挑选topk。由于对全量候选集打分的计算复杂度非常高,因此无法实际应用,但可以作为强baseline来进行比较。
- JTM: 本文中提出的联合优化方法。同时,我们对比了JTM的两个变种版本,分别为JTM-J和JTM-H。其中,JTM-J为使用了树结构联合优化但没有采用层次化用户兴趣表达的版本;JTM-H相反,其使用了层次化用户兴趣表达,但会使用固定的初始树结构而不进行联合学习。
在所有神经网络模型中,均使用相同的三层全连接网络作为打分模型。评测方面,我们使用Precision, Recall和F-measure作为性能评测指标,定义如下:

Pu 是对用户 u召回的商品集合,Gu 是用户 u感兴趣集合的真集。
4.2 比较结果
下表给出了各个方法在两个数据集上的比较结果。相比于效果最佳的baseline方法DNN(计算量太高无法应用于实际),JTM在Amazon Books和UserBehavior上的recall分别取得了45.3%和8.1%的相对提升。
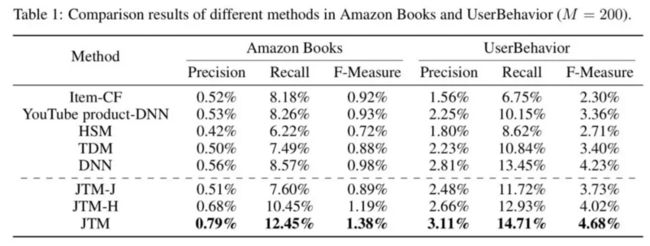
DNN的性能要优于YouTube product-DNN,这反应了内积模型的局限性,只通过内积的形式构造用户对商品的偏好概率无法充分拟合用户-商品偏好分布。此外,TDM的性能不如DNN,这说明了树结构优化的必要性。
欠佳的树结构可能导致模型学习收敛到次优的结果。特别是对于Amazon Books这种稀疏的数据,树上节点的embedding无法充分学习而不具有显著的区分性导致TDM效果不显著。与之对应的是,通过应用本文提出的层次化用户兴趣表征方法,JTM-J方案在一定程度上解决了粗粒度上的数据稀疏性问题,所以对比TDM在Amazon Books数据集上取得了十分显著的提升,通过联合优化,JTM在所有数据集和评测指标上显著优于DNN全量打分的结果,且检索复杂度也要低得多。
这些结果说明,通过统一目标下联合优化的方式,JTM能够学习到更优的树结构和兴趣模型。从JTM、JTM-J、JTM-H三者的相互对比来看,可以发现不管是同一目标下的联合学习,还是层次化的用户兴趣表示,都能提升最终的推荐精准度。另外,在JTM的联合框架下,树结构学习和层次化兴趣表示叠加,起到了1+1>2的效果。
4.3 树结构学习收敛性
在基于树的推荐方法中,树结构直接影响了训练时的样本生成和预测时的检索路径。一个好的树结构,不管是对模型训练还是兴趣检索,都能发挥重要的正面作用。下图中,我们对比了JTM提出的基于统一目标的树联合学习方案,和TDM工作中使用到的基于商品embedding聚类的方案。其中,前三个图为Amazon Books数据集上的效果,后三个图为UserBehavior数据集上的效果
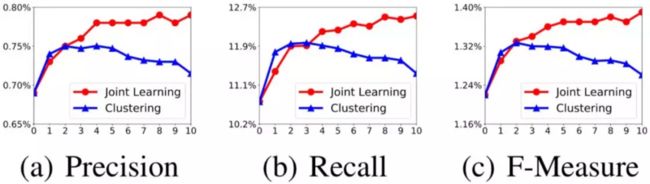
从实验结果中可以发现,本文提出的JTM方案,在树结构学习的逐步迭代过程中,能够稳定地收敛到一个更优的树结构。与之对比的是,基于聚类的方案,在迭代最后都会出现类似于过拟合的情况。
五. 总结
JTM给出了一种统一目标下联合优化深度树匹配模型的打分模型和树索引结构的算法框架。在树结构优化中,我们基于树型结构的特点提出了一种可用于大规模任务的分层重建算法。在模型优化和打分中,基于树上检索逐层细化候选集合的本质,我们相应的提出了对用户行为特征层次化的建模方法。
JTM继承了TDM打破内积模型的约束,可容纳任意深度打分模型的优势。此外,通过联合调优,JTM带来了显著的效果提升。JTM彻底解决了历史推荐系统架构的非最优联合问题,建立了完全数据驱动下端到端索引,模型和检索联合最优化的系统组成。进一步的,JTM的提出,是对以user-tag-doc两段式检索为基础的搜索,推荐和广告现有架构的一次重大技术革新。
之前的TDM解决方案已经基于阿里巴巴自研的深度学习平台X-DeepLearning在 Github 开源,点击获得Github下载链接,了解更多详情。
阿里妈妈信息流广告算法团队常年诚招大数据处理和机器学习算法方向的能人志士!有意者可发简历联系:[email protected]。
本文作者:阿里妈妈技术团队
本文来自云栖社区合作伙伴“阿里技术”,如需转载请联系原作者。