边缘计算
转载出处:https://blog.csdn.net/gui951753/article/details/80952907
注:本篇翻译自施巍松教授的论文《Edge Computing : Vision and Challenges》
目录
- 摘要
- 简介
- 什么是边缘计算
- 为什么需要边缘计算
- 什么是边缘计算
- 边缘计算的优点
- 案例研究
- 云卸载
- 视频分析
- 智能家居
- 智慧城市
- 边缘协作
- 机遇和挑战
- 编程可行性
- 命名
- 数据抽象
- 服务管理
- 私密性
- 最优化指标
- 小结
摘要
物联网技术的快速发展和云服务的推动使得云计算模型已经不能很好的解决现在的问题,于是,这里给出一种新型的计算模型,边缘计算。边缘计算指的是在网络的边缘来处理数据,这样能够减少请求响应时间、提升电池续航能力、减少网络带宽同时保证数据的安全性和私密性。这篇文章会通过一些案例来介绍边缘计算的相关概念,内容包括云卸载、智能家居、智慧城市和协同边缘节点实现边缘计算。希望这篇文章能够给你一些启发并让更多的人投入边缘计算的研究中来。
简介
云计算自从它与2005年提出之后,就开始逐步的改变我们生活、学习、工作的方式。生活中经常用到的google、facebook等软件提供的服务就是典型的代表。并且,可伸缩的基础设施和能够支持云服务的处理引擎也对我们运营商业的模式产生了一定的影响,比如,hadoop、spark等等。
物联网的快速发展让我们进入了后云时代,在我们的日常生活中会产生大量的数据。思科估计到2019年会有将近500亿的事物连接到互联网。物联网应用可能会要求极快的响应时间,数据的私密性等等。如果把物联网产生的数据传输给云计算中心,将会加大网络负载,网路可能造成拥堵,并且会有一定的数据处理延时。
随着物联网和云服务的推动,我们假设了一种新的处理问题的模型,边缘计算。在网络的边缘产生、处理、分析数据。接下来的文章会介绍为什么需要边缘计算,相关定义。有关云卸载和智慧城市的一些研究,有关边缘计算下的编程、命名、数据抽象、服务管理、数据私密和安全性的问题也会在下文讨论。
什么是边缘计算
在网络边缘产生的数据正在逐步增加,如果我们能够在网络的边缘结点去处理、分析数据,那么这种计算模型会更高效。许多新的计算模型正在不断的提出,因为我们发现随着物联网的发展,云计算并不总是那么高效的。接下来文章中将会列出一些原因来证明为什么边缘计算能够比云计算更高效,更优秀。
为什么需要边缘计算
-
云服务的推动:云中心具有强大的处理性能,能够处理海量的数据。但是,将海量的数据传送到云中心成了一个难题。云计算模型的系统性能瓶颈在于网络带宽的有限性,传送海量数据需要一定的时间,云中心处理数据也需要一定的时间,这就会加大请求响应时间,用户体验极差。
-
物联网的推动:现在几乎所有的电子设备都可以连接到互联网,这些电子设备会后产生海量的数据。传统的云计算模型并不能及时有效的处理这些数据,在边缘结点处理这些数据将会带来极小的响应时间、减轻网络负载、保证用户数据的私密性。
- 终端设备的角色转变:终端设备大部分时间都在扮演数据消费者的角色,比如使用智能手机观看爱奇艺、刷抖音等。然而,现在智能手机让终端设备也有了生产数据的能力,比如在淘宝购买东西,在百度里搜索内容这些都是终端节点产生的数据。
下面两幅图,图1是传统云计算模型下的范式,最左侧是服务提供者来提供数据,上传到云中心,终端客户发送请求到云中心,云中心响应相关请求并发送数据给终端客户。终端客户始终是消费者的角色。
图2是现在物联网快速发展下的边缘计算范式。边缘结点(包括智能家电、手机、平板等)产生数据,上传到云中心,服务提供商也产生数据上传到云中心。边缘结点发送请求到云中心,云中心返还相关数据给边缘结点。 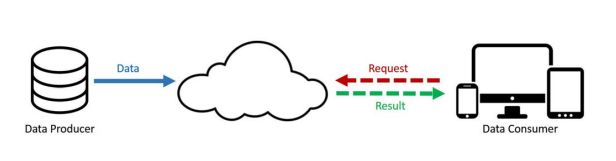
图1 云计算范式 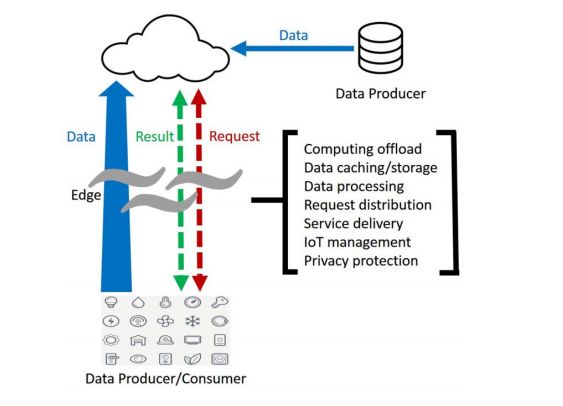
图2 边缘计算范式
什么是边缘计算
边缘计算指的是在网络边缘结点来处理、分析数据。这里,我们给出边缘结点的定义,边缘结点指的就是在数据产生源头和云中心之间任一具有计算资源和网络资源的结点。比如,手机就是人与云中心之间的边缘结点,网关是智能家居和云中心之间的边缘结点。在理想环境中,边缘计算指的就是在数据产生源附近分析、处理数据,没有数据的流转,进而减少网络流量和响应时间。
边缘计算的优点
- 在人脸识别领域,响应时间由900ms减少为169ms
- 把部分计算任务从云端卸载到边缘之后,整个系统对能源的消耗减少了30%-40%。
- 数据在整合、迁移等方面可以减少20倍的时间。
案例研究
云卸载
在传统的内容分发网络中,数据都会缓存到边缘结点,随着物联网的发展,数据的生产和消费都是在边缘结点,也就是说边缘结点也需要承担一定的计算任务。把云中心的计算任务卸载到边缘结点这个过程叫做云卸载。
举个例子,移动互联网的发展,让我们得以在移动端流畅的购物,我们的购物车以及相关操作(商品的增删改查)都是依靠将数据上传到云中心才能得以实现的。如果将购物车的相关数据和操作都下放到边缘结点进行,那么将会极大提高响应速度,增强用户体验。通过减少延迟来提高人与系统的交互质量。
视频分析
随着移动设备的增加,以及城市中摄像头布控的增加,利用视频来达成某种目的成为一种合适的手段,但是云计算这种模型已经不适合用于这种视频处理,因为大量数据在网络中的传输可能会导致网络拥塞,并且视频数据的私密性难以得到保证。
因此,提出边缘计算,让云中心下放相关请求,各个边缘结点对请求结合本地视频数据进行处理,然后只返回相关结果给云中心,这样既降低了网络流量, 也在一定程度上保证了用户的隐私。
举例而言,有个小孩儿在城市中丢失,那么云中心可以下放找小孩儿这个请求到各个边缘结点,边缘结点结合本地的数据进行处理,然后返回是否找到小孩儿这个结果。相比把所有视频上传到云中心,并让云中心去解决,这种方式能够更快的解决问题。
智能家居
物联网的发展让普通人家里的电子器件都变得活泼了起来,仅仅让这些电子器件连上网络是不够的,我们需要更好的利用这些电子元件产生的数据,并利用这些数据更好的为当前家庭服务。考虑到网络带宽和数据私密保护,我们需要这些数据最好仅能在本地流通,并直接在本地处理即可。我们需要网关作为边缘结点,让它自己消费家庭里所产生的数据。同时由于数据的来源有很多(可以是来自电脑、手机、传感器等任何智能设备),我们需要定制一个特殊的OS,以至于它能把这些抽象的数据揉和在一起并能有机的统一起来。
智慧城市
边缘计算的设计初衷是为了让数据能够更接近数据源,因此边缘计算在智慧城市中有以下几方面优势:
- 海量数据处理:在一个人口众多的大城市中,无时无刻不在产生着大量的数据,而这些数据如果通通交由云中心来处理,那么将会导致巨大的网络负担,资源浪费严重。如果这些数据能够就近进行处理,在数据源所在的局域网内进行处理,那么网络负载就会大幅度降低,数据的处理能力也会有进一步的提升。
- 低延迟:在大城市中,有很多服务是要求具有实时特性的,这就要求响应速度能够尽可能的进一步提升。比如医疗和公共安全方面,通过边缘计算,将减少数据在网络中传输的时间,简化网络结构,对于数据的分析、诊断和决策都可以交由边缘结点来进行处理,从而提高用户体验。
- 位置感知:对基于位置的一些应用来说,边缘计算的性能要由于云计算。比如导航,终端设备可以根据自己的实时位置把相关位置信息和数据交给边缘结点来进行处理、边缘结点基于现有的数据进行判断和决策。整个过程中的网络开销都是最小的。用户请求得以极快的得到响应。
边缘协作
由于数据隐私性问题和数据在网络中传输的成本问题,有一些数据是不能由云中心去处理的,但是这些数据有时候又需要多个部门协同合作才能发挥它最大的作用。于是,我们提出了边缘协同合作的概念,利用多个边缘结点协同合作,创建一个虚拟的共享数据的视图,利用一个预定义的公共服务接口来将这些数据进行整合,同时,通过这个数据接口,我们可以编写应用程序为用户提供更复杂的服务。
举个多个边缘结点协同合作共赢的例子。比如流感爆发的时候,医院作为一个边缘结点与药房、医药公司、政府、保险行业等多个节点进行数据共享,把当前流感的受感染人数、流感的症状、治疗流感的成本等共享给以上边缘结点。药房通过这些信息有针对性的调整自己的采购计划,平衡仓库的库存;医药公司则能通过共享的数据得知哪些为要紧的药品,提升该类药品生产的优先级;政府向相关地区的人们提高流感警戒级别,此外,还可以采取进一步的行动来控制流感爆发的蔓延;保险公司根据这次流感程度的严峻性来调整明年该类保险的售价。总之,边缘结点中的任何一个节点都在这次数据共享中得到了一定的利益。
机遇和挑战
以上是边缘计算在解决相关问题的潜力和展望,接下来会分析在实现边缘计算的过程中将要面临的机遇和挑战。
编程可行性
在云计算平台编程是非常便捷的,因为云有特定的编译平台,大部分程序都可以在云上跑。但是边缘计算下的编程就会面临一个问题,平台异构问题,每一个网络的边缘都是不一样的,有可能是ios系统,也有可能是安卓或者linux等等,不同平台下的编程又是不同的。因此我们提出了计算流的概念,计算流是数据传播路径上的函数序列/计算序列,可以通过应用程序指定计算发生在数据传播路径中的哪个节点。计算流可以帮助用户确定应该完成哪些功能/计算,以及在计算发生在边缘之后如何传播数据。通过部署计算流,可以让计算尽可能的接近数据源。
命名
命名方案对于编程、寻址、事物识别和数据通信非常重要,但是在边缘计算中还没有行之有效的数据处理方式。边缘计算中事物的通信是多样的,可以依靠wifi、蓝牙、2.4g等通信技术,因此,仅仅依靠tcp/ip协议栈并不能满足这些异构的事物之间进行通信。边缘计算的命名方案需要处理事物的移动性,动态的网络拓扑结构,隐私和安全保护,以事物的可伸缩性。传统的命名机制如DNS(域名解析服务)、URI(统一资源标志符)都不能很好的解决动态的边缘网络的命名问题。目前正在提出的NDN(命名分发网络)解决此类问题也有一定的局限性。在一个相对较小的网络环境中,我们提出一种解决方案,如图3所示,我们描述一个事物的时间、地点以及正在做的事情,这种统一的命名机制使得管理变得非常容易。当然,当环境上升到城市的高度的时候,这种命名机制可能就不是很合适了,还可以进行进一步的讨论。 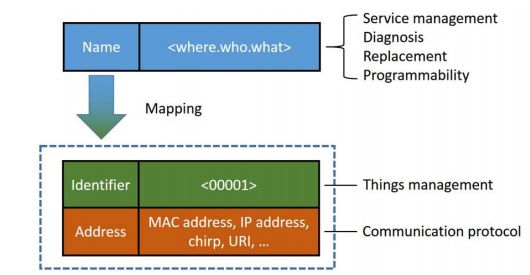
图3 命名机制
数据抽象
在物联网环境中会有大量的数据生成,并且由于物联网网络的异构环境,生成的数据是各种格式的,把各种各样的数据格式化对边缘计算来说是一个挑战。同时,网络边缘的大部分事物只是周期性的收集数据,定期把收集到的数据发送给网关,而网关中的存储是有限的,他只能存储最新的数据,因此边缘结点的数据会被经常刷新。利用集成的数据表来存储感兴趣的数据,表内部的结构可以如图4所示,用id、时间、名称、数据等来表示数据。 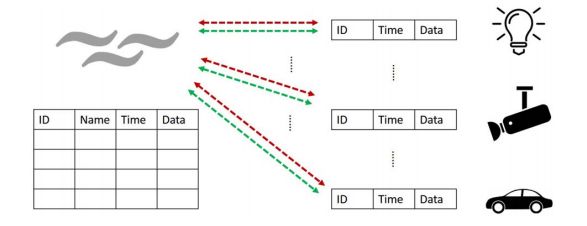
图4 相应表结构
如果筛选掉过多的原始数据,将导致边缘结点数据报告的不可靠,如果保留大量的原始数据,那么边缘结点的存储又将是新的问题;同时这些数据应该是可以被引用程序读写和操作的,由于物联网中事物的异构性,导致数据库的读写和操作会存在一定的问题。
服务管理
边缘结点的服务管理我们认为应该有以下四个特征,,包括差异化、可扩展性、隔离性和可靠性,进而保证一个高效可靠的系统。
- 差异化:随着物联网的发展,会有这种各样的服务,不同的服务应该有差异化的优先级。比如,有关事物判断和故障警报这样的关键服务就应该高于其它一般服务,有关人类身体健康比如心跳检测相关的服务就要比娱乐相关服务的优先级要高一些。
- 可扩展性:物联网中的物品都是动态的,向物联网中添加或删除一件物品都不是那么容易的,服务缺少或者增加一个新的结点能否适应都是待解决的问题,这些问题可以通过对边缘os的高扩展和灵活的设计来解决。
- 隔离性:所谓隔离性是指,不同的操作之间互不干扰。举例而言,有多个应用程序可以控制家庭里面的灯光,有关控制灯光的数据是共享的,当有某个应用程序不能响应时,使用其他的应用程序依然能够控制灯光。也就是说这些应用程序之间是相互独立的,互相并没有影响;隔离性还要求用户数据和第三方应用是隔离的,也就是说应用不应该能够跟踪用户的数据并记录下来,为了解决该问题,应当添加一种全新的应用访问用户数据的方式。
- 可靠性:可靠性可以从服务、系统和数据三方面来谈论
- 从服务方面来说,网络拓扑中任意节点的丢失都有可能导致服务的不可用,如果边缘系统能够提前检测到具有高风险的节点那么就可以避免这种风险。较好的一种实现方式是使用无线传感器网络来实时监测服务器集群。
- 从系统角度来看,边缘操作系统是维护整个网络拓扑的重要一部分内容。节点之间能够互通状态和诊断信息。这种特征使得在系统层面部署故障检测、节点替换、数据检测等十分的方便。
- 从数据角度来看,可靠性指的是数据在传感和通信方面是可靠地。边缘网络中的节点有可能会在不可靠的时候报告信息,比如当传感器处于电量不足的时候就极有可能导致传输的数据不可靠。为解决此类问题可能要提出新的协议来保证物联网在传输数据时的可靠性。
私密性
现存的提供服务的方法是手机终端用户的数据并上传到云端,然后利用云端强大的处理能力去处理任务,在数据上传的过程中,数据很容易被别有用心的人收集到。为了保证数据的私密性,我们可以从以下这些方面入手。
1,在网络的边缘处理用户数据,这样数据就只会在本地被存储、分析和处理。
2,对于不同的应用设置权限,对私密数据的访问加以限制。
3,边缘的网络是高度动态化的网络,需要有效的工具保护数据在网络中的传输。
最优化指标
在边缘计算当中,由于节点众多并且不同节点的处理能力是不同的,因此,在不同的节点当中选择合适的调度策略是非常重要的。接下来从延迟、带宽、能耗和花费这四个方面来讨论最优化的指标。
- 延迟: 很明显云中心具有强大的处理能力,但是网络延迟并不单单是处理能力决定的,也会结合数据在网路中传输的时间。拿智慧城市距离来说,如果要寻找丢失的小孩儿信息,在本地的手机处理,然后把处理结果返回给云明显能加快响应速度。当然,这种事情也是相对而言的,我们需要放一个逻辑判断层,来判断把任务交给哪一个节点处理合适,如果此时手机正在打游戏或者处理其他非常重要的事情,那么手机就不是很适合处理这种任务,把这种任务交给其他层次来处理会更好些。
- 带宽:高带宽传输数据意味着低延迟,但是高带宽也意味着大量的资源浪费。数据在边缘处理有两种可能,一种是数据在边缘完全处理结束,然后边缘结点上传处理结果到云端;另外一种结果是数据处理了一部分,然后剩下的一部分内容将会交给云来处理。以上两种方式的任意一种,都能极大的改善网路带宽的现状,减少数据在网络中的传输,进而增强用户体验。
- 能耗:对于给定的任务,需要判定放在本地运算节省资源还是传输给其他节点计算节省资源。如果本地空闲,那么当然在本地计算是最省资源的,如果本地正在忙碌状态,那么把计算任务分给其他节点会更合适一些。权衡好计算消耗的能源和网络传输消耗的能源是一件非常重要的事情。一般当网络传输消耗的资源远小于在本地计算消耗的能源时,我们会考虑使用边缘计算把计算任务卸载到其他空闲的节点上,帮助实现负载均衡,保证每一个结点的高性能。
- 花费:目前在边缘计算上的花费包括但不限于边缘结点的构建和维护、新型模型的开发等。利用边缘计算的模型,大型的服务提供商在处理相同工作的情况下能够获取到更大的利润。
小结
物联网的发展和云计算的推动使得边缘计算的模型出现在社区之中。在边缘结点处理数据能够提高响应速度,减少带宽,保证用户数据的私密性。这篇文章当中,我们提出了边缘计算可能在以后的生活中一些相关场景的运用,也提到了边缘计算以后发展的展望和挑战。希望以后有更多的同僚能够关注到这么一个领域