K-Means(K均值聚类算法)
K-Means(K均值聚类算法)
1.前言
要学习聚类算法就要知道聚类学习算法是什么,为什么要学习聚类学习聚类学习算法,有什么用途,下面就简单的做一下介绍,并且详细的说明k—means均值聚类学习算法。
2.是什么问题
- 机器学习中有两类大问题,一类是分类,一类是聚类。聚类问题属于无监督学习范畴,分类属于监督学习范畴。也就是说在监督学习领域比如朴素贝叶斯、SVM等,一开始都会给定类别y,说明该样本的类别,比方说入学时老师分配的班级,一进来就是带有班级这个类别标签的。而聚类问题属于无监督学习范畴,一开始没有指定分类,慢慢的通过一定过程找到了自己的类别,比如自己刚入学并不知道跟谁是好哥们,在慢慢的相处中找到了自己的好哥们。这就是其本质区别。
- 1 样本
- 2.对于分类问题
{ x^1,x^2,...,x^m } 中每个都含有y
x^i belong to R^n- 3.对于聚类问题
{ x^1,x^2,...,x^m } and x^i belong to R^n没有y。最后算法不断迭代将其分为k个不同的簇(cluster)。
- 4.具体算法描述:
1.随机选取k个聚类质心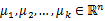
2、 重复下面过程直到收敛 {
对于每一个样例i,计算其应该属于的类

对于每一个类j,重新计算该类的质心
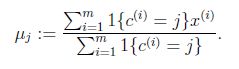
}
- [ ] 参数描述:
- k 给定的聚类数。
-  代表样例i在k个类中距离最近的类簇。其值为1到k中的任意一个。
代表样例i在k个类中距离最近的类簇。其值为1到k中的任意一个。
- 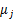 是质心,是我们对样本中心点的猜测,也就是不断迭代的对象。拿星团模型来解释就是要将所有的星星聚成k个星团,首先随机选取k个宇宙中的点(或者k个星星)作为k个星团的质心,然后第一步对于每一个星星计算其到k个质心中每一个的距离,然后选取距离最近的那个星团作为,这样经过第一步每一个星星都有了所属的星团;第二步对于每一个星团,重新计算它的质心(对里面所有的星星坐标求平均)。重复迭代第一步和第二步直到质心不变或者变化很小。
是质心,是我们对样本中心点的猜测,也就是不断迭代的对象。拿星团模型来解释就是要将所有的星星聚成k个星团,首先随机选取k个宇宙中的点(或者k个星星)作为k个星团的质心,然后第一步对于每一个星星计算其到k个质心中每一个的距离,然后选取距离最近的那个星团作为,这样经过第一步每一个星星都有了所属的星团;第二步对于每一个星团,重新计算它的质心(对里面所有的星星坐标求平均)。重复迭代第一步和第二步直到质心不变或者变化很小。
下图展示了对n个样本点进行K-means聚类的效果,这里k取2。

对于图的解析:
| 图标 | 操作 |
|---|---|
| (a) | 样本集 |
| (b) | 任取一红一篮两点作为质心 |
| (c) | 将离红点近的点标为红色,将距离蓝点比较近的点标记为蓝色 |
| (d) | 分别再求红色,蓝色点的质心 |
| (e) | 根据新求的质心再将样本集分类 |
| (f) | 继续迭代求质心 |
- 5.方法证明
Andrew Ng老师讲了证明的方法,直接把另一位博友的文章拿来用。 K-means面对的第一个问题是如何保证收敛,前面的算法中强调结束条件就是收敛,可以证明的是K-means完全可以保证收敛性。下面我们定性的描述一下收敛性,我们定义畸变函数(distortion function)如下:
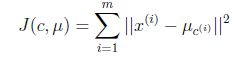
J函数表示每个样本点到其质心的距离平方和。K-means是要将J调整到最小。假设当前J没有达到最小值,那么首先可以固定每个类的质心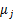 调整每个样例的所属的类别
调整每个样例的所属的类别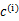 来让J函数减少,同样,固定,调整每个类的质心也可以使J减小。这两个过程就是内循环中使J单调递减的过程。当J递减到最小时,u和c也同时收敛。(在理论上,可以有多组不同的u和c值能够使得J取得最小值,但这种现象实际上很少见)。由于畸变函数J是非凸函数,意味着我们不能保证取得的最小值是全局最小值,也就是说k-means对质心初始位置的选取比较感冒,但一般情况下k-means达到的局部最优已经满足需求。但如果你怕陷入局部最优,那么可以选取不同的初始值跑多遍k-means,然后取其中最小的J对应的u和c输出。
来让J函数减少,同样,固定,调整每个类的质心也可以使J减小。这两个过程就是内循环中使J单调递减的过程。当J递减到最小时,u和c也同时收敛。(在理论上,可以有多组不同的u和c值能够使得J取得最小值,但这种现象实际上很少见)。由于畸变函数J是非凸函数,意味着我们不能保证取得的最小值是全局最小值,也就是说k-means对质心初始位置的选取比较感冒,但一般情况下k-means达到的局部最优已经满足需求。但如果你怕陷入局部最优,那么可以选取不同的初始值跑多遍k-means,然后取其中最小的J对应的u和c输出。
3.为什么要聚类
相信对于这一点大家很清楚聚类有很多用处,像我们平常看新闻,新闻都是分好类的,什么财经,军事都已经分好的。如果我们在百度搜索军事,出现的一定是军事方面的信息,这也是利用了聚类分析。
吴恩达老师在课堂上举了一个例子,聚类分析对于异常样本的分析有很好的效果,比如随着温度的升高发动机抖动样例,我们获取到了很多样本,其中大部分样本都是属于某一个类簇的,但有些点脱离类簇点很远,这时候就要对这些机器进行异常检查了。也就是说如果出现
P(x^i) 概率很小的话就说明出现了问题,可能该样本有异常。
下面是java 代码
package Clustering.Algorithms;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.io.PrintStream;
import java.text.DecimalFormat;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.PriorityQueue;
import java.util.Queue;
public class KMeans {
private class Node{
int label ;//用来记录点属于第几个cluster
double[] attributes;
public Node(){
attributes = new double[2000];
}
}
private class NodeComparator{
Node nodeOne;
Node nodeTwo;
double distance;
public void compute(){
double val = 0;
for(int i = 0;ithis.nodeOne.attributes[i]-this.nodeTwo.attributes[i])*(this.nodeOne.attributes[i]-this.nodeTwo.attributes[i]);
}
this.distance = val;
}
}
private ArrayList arraylist;//记录所有的node节点
private ArrayList centroidList;
private double averageDis;
private int dimension;//每个点有多少域,也就是点的纬度
private Queue FsQueue =
new PriorityQueue(150, // 用来排序任意两点之间的距离,从大到小排
new Comparator() {
@Override
public int compare(NodeComparator one, NodeComparator two) {
if (one.distance < two.distance)
return 1;
else if (one.distance > two.distance)
return -1;
else
return 0;
}
});
//获取到每一行的值
public void setKmeansInput(String path) {
try {
BufferedReader br = new BufferedReader(new FileReader(path));
String str;
String[] strArray;
arraylist = new ArrayList();
while ((str = br.readLine()) != null) {
strArray = str.split(",");
dimension = strArray.length;
Node node = new Node();
for (int i = 0; i < dimension; ++i) {
node.attributes[i] = Double.parseDouble(strArray[i]);
}
arraylist.add(node);
}
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
public void computeTheK() {
int cntTuple = 0;
for (int i = 0; i < arraylist.size() - 1; ++i) {
for (int j = i + 1; j < arraylist.size(); ++j) {
NodeComparator nodecomp = new NodeComparator();
nodecomp.nodeOne = new Node();
nodecomp.nodeTwo = new Node();
for (int k = 0; k < dimension; ++k) {
nodecomp.nodeOne.attributes[k] = arraylist.get(i).attributes[k];
nodecomp.nodeTwo.attributes[k] = arraylist.get(j).attributes[k];
}
nodecomp.compute();
averageDis += nodecomp.distance;
FsQueue.add(nodecomp);
cntTuple++;
}
}
averageDis /= cntTuple;// 计算平均距离
chooseCentroid(FsQueue);
}
public double getDistance(Node one, Node two) {// 计算两点间的欧氏距离
double val = 0;
for (int i = 0; i < dimension; ++i) {
val += (one.attributes[i] - two.attributes[i]) * (one.attributes[i] - two.attributes[i]);
}
return val;
}
public void chooseCentroid(Queue queue) {
centroidList = new ArrayList();
boolean flag = false;
while (!queue.isEmpty()) {
boolean judgeOne = false;
boolean judgeTwo = false;
NodeComparator nc = FsQueue.poll();
if (nc.distance < averageDis)
break;// 如果接下来的元组,两节点间距离小于平均距离,则不继续迭代
if (!flag) {
centroidList.add(nc.nodeOne);// 先加入所有点中距离最远的两个点
centroidList.add(nc.nodeTwo);
flag = true;
} else {// 之后从之前已加入的最远的两个点开始,找离这两个点最远的点,
// 如果距离大于所有点的平均距离,则认为找到了新的质心,否则不认定为质心
for (int i = 0; i < centroidList.size(); ++i) {
Node testnode = centroidList.get(i);
if (centroidList.contains(nc.nodeOne) || getDistance(testnode, nc.nodeOne) < averageDis) {
judgeOne = true;
}
if (centroidList.contains(nc.nodeTwo) || getDistance(testnode, nc.nodeTwo) < averageDis) {
judgeTwo = true;
}
}
if (!judgeOne) {
centroidList.add(nc.nodeOne);
}
if (!judgeTwo) {
centroidList.add(nc.nodeTwo);
}
}
}
}
public void doIteration(ArrayList centroid) {
int cnt = 1;
int cntEnd = 0;
int numLabel = centroid.size();
while (true) {// 迭代,直到所有的质心都不变化为止
boolean flag = false;
//将所有点的label进行赋值
for (int i = 0; i < arraylist.size(); ++i) {
double dis = 0x7fffffff;
cnt = 1;
for (int j = 0; j < centroid.size(); ++j) {
Node node = centroid.get(j);
if (getDistance(arraylist.get(i), node) < dis) {
dis = getDistance(arraylist.get(i), node);
arraylist.get(i).label = cnt;
}
cnt++;
}
}
int j = 0;
numLabel -= 1;
while (j < numLabel) {
int c = 0;//同一个质心的点数
Node node = new Node();
//求同一个质心的各个纬度的和
for (int i = 0; i < arraylist.size(); ++i) {
if (arraylist.get(i).label == j + 1) {
for (int k = 0; k < dimension; ++k) {
node.attributes[k] += arraylist.get(i).attributes[k];
}
c++;
}
}
DecimalFormat df = new DecimalFormat("#.###");// 保留小数点后三位
double[] attributelist = new double[100];
for (int i = 0; i < dimension; ++i) {
//不同质心的平均值。迭代求新的质心
attributelist[i] = Double.parseDouble(df.format(node.attributes[i] / c));
// 更新质心
if (attributelist[i] != centroid.get(j).attributes[i]) {
centroid.get(j).attributes[i] = attributelist[i];
flag = true;
}
}
if (!flag) {
cntEnd++;
if (cntEnd == numLabel) {// 若所有的质心都不变,则跳出循环
break;
}
}
j++;
}
if (cntEnd == numLabel) {// 若所有的质心都不变,则 success
System.out.println("run kmeans successfully.");
break;
}
}
}
public void printKmeansResults(String path) {
try {
PrintStream out = new PrintStream(path);
computeTheK();
doIteration(centroidList);
out.println("There are " + centroidList.size() + " clusters!");
for (int i = 0; i < arraylist.size(); ++i) {
out.print("(");
for (int j = 0; j < dimension - 1; ++j) {
out.print(arraylist.get(i).attributes[j] + ", ");
}
out.print(arraylist.get(i).attributes[dimension - 1] + ") ");
out.println("belongs to cluster " + arraylist.get(i).label);
}
out.close();
System.out.println("Please check results in: " + path);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
KMeans kmeans = new KMeans();
kmeans.setKmeansInput("/Users/aily/Desktop/test/input.txt");
kmeans.printKmeansResults("/Users/aily/Desktop/test/kmeansResults.txt");
}
}
输入样例:
1,1
2,1
1,2
2,2
6,1
6,2
7,1
7,2
1,5
1,6
2,5
2,6
6,5
6,6
7,5
7,6
输出样例
There are 4 clusters!
(1.0, 1.0) belongs to cluster 1
(2.0, 1.0) belongs to cluster 1
(1.0, 2.0) belongs to cluster 1
(2.0, 2.0) belongs to cluster 1
(6.0, 1.0) belongs to cluster 3
(6.0, 2.0) belongs to cluster 3
(7.0, 1.0) belongs to cluster 3
(7.0, 2.0) belongs to cluster 3
(1.0, 5.0) belongs to cluster 4
(1.0, 6.0) belongs to cluster 4
(2.0, 5.0) belongs to cluster 4
(2.0, 6.0) belongs to cluster 4
(6.0, 5.0) belongs to cluster 2
(6.0, 6.0) belongs to cluster 2
(7.0, 5.0) belongs to cluster 2
(7.0, 6.0) belongs to cluster 2