将Python中的字典数据转化为DataFrame的方法
编译:老齐
与本文相关的图书推荐:《数据准备和特征工程》

在数据科学项目中,通常用Pandas的read_csv或者read_excel从相应文件中读入数据,此外,对于数据量不大的时候,可能还有下面的情形出现:
import pandas as pd
data = {‘key1’: values, ‘key2’:values, ‘key3’:values, …, ‘keyN’:values}
df = pd.DataFrame(data)
这里是将一个Python中的字典data转化为了Pandas中的DataFrame对象,这样字典就作为了数据源。
上面的操作并不复杂,当然,这里演示的字典和对DataFrame的要求都是简单的情形。就一般而言,如果遇到了简单的数据源,可知通过下面的三步实施:
-
确定数据
要留言数据的格式,从而确定是否能够用于本文所说的过程。比如下面的数据:

我们需要做的是把这个表格样式的数据,用Python的字典表示——数据量小,不费事。 -
创建字典
把上面的表格,改写为:
data = {'Rank':[1, 2, 3, 4, 5], 'Language': ['Python', 'Java', 'Javascript', 'C#', 'PHP'], 'Share':[29.88, 19.05, 8.17, 7.3, 6.15], 'Trend':[4.1, -1.8, 0.1, -0.1, -1.0]} print(data)
-
转化为DataFrame
然后,就开始转化:
df = pd.DataFrame(data) display(df)
三步,这是基本操作,比较简单。但是,有时候你遇到的情况可能比这复杂一些。
比如,如果你要将Python中的OrderedDict对象转化为DataFrame:
from collections import OrderedDict
data= OrderedDict([('Trend', [4.1, -1.8, 0.1, -0.1, -1.0]),
('Rank',[1, 2, 3, 4, 5]),
('Language', ['Python', 'Java', 'Javascript', 'C#', 'PHP']),
('Share', [29.88, 19.05, 8.17, 7.3, 6.15])])
display(data)

到现在为止,我们使用的就是pd.DataFrame(data)实现了转化。其实,还有一些参数,如果使用了,能够让转化的结果更多样。
例如,在创建DataFrame对象时,指定行索引,而不是像前面那样使用默认的数字。
rom collections import OrderedDict
data = OrderedDict([('Trend', [4.1, -1.8, 0.1, -0.1, -1.0]),
('Rank',[1, 2, 3, 4, 5]),
('Language', ['Python', 'Java', 'Javascript', 'C#', 'PHP']),
('Share', [29.88, 19.05, 8.17, 7.3, 6.15])])
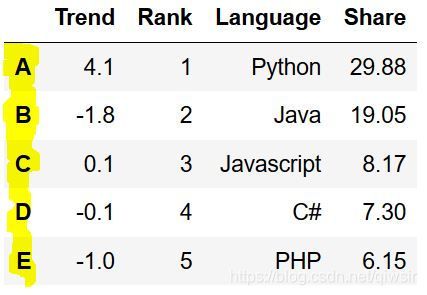
df = pd.DataFrame(data, index = ['A', 'B', 'C', 'D', 'E'])
display(df)
此外,也可以使用columns这个参数,来指定列索引的名称。
或许,你不需要字典中的所有数据,那就用columns参数进行筛选吧。
from collections import OrderedDict
data = OrderedDict([('Trend', [4.1, -1.8, 0.1, -0.1, -1.0]),
('Rank',[1, 2, 3, 4, 5]),
('Language', ['Python', 'Java', 'Javascript', 'C#', 'PHP']),
('Share', [29.88, 19.05, 8.17, 7.3, 6.15])])
df = pd.DataFrame(data, index = ['A', 'B', 'C', 'D', 'E'],
columns=['Language', 'Share'])
display(df)

在上述的示例中,都是以字典的键作为DataFrame中的特征(列)名称,下面的示例演示一种旋转的方式,即键作为行索引。
df = pd.DataFrame.from_dict(data, orient='index')
df.head()
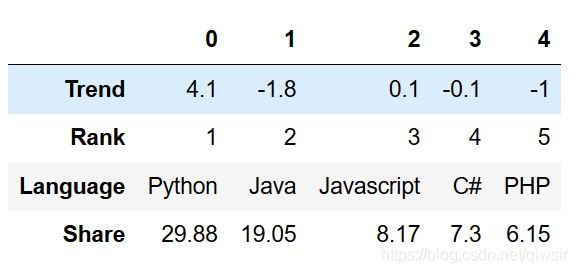
从上面的输出结果中可以看到,这时候的列索引,都采用了默认的数字,也可以指定有意义的名称。
df = pd.DataFrame.from_dict(data, orient='index',
columns=['A', 'B', 'C', 'D', 'F'])
df.head()

当DataFrame对象创建了之后,可以把它保存为csv文件。
df.to_csv('top5_prog_lang.csv')
很多时候是从CSV等格式的文件中读取数据,此外,也有可能遇到上面各个示例的情景,需要将字典转化为DataFrame。
参考资料:https://www.marsja.se/how-to-convert-a-python-dictionary-to-a-pandas-dataframe/