python深度学习Tensorflow基础(一)
Tensorflow基础
- Tensorflow基础
- Tensorflow系统架构
- 数据流图
- Tensorflow基本概念
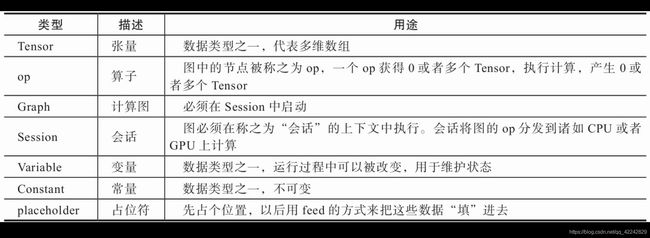
- 张量
- 算子
- 计算图
- 会话
- 常量
Tensorflow基础
Tensorflow系统架构
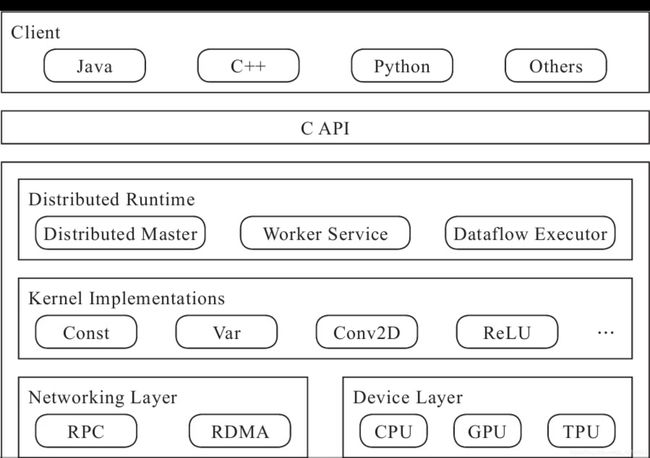
.Client:多语言的编程环境
·Distributed Master从计算图中反向遍历,找到所依赖的最小子图,再把最小子图分割成子图片段派发给Worker Service。随后Worker Service启动子图片段的执行过程。
·Worker Service可以管理多个设备。Worker Service将按照从Distributed Master接收的子图在设备上调用的Kernel实现完成运算,并发送结果给其他Work Service,以及接收其他Worker Service的运算结果。
·Kernel是Operation在不同硬件设备的运行和实现,它负责执行具体的运算。
数据流图
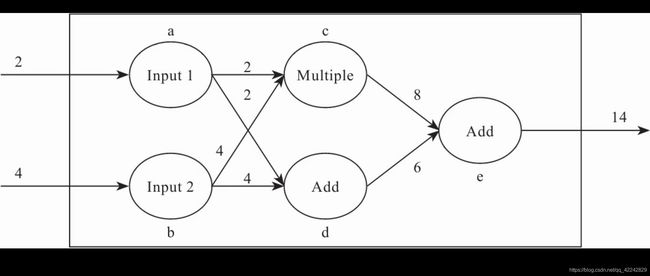
数据流图由节点a、b、c、d、e和相应的边组成,有两个输入和一个输出,其运算可通过以下代码实现:
a=Input1;
b=Input2
c=a*b;
d=a+b
e=c+d
Tensorflow基本概念
张量,会话,变量,占位符,图。
张量
张量可以理解为多维数组。
张量的维度与shape之间的对应关系:

算子
算子:张量执行运算的节点。
算子类型:

算子类别:

计算图
要使用Graph,首先是创建Graph,然后用with语句,通知TensorFlow我们需要把一些op添加到指定的Graph中。
#创建一个新的数据流图
graph = tf.Graph()
with graph.as_default():
a = tf.add(2,4)
b = tf.multiply(2,4)
#多个Graph
graph1 = tf.Graph()
graph2 = tf.Graph()#graph2 = tf.get_default_graph()
with graph1.as_default():
a = tf.add(2, 4)
b = tf.multiply(2, 4)
with graph2.as_default():
a = tf.add(2, 4)
b = tf.multiply(2, 4)
会话
Graph仅仅定义了所有op与tensor流向,没有进行任何计算。而session根据graph的定义分配资源,计算op,得出结果。构造session的方法为tf.Session(),它有三个可选参数,如tf.Session(target=’’,graph=None,config=None)。
·target参数一般为空字符串,它指定要使用的执行引擎。在分布式设置中使用Session对象时,该参数用于连接不同tf.train.Server实例。
·graph参数指定将要在Session中加载的Graph对象,默认值为None,表示使用当前默认数据流图。
·config参数允许用户选择Session的配置,例如限制CPU或者是GPU的使用数量,设置图中的优化参数、日志选项。
语法格式为
sess.run(fetches,feed_dict = None,options = None,run_metadata = None)
fetches为图中要执行的元素(张量,op)。
a = tf.add(2,4)
b = tf.multiply(a,5)
sess = tf.Session()
sess.run(b)
feed_dict可以用于覆盖图中Tensor值。
a = tf.add(2,4)
b = tf.multiply(a,5)
sess = tf.Session()
dict = {a:100}
sess.run(b,feed_dict=dict)
sess.close()
#b=500
常量
格式为:
tf.constant(value, dtype=None,shape=None, name=‘Const’, verify_shape=False)
其中各参数说明如下:
·value:一个dtype类型(如果指定了)的常量值(列表)。要注意的是,若value是一个列表,那么列表的长度不能够超过形状参数指定的大小(如果指定了)。如果列表长度小于指定的大小,那么多余的空间由列表的最后一个元素来填充。
·dtype:返回tensor的类型。
·shape:返回的tensor形状。
·name:tensor的名字。
·verify_shape:布尔值,用于验证值的形状。
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
a = tf.constant(1.,name="a")
b = tf.constant(3.,shape=[2,2],name="b")
sess = tf.Session()
result_a = sess.run([a,b])
print(result_a[0])
print(result_a[1])