前言
JMM即java内存模型,JMM研究的就是多线程下Java代码的执行顺序,共享变量的读写。它定义了Java虚拟机在计算机内存中的工作方式。从抽象角度看,JMM定义了线程和主存之间的抽象关系:线程之前的共享变量存储在主内存中,每个线程有个私有的本地内存,本地内存中存储了该线程读写共享变量的副本。本地内存是JMM的一个抽象概念,并不真实存在。它涵盖了缓存、写缓冲区、寄存器以及其他硬件和编译器优化。
先抛出两个问题:
- 你写的代码一定是实际运行的代码吗?
- 代码的编写顺序,一定是实际执行的顺序吗?
参考文献:
Java Language Specification Chapter 17. Threads and Locks
JSR-133: JavaTM Memory Model and Thread Specification
Doug Lea' s JSR-133 cookbook
书籍:《Java Concurrency in Practice》
并发测试框架:jcstress
多线程读写共享变量
问题演示
猜猜一下代码在多线程的情况下,会发生什么样的情况?
永远的循环
boolean stop;
@Actor
public void a1() {
while(!stop){
}
}
@Signal
void a2() {
stop = true;
}
加加减减
int balance = 10;
@Actor
public void deposit() {
balance += 5;
}
@Actor
public void withdraw() {
balance -= 5;
}
@Arbiter
public void query(I_Result r) {
r.r1 = balance;
}
第四种可能
int a;
int b;
@Actor
public void actor1(II_Result r) {
b = 1;
r.r2 = a;
}
@Actor
public void actor2(II_Result r) {
a = 2;
r.r1 = b;
}
问题解密
循环问题-揭秘
为了方便测试,改造下代码:
package com.study.demo6;
import java.util.concurrent.TimeUnit;
public class WhileTest {
static boolean stop;
public static void a1() {
while (true) {
boolean b = stop;
if (b) {
break;
}
}
}
public static void main(String[] args) {
new Thread(() -> {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
stop = true;
System.out.println("stop>>>>>>>true!");
}).start();
a1();
}
}
运行结果:
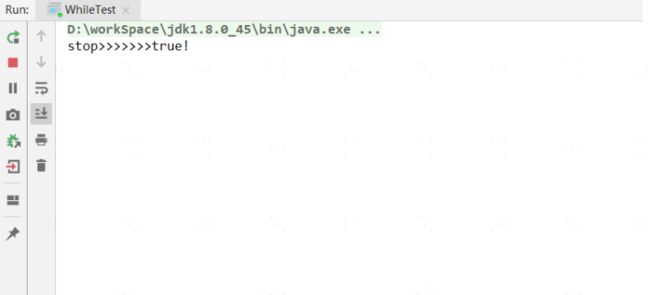
发现main主线程中,调用了啊a1()方法,子线程1秒后,对stop修改了true,按正常逻辑,死循环应该会break终止了,但是实际上运行,我们发现,一直在循环中,并未终止!
提示:
先用 -XX:+PrintCompilation 来查看即时编译情况(% 的含义 On-Stack-Replacement(OSR))
再尝试用 -Xint 强制解释执行
加加减减问题-解密
代码演示
package com.study.demo6;
import java.util.Arrays;
import java.util.List;
public class AddSubTest {
static int balance = 10;
private static void add(){
balance+=5;
}
private static void sub(){
balance-=5;
}
public static void main(String[] args) throws InterruptedException {
List threadList = Arrays.asList(new Thread(AddSubTest::add), new Thread(AddSubTest::sub));
threadList.forEach(Thread::start);
for (Thread thread : threadList) {
thread.join();
}
System.out.println(balance);
}
}
这回用一下ASM 工具,可以看到源码第10 行的 balance += 5 的字节码如下
LINENUMBER 8 L0
GETSTATIC TestAddSub.balance : I
ICONST_5
IADD
PUTSTATIC TestAddSub.balance : I
而第13 行的 balance -= 5 字节码如下
LINENUMBER 12 L0
GETSTATIC TestAddSub.balance : I
ICONST_5
ISUB
PUTSTATIC TestAddSub.balance : I
换成伪代后
static int balance = 10;
private static void add(){
//balance+=5;
int b = balance;
b += 5;
balance = b;
}
private static void sub(){
//balance-=5;
int c = balance;
c -= 5;
balance = c;
}
可能出现的执行顺序如下:
case1: 线程1和2串行
int b = balance; // 线程1
b += 5; // 线程1
balance = b; // 线程1
int c = balance; // 线程2
c -= 5; // 线程2
balance = c; // 线程2
case2:线程1和线程2同时拿到10,线程1执行完,线程2再执行完
int c = balance; // 线程2
int b = balance; // 线程1
b += 5; // 线程1
balance = b; // 线程1
c -= 5; // 线程2
balance = c; // 线程2
case3:线程1和线程2同时拿到10,线程2执行完,线程1再执行完
int b = balance; // 线程1
int c = balance; // 线程2
c -= 5; // 线程2
balance = c; // 线程2
b += 5; // 线程1
balance = b; // 线程1
第四种可能-揭秘
代码演示:
package com.study.demo6;
public class FourthResultTest {
int a;
int b;
private void actor1(IIResult r){
b=1;
r.r2 = a;
}
private void actor2(IIResult r){
a=2;
r.r1 = b;
}
}
可能出现的结果
case1:
b = 1; // 线程1
r.r2 = a; // 线程1
a = 2; // 线程2
r.r1 = b; // 线程2
// 结果 r1==1, r2==0
case2:
a = 2; // 线程2
r.r1 = b; // 线程2
b = 1; // 线程1
r.r2 = a; // 线程1
// 结果 r1==0, r2==2
case3:
a = 2; // 线程2
b = 1; // 线程1
r.r2 = a; // 线程1
r.r1 = b; // 线程2
// 结果 r1==1, r2==2
case4:这种结果是不是超乎你的预期了?这是因为可能是编译器调整了指令执行顺序
r.r2 = a; // 线程1
a = 2; // 线程2
r.r1 = b; // 线程2
b = 1; // 线程1
// 结果 r1==0, r2==0
思考为什么
-
如果让一个线程总是占用CPU 是不合理的,所有任务调度器会让线程分时使用CPU
-
编译器以及硬件层面都会做层层优化,提升性能
-
Compiler/JIT 优化
-
Processor 流水线优化
-
Cache 优化
编辑器优化
case1:
//优化前
x=1
y="universe"
x=2
//优化后
y="universe"
x=2
case2:
//优化前
for(i=0;icase3:
//优化前
if(x>=0){
y = 1;
// ...
}
//优化后
y = 1;
if(x>=0){
// ...
}
Processor优化
流水线在CPU 的一个时钟周期内会执行多个指令的不同部分
非流水线操作
假设有三条指令
---|---|---|
1 2 3
每条指令执行花费300ps 时间,最后将结果存入寄存器需要20ps
一秒能运行的指令数为
![]()
流水线操作
仔细分析就会发现,可以把每个指令细分为三个阶段
A|B|C| // 1
A|B|C| // 2
A|B|C| // 3
增加一些寄存器,缓存每一阶段的结果,这样就可以在执行 指令1-C 阶段时,同时执行 指令2-B 以及 指令3-A
一秒能运行的指令数为
![]()
execute out of order
- 在按序执行中,一旦遇到指令依赖的情况,流水线就会停滞
- 如果采用乱序执行,就可以跳到下一个非依赖指令并发布它。这样,执行单元就可以总是处于工作状态,把
时间浪费减到最少
缓存优化
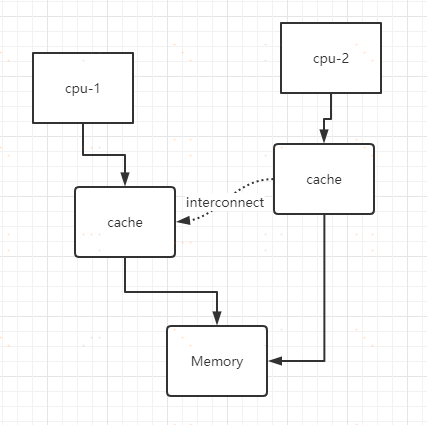
MESI (CPU缓存一致性)协议 引入缓存的副作用在于同一份数据可能保存了副本,一致性该如何保证呢?
- Modified - 要向其它CPU 发送cache line 无效消息,并等待ack
- Exclusive - 独占、即将要执行修改
- Shared - 共享、一般读取时的初始状态
- Invalid - 一旦发现数据无效,需要重新加载数据
例子
就上文所说的第四种可能:r1 和r2 有没有可能同时为0
r.r1 = b; // 线程2 与 a = 2 重排
r.r2 = a; // 线程1 与 a = 1 重排
b = 1; // 线程1
a = 2; // 线程2
下面从缓存的角度分析,注意假定指令没有重排
b = 1; // 线程1 - 写入 CPU-0 的 store buffer
a = 2; // 线程2 - 写入 CPU-1 的 store buffer
r.r1 = b; // 线程2 - 马上执行
r.r2 = a; // 线程1 - 马上执行
// 线程1 - 将 store buffer 中的 b = 1 写入 cache, 晚了
// 线程2 - 将 store buffer 中的 a = 2 写入 cache, 晚了
我们关注问题的点
以上介绍了多线程读写共享变量可能发生的哪些问题?但对于程序员而言,我们不应当关注究竟是编译器优化、Processor 优化、缓存优化。否则,就好像打开了潘多拉魔盒!
JMM内存模型
什么是JMM
A memory model describes, given a program and an execution trace of that program, whether the execution trace is a legal execution of the program. A high level, informal overview of the memory model shows it to be a set of rules for when writes by one thread are visible to another thread.
多线程下,共享变量的读写顺序是头等大事,内存模型就是多线程下对共享变量的一组读写规则
- 共享变量值是否在线程间同步
- 代码可能的执行顺序
- 需要关注的操作就有两种Load、Store
- Load 就是从缓存读取到寄存器中,如果一级缓存中没有,就会层层读取二级、三级缓存,最后才是Memory
- Store 就是从寄存器运算结果写入缓存,不会直接写入Memory,当Cache line 将被eject 时,会
writeback 到Memory
JMM规范
规则一 Race Condition
在多线程下,没有关系依赖的代码,在操作共享变量时(至少有一个线程写),并不能保证按编写顺序(Program Order)执行,这称为发生了竞态条件(Race Conditon)。
例如
有共享变量 x,线程 1 执行
r.r1 = y;
r.r2 = x;
线程 2 执行
x = 1;
y = 1;
最终的结果可能是 r11 而 r20
竞态条件是为了更好的 data race free。
规则二 Syncronization Order
若要保证多线程下,每个线程的执行顺序(Synchronization Order)按编写顺序(Program Order)执行,那么必须使用 Synchronization Actions 来保证,这些 SA 有
-
lock,unlock
-
volatile 方式读写变量
-
VarHandle 方式读写变量
Synchronization Order 也称之为 Total Order
例如
用 volatile 修饰共享变量 y,线程 1 执行
r.r1 = y;
r.r2 = x;
线程 2 执行
x = 1;
y = 1;
最终的结果就不可能是 r11 而 r20
SO并不是阻止多线程切换
错误的认识,线程 1 执行
synchronized(LOCK) {
r1 = x; //1 处
r2 = x; //2 处
}
线程 2 执行
synchronized(LOCK) {
x = 1
}
并不是说 //1 与 //2 处之间不能切换到线程 2,只是即使切换到了线程 2,因为线程 2 不能拿到 LOCK 锁导致被阻塞,执行权又会轮到线程 1
volatile 只用了一半算 SO 吗?
用例1
int x;
volatile int y;
之后采用
x = 10; //1 处
y = 20; //2 处
此时 //1 处代码绝不会重排到 //2 处之后(只写了 volatile 变量)
用例 2
int x;
volatile int y;
执行下面的测试用例
@Actor
public void a1(II_Result r) {
y = 1; //1 处
r.r2 = x; //2 处
}
@Actor
public void a2(II_Result r) {
x = 1; //3 处
r.r1 = y; //4 处
}
//1 //2 处的顺序可以保证(只写了 volatile 变量),但 //3 //4 处的顺序却不能保证(只读了 volatile 变量),仍会出现 r1r20 的问题
有时会很迷惑人,例如下面的例子
用例3
@Actor
public void a1(II_Result r) {
r.r2 = x; //1 处
y = 1; //2 处
}
@Actor
public void a2(II_Result r) {
r.r1 = y; //3 处
x = 1; //4 处
}
这回 //1 //2 (只写了 volatile 变量)//3 //4 处(只读了 volatile 变量)的顺序均能保证了,绝不会出现r1r21 的情况
此外将用例 2 中两个变量均用 volatile 修饰就不会出现 r1r20 的问题,因此也把全部都用 volatile 修饰称为total order,部分变量用 volatile 修饰称为 partial order
规则三 Happens Before
若是变量读写时发生线程切换(例如,线程 1 写入 x,切换至线程 2,线程 2 读取 x)在这些边界的处理上如果有action1 先于 action 2 发生,那么代码可以按确定的顺序执行,这称之为 Happens-Before Order 规则(Happens-Before Order 也称之为 Partial Order).
用公式表达就是:

含义为:如果 action1 先于 action2 发生,那么 action1 之前的共享变量的修改对于 action2 可见,且代码按 PO顺序执行
具体规则
其中 $T_{n}$ 代表线程,而 x 未加说明,是普通共享变量,使用 volatile 会单独说明
1)线程的启动和运行边界

2)线程的结束和join边界

3)线程的打断和得知打断的边界
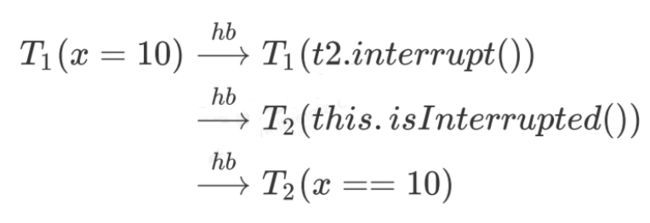
4)unlock 与 lock 边界

5)volatile write 与 volatile read 边界
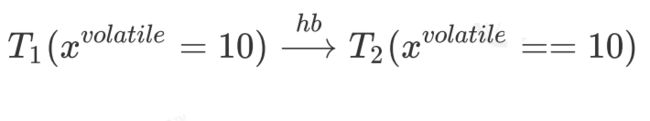
6)传递性
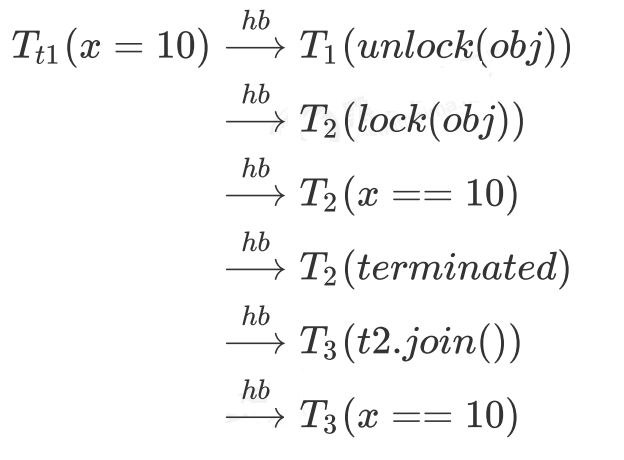
规则四 Causality
Causality 即因果律:代码之间如存在依赖关系,即使没有加 SA 操作,代码的执行顺序也是可以预见的
回顾一下
多线程下,没有依赖关系的代码,在共享变量读写操作(至少有一个线程写)时,并不能保证以编写顺序(Program Order)执行,这称为发生了竞态条件(Race Condition)
如果有一定的依赖关系呢?
@JCStressTest
@Outcome(id = {"0", "0"}, expect = Expect.ACCEPTABLE, desc = "ACCEPTABLE")
@Outcome(expect = Expect.FORBIDDEN, desc = "FORBIDDEN")
@State
public class Case {
int x;
int y;
@Actor
public void a1(IIResult r) {
r.r1 = x;
y = r.r1;
}
@Actor
public void a2(IIResult r){
r.r2 = y;
x = r.r2;
}
}
x 的值来自于 y,y 的值来自于 x,而二者的初始值都是 0,因此没有可能有其他结果
规则五安全发布
若要安全构造对象,并将其共享使用,需要用 final 或 volatile 修饰其成员变量,并避免 this 溢出情况(静态成员变量可以安全地发布)
例如
class Holder{
int x1;
volatile int x2;
public Holder(int x) {
x1=x;
x2=x;
}
}
需要将它作为全局使用
Holder f;
两个线程,一个创建,一个使用
Holder holder;
@Actor
public void a1(){
holder = new Holder(1);
}
@Actor
public void a2(IIResult r){
Holder holder = this.holder;
if (holder != null){
r.r1 = holder.x1 +holder.x2;
}else {
r.r1 = -1;
}
}
可能看见未构造完整的对象
同步动作
前面没有详细展开从规则 2 之后的讲解,是因为要理解规则,还需理解底层原理,即内存屏障
内存屏障
LoadLoad

-
防止 y 的 Load 重排到 x 的 Load 之前
if(x) { LoadLoad return y } -
意义:x == true 时,再去获取 y,否则可能会由于重排导致 y 的值相对于 x 是过期的
LoadStore

- 防止 y 的 Store 被重排到 x 的 Load 之前
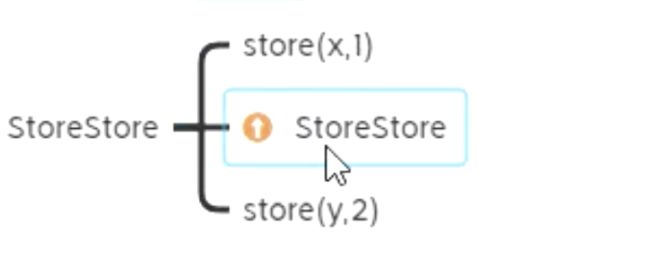
StoreSotre
-
防止 A 的 Store 被重排到 B 的 Store 之后
A = x StoreStore B = true -
意义:在 B 修改为 true 之前,其它线程别想看到 A 的修改
- 有点类似于 sql 中更新后,commit 之前,其它事务不能看到这些更新(B 的赋值会触发 commit 并撤除屏障)
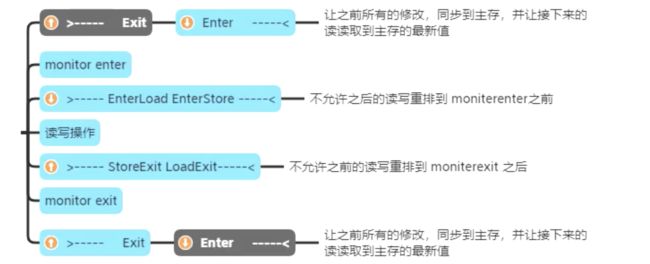
StoreLoad
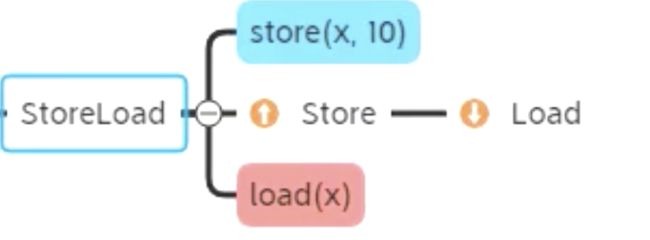
- 意义:屏障前的改动都同步到主存 ,屏障后的 Load 获取主存最新数据,发生在线程切换时,并且使得蓝色线程所有的写操作写入主存,使得红色线程能读取到最新数据
- 防止屏障前所有的写操作,被重排序到屏障后的任何的读操作,可以认为此 store -> load 是连续的
- 有点类似于 git 中先 commit,再远程 poll,而且这个动作是原子的
如何记忆
- LoadLoad + LoadStore = Acquire 即让同一线程内读操作之后的读写上不去,第一个 Load 能读到主存最新值
- LoadStore + StoreStore = Release 即让同一线程内写操作之前的读写下不来,后一个 Store 能将改动都写入主存
- StoreLoad 最为特殊,还能用在线程切换时,对变量的写操作 + 读操作做同步,只要是对同一变量先写后读,那么屏障就能生效
Volatile
本质
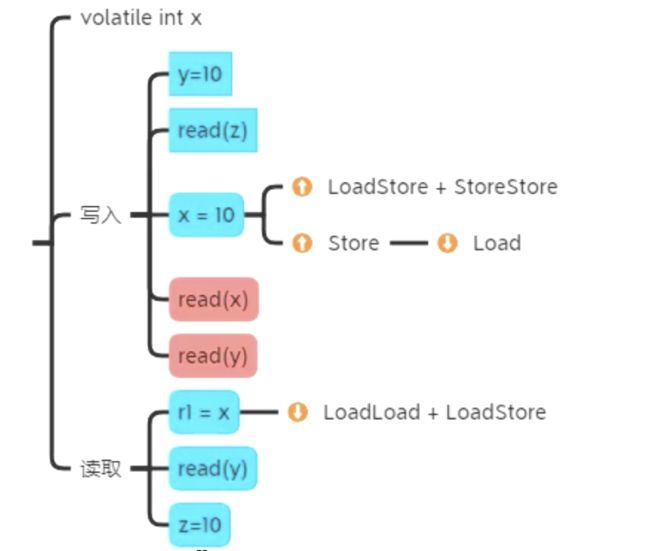
事实上对 volatile 而言 Store-Load 屏障最为有用,简化起见以后的分析省略部分其他屏障
作用
- 保证单一变量的原子性
- 控制了可能的执行路径: 线程内按屏障有序,线程切换时按HB有序
- 可见性:线程切换时若发生了读写则变量可见,顺带影响普通变量可见
volatile的用途
凡是需要cas操作的地方
比如AtomicInteger的源码
public class AtomicInteger extends Number implements java.io.Serializable {
private static final Unsafe U = Unsafe.getUnsafe();
private static final long VALUE = U.objectFieldOffset(AtomicInteger.class, "value");
private volatile int value;
// ...
public final boolean compareAndSet(int expectedVal, int newVal) {
return U.compareAndSetInt(this, VALUE, expectedVal, newVal);
}
// ...
}
AbstractQueuedSynchronizer的源码
public abstract class AbstractQueuedSynchronizer extends AbstractOwnableSynchronizer implements java.io.Serializable {
private transient volatile Node head;
private transient volatile Node tail;
private volatile int state;
protected final int getState() {
return state;
}
protected final boolean compareAndSetState(int e, int n) {
return U.compareAndSetInt(this, STATE, e, n);
}
final void enqueue(Node node) {
if (node != null) {
for (; ; ) {
Node t = tail;
node.setPrevRelaxed(t);
if (t == null) tryInitializeHead();
else if (casTail(t, node)) {
t.next = node;
if (t.status < 0) LockSupport.unpark(node.waiter);
break;
}
}
}
}
private void tryInitializeHead() {
Node h = new ExclusiveNode(); // 头
if (U.compareAndSetReference(this, HEAD, null, h)) tail = h;
}
private boolean casTail(Node c, Node v) {
return U.compareAndSetReference(this, TAIL, c, v);
}
}
ConcurrentHashMap源码
public class ConcurrentHashMap extends AbstractMap implements ConcurrentMap, Serializable {
/**
* Table initialization and resizing control. When negative, the
* table is being initialized or resized: -1 for initialization,
* else -(1 + the number of active resizing threads). Otherwise,
* when table is null, holds the initial table size to use upon
* reation, or 0 for default. After initialization, holds the
* next element count value upon which to resize the table.
*/
private transient volatile int sizeCtl;
/**
* The array of bins. Lazily initialized upon first insertion.
* Size is always a power of two. Accessed directly by iterators.
*/
transient volatile Node[] table;
private final Node[] initTable() {
Node[] tab;
int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0) Thread.yield();
else if (U.compareAndSetInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
Node[] nt = (Node[]) new Node[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
// ...
}
volatile负责保证可见性,cas来保证原子
Synchronized
本质
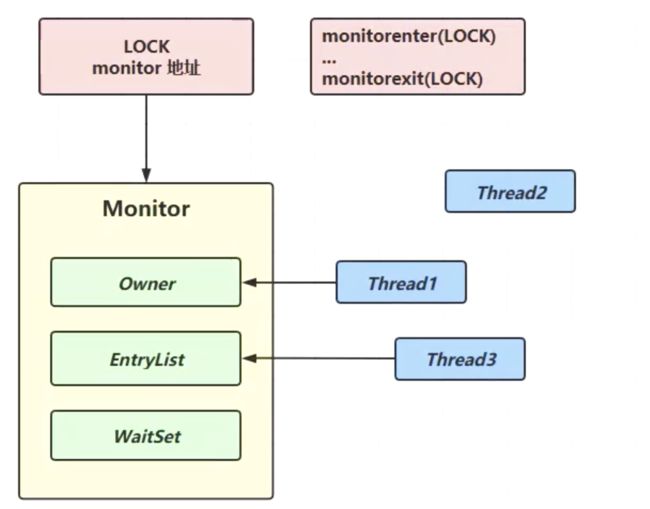
起始synchronized本质就是通两个JVM指令:monitorenter和monitorexit来实现了,我们可以通过下面一段代码的来研究下,其原理
package com;
public class SynchronizedTest {
static int i = 0;
public static void main(String[] args) {
synchronized (SynchronizedTest.class){
i++;
}
}
}
通过反编译看下
#......
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=3, args_size=1
0: ldc #2 // class com/SynchronizedTest
2: dup
3: astore_1
4: monitorenter
5: getstatic #3 // Field i:I
8: iconst_1
9: iadd
10: putstatic #3 // Field i:I
13: aload_1
14: monitorexit
15: goto 23
18: astore_2
19: aload_1
20: monitorexit
21: aload_2
22: athrow
23: return
#......
可以看到就是通过jvm指令monitorenter、monitorexit实现的,结合上图,具体步骤如下:
我们知道synchronized是通加对象锁来实现的,但是这个对象是否作为锁而存在呢?
- 当线程1执行synchronized时,jvm调用monitorenter时,就会先操作系统申请一个操作系统的Moniter锁(底层由c++实现的),并把其地址存放在LOCK对象头中。
- 当线程1根据LOCK对象头找到Moniter锁,判断owner是否被占用,没有被占用,就会修改其值,等于持有了锁。
- 大概线程2同样会执行monitorenter指令,根据LOCK对象头找到Moniter锁,判断owner是否被占用,发现已经被占用,首先会自旋尝试获取,一定次数没获取到,就会进入EntryList队列等待,并从运行状态变成阻塞状态,线程3也是如此。
- 当线程1执行完毕或出现异常时就会执行monitorexit,释放owner并唤醒EntryList中的被阻塞线程,具体都队列头还是队列尾部去唤醒,这个根据具体算法实现,这里不做赘述。
- 假如线程2被唤醒就会去获取owner是否空闲,空闲了就占用,线程3依然处于阻塞状态。
相关内存屏障
优化(JDK1.6之后)
- 重量级
- 当有竞争时,仍会向系统申请 Monitor 互斥锁
- 轻量级锁
- 如果线程加锁、解锁时间上刚好是错开的,这时候就可以使用轻量级锁,只是使用 cas 尝试将对象头替换为该线程的锁记录地址,如果 cas 失败,会锁重入或触发重量级锁升级
- 偏向锁
- 打个比方,轻量级锁就好比用课本占座,线程每次占座前还得比较一下,课本是不是自己的(cas),频繁 cas 性能也会受到影响
- 而偏向锁就好比座位上已经刻好了线程的名字,线程【专用】这个座位,比 cas 更为轻量
- 但是一旦其他线程访问偏向对象,那么比较麻烦,需要把座位上的名字擦去,这称之为偏向锁撤销,锁也升级为轻量级锁
- 偏向锁撤销也属于昂贵的操作,怎么减少呢,JVM 会记录这一类对象被撤销的次数,如果超过了 20 这个阈值,下次新线程访问偏向对象时,就不用撤销了,而是刻上新线程的名字,这称为重偏向
- 如果撤销次数进一步增加,超过 40 这个阈值,JVM 会认为这一类对象不适合采用偏向锁,会对它们禁用偏向锁,下次新建对象会直接加轻量级锁
无锁与有锁
-
synchronized 更为重量,申请锁、锁重入都要发起系统调用,频繁调用性能会受影响
-
synchronized 如果无法获取锁时,线程会陷入阻塞,引起的线程上下文切换成本高
-
虽然做了一系列优化,但轻量级锁、偏向锁都是针对无数据竞争场景的
-
如果数据的原子操作时间较长,仍应该让线程阻塞,无锁适合的是短频快的共享数据修改操作主要用于计数器、停止标记、或是阻塞前的有限尝试
VarHandle
目前无锁问题实现
目前Java 中的无锁技术主要体现在以AtomicInteger 为代表的的原子操作类,它的底层使用Unsafe 实现,而Unsafe 的问题在于安全性和可移植性
此外,volatile 主要使用了Store-Load 屏障来控制顺序,这个屏障还是太强了,有没有更轻量级的解决方法呢?
Varhandle快速上手
在Java9 中引入了VarHandle,来提供更细粒度的内存屏障,保证共享变量读写可见性、有序性、原子性。提供了更好的安全性和可移植性,替代Unsafe 的部分功能
创建
public class TestVarHandle {
int x;
static VarHandle X;
static {
try {
X = MethodHandles.lookup()
.findVarHandle(TestVarHandle.class, "x", int.class);
} catch (NoSuchFieldException | IllegalAccessException e) {
e.printStackTrace();
}
}
}
读写
| 方法名 | 作用 | 说明 |
|---|---|---|
| get | 获取值 | 与普通变量取值一样,会重排、有不可见现象 |
| set | 设置值 | |
| getOpaque | 获取值 | 对其保护的变量,保证其不重排和可见性,但不使用屏障,不阻碍其它变量 |
| setOpaque | 设置值 | |
| getAcquire | 获取值 | 相当于get 之后加LoadLoad + LoadStore |
| setRelease | 设置值 | 相当于set 之前加LoadStore + StoreStore |
| getVolatile | 获取值 | 语义同volatile,相当于获取之后加LoadLoad + LoadStore |
| setVolatile | 设置值 | 语义同volatile,相当于设置之前加LoadStore + StoreStore,设置之后加StoreLoad |
| compareAndSet | 原子赋值 | 原子赋值,成功返回true,失败返回false |
更多安全问题
单个变量读写原子性
-
64 位系统vs 32 位系统
如果需要保证long 和double 在32 位系统中原子性,需要用volatile 修饰 -
JMM9 之前
JMM9 32 位系统下double 和long 的问题,double 没有问题,long 在-server -XX:+UnlockExperimentalVMOptions -XX:-AlwaysAtomicAccesses 才有问题
Object alignment
你或许听说过对象对齐,它的一个主要目的就是为了单个变量读写的原子性,可以使用jol 工具查看java 对象的内存布局
org.openjdk.jol
jol-core
0.10
测试类
public class TestJol {
public static void main(String[] args) {
String layout = ClassLayout.parseClass(Test.class).toPrintable();
System.out.println(layout);
}
public static class Test {
private byte a;
private byte b;
private byte c;
private long e;
}
}
开启对象头压缩(默认)输出
com.itheima.test.TestJol$Test object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 12 (object header) N/A
12 1 byte Test.a N/A
13 1 byte Test.b N/A
14 1 byte Test.c N/A
15 1 (alignment/padding gap)
16 8 long Test.e N/A
Instance size: 24 bytes
Space losses: 1 bytes internal + 0 bytes external = 1 bytes total
不开启对象头压缩 -XX:-UseCompressedOops 输出
com.itheima.test.TestJol$Test object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 16 (object header) N/A
16 8 long Test.e N/A
24 1 byte Test.a N/A
25 1 byte Test.b N/A
26 1 byte Test.c N/A
27 5 (loss due to the next object alignment)
Instance size: 32 bytes
Space losses: 0 bytes internal + 5 bytes external = 5 bytes total
字分裂
前面也看到了,Java 能够保证单个共享变量读写是原子的,类似的数组元素的读写,也会提供这样的保证
byte[8]
[0][1][2][3]
[0][1][2][3]
如果上述效果不能保证,则称之为发生了字分裂现象,java 中没有字分裂,但Java 中某些实现会有类似字分裂现象,例如BitSet、Unsafe 读写等
数组元素读写测试
@JCStressTest
@Outcome(id = {"0", "-1"}, expect = Expect.ACCEPTABLE, desc = "ACCEPTABLE")
@Outcome(expect = Expect.FORBIDDEN, desc = "FORBIDDEN")
@State
public static class Case4 {
byte[] b = new byte[256];
int off = ThreadLocalRandom.current().nextInt(256);
@Actor
public void actor1() {
b[off] = (byte) 0xFF;
}
@Actor
public void actor2(I_Result r) {
r.r1 = b[off];
}
}
BigSet读写测试
@JCStressTest
@Outcome(id = "true, true", expect = Expect.ACCEPTABLE, desc = "ACCEPTABLE")
@Outcome(expect = Expect.ACCEPTABLE_INTERESTING, desc = "INTERESTING")
@State
public static class Case6 {
BitSet b = new BitSet();
@Actor
public void a() {
b.set(0);
}
@Actor
public void b() {
b.set(1);
}
@Arbiter
public void c(ZZ_Result r) {
r.r1 = b.get(0);
r.r2 = b.get(1);
}
}
Unsafe 直接操作内存
public class TestUnsafe {
public static final long ARRAY_BASE_OFFSET =
UnsafeHolder.U.arrayBaseOffset(byte[].class);
static byte[] ss = new byte[8];
public static void main(String[] args) {
System.out.println(ARRAY_BASE_OFFSET);
UnsafeHolder.U.putInt(ss, ARRAY_BASE_OFFSET, 0xFFFFFFFF);
System.out.println(Arrays.toString(ss));
}
}
输出
16
[-1, -1, -1, -1, 0, 0, 0, 0]
来个压测
@JCStressTest
@Outcome(id = "0", expect = Expect.ACCEPTABLE, desc = "ACCEPTABLE")
@Outcome(id = "-1", expect = Expect.ACCEPTABLE, desc = "ACCEPTABLE")
@Outcome(expect = Expect.ACCEPTABLE_INTERESTING, desc = "INTERESTING")
@State
public static class Case5 {
byte[] ss = new byte[256];
long base = UnsafeHolder.U.arrayBaseOffset(byte[].class);
long off = base + ThreadLocalRandom.current().nextInt(256 - 4);
@Actor
public void writer() {
UnsafeHolder.U.putInt(ss, off, 0xFFFF_FFFF);
}
@Actor
public void reader(I_Result r) {
r.r1 = UnsafeHolder.U.getInt(ss, off);
}
}
结果:
Observed state Occurrences Expectation Interpretation
-1 25,591,098 ACCEPTABLE ACCEPTABLE
-16777216 877 ACCEPTABLE_INTERESTING INTERESTING
-256 923 ACCEPTABLE_INTERESTING INTERESTING
-65536 925 ACCEPTABLE_INTERESTING INTERESTING
0 5,093,890 ACCEPTABLE ACCEPTABLE
16777215 1,673 ACCEPTABLE_INTERESTING INTERESTING
255 1,758 ACCEPTABLE_INTERESTING INTERESTING
65535 1,707 ACCEPTABLE_INTERESTING INTERESTING
安全发布
构造也不安全
@JCStressTest
@Outcome(id = {"16", "-1"}, expect = Expect.ACCEPTABLE, desc = "ACCEPTABLE")
@Outcome(expect = Expect.ACCEPTABLE_INTERESTING, desc = "INTERESTING")
@State
public static class Case1 {
Holder f;
int v = 1;
@Actor
public void a1() {
f = new Holder(v);
}
@Actor
void a2(I_Result r) {
Holder o = this.f;
if (o != null) {
r.r1 = o.x8 + o.x7 + o.x6 + o.x5 + o.x4 + o.x3 + o.x2 + o.x1;
r.r1 += o.y8 + o.y7 + o.y6 + o.y5 + o.y4 + o.y3 + o.y2 + o.y1;
} else {
r.r1 = -1;
}
}
static class Holder {
int x1, x2, x3, x4;
int x5, x6, x7, x8;
int y1, y2, y3, y4;
int y5, y6, y7, y8;
public Holder(int v) {
x1 = v;
x2 = v;
x3 = v;
x4 = v;
x5 = v;
x6 = v;
x7 = v;
x8 = v;
y1 = v;
y2 = v;
y3 = v;
y4 = v;
y5 = v;
y6 = v;
y7 = v;
y8 = v;
}
}
}
原因分析
比如有个Student类代码如下:
public class Student{
final String name;
int age;
public Student(name,age){
this.name =name;
this.age = age;
}
}
Student stu为共享变量
stu = new Student("zhangsan",18);
name如果没有final修饰
t =new Student(name,age)
stu = t
this.name = name
this.age =age
name如果有final修饰,位置任意
t=new Student(name,age)
this.name=name
this.age=age
>----StoreStore----<
stu = t
使用volatile改进
name 有volatile 修饰,注意位置必须在最后
t=new Student(name,age)
this.age=age
this.name=name
>----Store Load----<
stu =t
总结
- JMM 是研究的是
- 多线程下Java 代码的执行顺序,实际代码的执行顺序与你编写的代码顺序不同
- 共享变量的读写操作,在竞态条件下,需要考虑共享变量读写的原子性、可见性、有序性
- 共享变量的问题起因
- 原子性是由于操作系统的分时机制,线程切换所致
- 有序性和可见性可能来自于编译器优化、处理器优化、缓存优化
- JMM 制定了一些规则,理解这些规则,才能写出正确的线程安全代码
- 竞态条件会导致代码顺序被重排
- 利用synchronized、volatile 一些SA,可以控制线程内代码的执行顺序
- 线程切换时的执行顺序与可见性,遵守HB 规则
- HB 规则还不足够,需要因果律作为补充
- 可以通过final 或volatile 实现对象的安全发布
- 从底层理解volatile 与synchronized
- 内存屏障
- synchronized 是如何解决原子性、可见性、有序性问题的,有哪些优化
- volatile 是如何解决可见性、有序性问题的,与cas 结合的威力
- VarHandle 是如何解决可见性、有序性问题的
- 更多安全问题
- 单个变量、数组元素的读写原子性
- 能够列举字分裂的几个相关例子
- 构造方法什么情况下会线程不安全,如何改进
- 彻底掌握DCL 安全单例