【摘要 】本文简单介绍了NAS的发展现况和在语义分割中的应用,并且详细解读了两篇流行的work:DARTS和Auto-DeepLab。
自动网络搜索
多数神经网络结构都是基于一些成熟的backbone,如ResNet, MobileNet,稍作改进构建而成来完成不同任务。正因如此,深度神经网络总被诟病为black-box,因为hyparameter是基于实验求得而并非通过严谨的数学推导。所以,很多DNN研究人员将大量时间花在修改模型和实验“调参”上面,而忽略novelty本身。许多教授戏称这种现象为“graduate student descent”。
近两年,学术界兴起了“自动网络搜索”取代人工设计网络结构。2016年,Google Brain公开了他们的研究成果NASNet【1】,这是第一个用自动网络搜索Neural Architecture Seach (NAS)完成的神经网络,为深度学习打开了新局面。NASNet是由一系列operation(如depth separable conv, max pooling等)叠加而成。至于怎样选择operation,作者用强化学习(RL)的方法,用一个controller网络随机组合operations生成模块,通过评估选择最优模块组成网络结构。Google提供的云上服务Cloud AutoML正是基于NAS方法,根据用户上传的数据自动搜索神经网络再将结果输出。迄今为止,国内外很多工业界和学术界的AI Lab都有NAS相关工作:Google Brain提出了NasNet, MNasNet和Nas-FPN,Google提出MobileNetv3,Auto-DeepLab和Dense Prediction Cell(DPC);MIT Han Song团队提出ProxylessNet;Facebook提出FbNet;Baidu提出SETN;腾讯提出FPNAS;小米提出FairNAS;京东AI提出CAS;华为诺亚有提出P-DARTS等。通过各大实验室对NAS的研究成果,似乎可以看出自动网络搜索将会成为趋势。
接下来我们简单介绍一下NAS的流程,详细内容可参考【2】。NAS的架构主要包含三部分:搜索空间Search Space,搜索策略Search Strategy和评估机制Performance Estimation(如下图)。

- 首先搜索空间会定义一些模块(cell),operations(例如dilated conv 3x3),和宏观网络结构。cell是由若干个operation组合而成。通常来说,NAS会自动搜索出一些可以重复的cell,将cell按照设定的宏观网络结构堆叠起来形成network。Zoph et al.提出了两种cell,normal cell和reduction cell【3】。Reduction cell有改变spatial resolution的功能。这两种cell在现有的算法中最为常见。此外还有来自CAS网络【4】的multi-scale cell,作用和ASPP类似可用作decoder。至于对宏观网络结构的设定,早期的工作会采用chained-structured,或者带分支结构multi-branch例如ResNet和DenseNet带有skip和shortcut。
- 搜索策略在NAS中至关重要,因为它决定了下一步要选择哪一个cell或者operation组成网络结构。搜索的目的就是让现有的网络结构在unseen data上得到最好的效果。如前文提到,第一篇工作NASNet中用到了强化学习作为搜索策略。虽然实验结果尚可,但强化学习耗时过长并且需要大量GPU资源。NASNet就是用几百个GPU搜索了几天才完成,这对于资源少的研究人员来说不可能完成。继NASNet之后早期的工作多是基于RL完成搜索。随着其他方法的研究,如random search, Bayesian optimization, Gradient-based, evolution algorithms,搜索时间在下降并且GPU使用量也在减少,使得NAS得以普及。感谢https://github.com/D-X-Y/Awesome-NAS 提供了搜索策略的调研。
- 由于一个神经网络通常有几十甚至上百层,结构也很复杂,一个及时并有效的反馈对于减少搜索时间很有帮助。最简单的方法是把训练数据分成两部分,train data用来训练网络结构,validation data用来评估当前搜索到的网络结构。一般来说,一个好的评估机制要兼具速度和准确度,举个例子,train data少则网络结构训练不到位,train data多则搜索时间过长。来自Freiburg大学的Elsken团队发表了关于NAS的调研,里面对于评估方法讲的很详细,请挪步【2】。
自动网络搜索在语义分割上的应用
相比于目标检测,语义分割可以更好的解析图像,因为图像上的每一个pixel都会被分类。所以语义分割可以完成目标检测无法完成的任务,如自动驾驶的全景分割,医疗图像诊断,卫星图分割,背景抠图和AR换装等。过去的五年继FCN之后,很多神经网络在公开数据集上都有不错的成绩。随着AI产品落地,对神经网络性能的要求更为严格:在保证accuracy的前提下,在有限制的硬件资源运行并且提升inference速度。这为设计神经网络增加了很大难度。所以NAS是一个很好的选择,它可以避免通过大量调参实验来决定最优网络结构。在语义分割之前,NAS在图像分类和目标检测上均有成功的应用。我们总结了近两年比较流行的NAS在语义分割上的工作。多数的语义分割的网络都是encoder-decoder结构,在这里我们对比了实际搜索的部分,搜索性能耗时和方法。由于每一个work都在不同实验环境下进行,所以实验结果没有直接进行对比。
(1)第一篇将NAS应用于语义分割的工作来自Google DeepLab团队,作者是Liang-Chieh Chen等一众大佬。DeepLabv3+的准确度已经达到一定高度,继而DeepLab团队将研究方向转移到了NAS上面。基于和DeepLab同样的encoder-decoder结构, 在【5】工作中,作者将encoder结构固定,试图搜索出一个更小的 ASPP,用到的搜索策略是random search。在Cityscapes达到82.7% mIoU,在PASCAL VOC 12上达到87.9%,结果尚可但搜索时间过慢,用370个GPU搜索一周才得到网络,这也限制了该方法的普及。
(2)同样来自DeepLab团队,Auto-DeepLab【6】相比之前的工作在搜索效率上有显著的提升。这都归功于它gradient-based的搜索策略DARTS【9】。与上一篇相反,Auto-DeepLab的目标是搜索encoder,而decoder则采用ASPP。从实验结果来看,Auto-DeepLab的准确度和DeepLabv3+相差不多,但是FLOPs和参数数量却是DeepLabv3+的一半。后文我们会具体介绍DARTS和Auto-DeepLab。
(3)Customizable Architecture Search (CAS)【4】是来自京东AI Lab的工作。在搜索空间定义了三种cell,分别是normal cell,reduction cell和新提出的multi-scale cell。其中multi-scale cell是ASPP 的功能类似,所以CAS的搜索区间是针对全部网络。在搜索策略上依然采用DARTS。值得一提的是,在搜索网络的时候,CAS不仅考虑accuracy,还考虑了每个模块的GPU time,CPU time,FLOPs和参数数量。这些属性对于实时任务至关重要。所以CAS在Cityscapes上的准确度是72.3%,虽然没有很高,但是在TitanXP GPU的速度fps达到108。
(4)来自Adeleide大学的Vladimir Nekrasov团队在light weight模型上面做了大量工作,而最近也将研究重心转到了NAS上面。在【7】中,作者采用RL的搜索策略搜索decoder。众所周知RL非常耗时,所以作者采用知识蒸馏策略和Polyak Averaging方法结合提升搜索速度,而这正是本文的major contribution。
(5)最后一篇来自商汤发布在Artix的文章,采用图神经网络GCN作为搜索策略,试图寻找cell之间最优的连接方式【8】。和CAS类似,在本文中每个模块的性能如latency也在搜索评估时考虑进去。在Cityscape上GAS达到73.3%mIoU,在TitanXP GPU的速度是102fps。
简单总结一下上述工作,我们可以发现NAS在语义分割上的应用还算成功,并且很多团队已经在NAS上进行研究探索。尤其在DARTS类似的高效搜索策略提出后,个人研究者和小团队也可以构建自己的NAS网络,而不受制于GPU资源。
DARTS: Differentiable Architecture Search
通常来说搜索空间是一个离散的空间,在DARTS中【9】,作者将搜索空间定义成一个连续空间,这样一来搜索到的每一个cell都是可导的,可以用stochastic gradient descent来优化。所以DARTS相比RL并不需要大量GPU资源和搜索时间。在实验中,DARTS成功用在了CNN模型的图像分类和RNN模型的language modelling任务上。感恩作者提供了源代码 https://github.com/quark0/darts ,它可以为我们搭建自己NAS模型提供很好的基础。
正如前文中提到,多数的NAS网络会搜索不同类型的可重复的cell,然后将cell连接起来构成神经网络。这个cell通常用directed acyclic graph(DAG)表示。一个DAG cell包含N个有顺序的node,每一个node可以看成在它前面所有node的结合(就像feature map一样是一个latent representation)。从node i 到node j的连接是某一种operation记作o(i,j). 每一个cell都有两个input node和一个output node。下图中是一个DARTS展示的reduction cell。我们可以看到cell k 有两个input nodes 分别是c_{k-1}和c_{k-2} (来自cell k-1和cell k-2的output node),cell k包含了4个immediate nodes和一个output node c_{k} 。o(i,j)是边缘上的max_pool_3x3,max_pool等。理论上从一个node到相邻的node可以有很多种operation,所以搜索最优网络结构也可以看成是选择每一个边上最佳的operation。
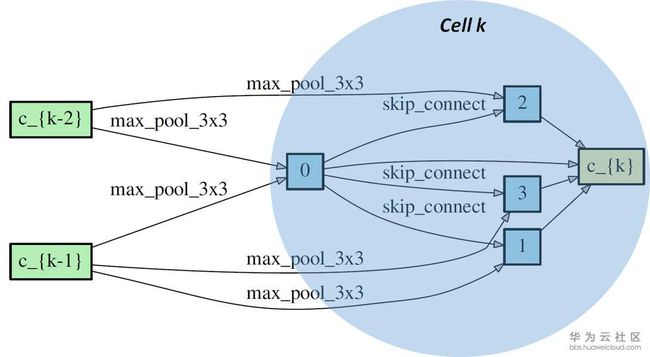
DARTS将每对node之间的每一个operation都赋予一个weight,最优解可以用softmax求得,也就是说有最大probability的path代表最优operation,这也是DARTS的核心部分。DARTS在搜索空间中定义了两种cell,reduction cell和normal cell。宏观网络结构是固定的,作者采用了简单的chained-structured,将reduction cell放在了网络结构的1/3和2/3处。所以说在搜索的过程中,cell内部不断更新而宏观结构没有变化。我们定义operation的参数为W,将cell中operation的weight记为Alpha。根据论文和source code,我们总结了DARTS的搜索流程如下图。

网络搜索的第一步是对模型结构,optimizer,loss进行初始化。文中定义了几种operation,代码中的定义在operation.OPS, 两种cell在代码中的定义是genotypes.PROMITIVES. 参数Alpha在代码中定义为arch_parameters()={alphas.normal, alphas.reduce}. 在搜索过程中,train data被分成两部分,train patch用来训练网络参数W而validation patch用来评估搜索到的网络结构。在代码中,搜索过程的核心部分在architect.step()。网络搜索的目标函数就是让validation在现有网络的loss最小,文章中公式(3)给出了objective:
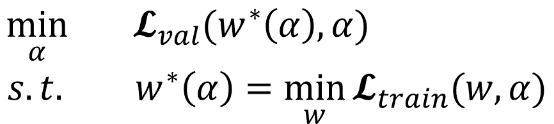
为了减少搜索时间,每一轮只用一个training patch去更新参数W计算train loss。在计算Alpha的时候涉及到二阶求导,稍微复杂一点,但是论文和代码都给了详细解释,这里不赘述,代码中architect._hession_vector_product是求二阶导的实现。在更新W和Alpha之后,最优operation通过softmax来计算。文中保留了top-k probability的operation。W和Alpha不断计算更新直到搜索过程结束。
文中进行了大量实验,我们这里只介绍一下在CIFAR-10数据上面进行的图像分类任务。作者将DARTS与传统人工设计的网络DenseNet,和几个其他常见的NAS网络进行对比,如AmoeNet和ENet都是常被提及的。DARTS在准确度上优于其他所有算法,并且在搜索速度上明显比RL快很多。由于结构简单效果好,而且不需要大量GPU和搜索时间,DARTS已经被大量引用。
Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation
基于DARTS的结构,Google DeepLab团队提出了Auto-DeepLab并发表在2019年CVPR上。在tensorflow deeplab官网上公布了nas backbone并且给出了可以训练的模型结构,但是搜索过程并没有公开。于是我们训练了给出的nas网络结构,在没有任何pre-training的情况下与deeplab v3+进行对比。代码参考 https://github.com/tensorflow/models/tree/master/research/deeplab 。
在DARTS中,宏观网络结构是提前定义的,而在Auto-DeepLab中宏观网络结构也是搜索的一部分。继承自DeepLab v3+的encoder-decoder结构,Auto-DeepLab的目的是搜索Encoder代替现有的xception65,MobileNet等backbone,decoder采用ASPP。在搜索空间中定义了reduction cell,normal cell和一些operation。Reduction cell用来改变spatial resolution,使其变大两倍,或不变,或变小两倍。为了保证feature map的精度,Auto-DeepLab规定最多downsampling 32倍 (s=32)。下图定义了宏观网络结构(左)和cell内部的结构(右)。
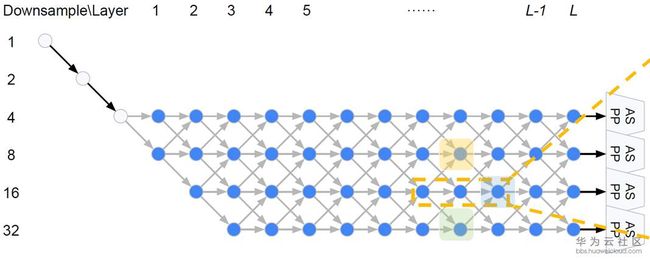

Auto-DeepLab定义了12个cell,而上图(左)中前面两个白色的node是固定的两层为了缩小spatial resolution。如图左灰色箭头所示,正式搜索之后,每一个cell的位置都有多种cell类型可以选择:可以来自于当前cell相同的spatial resolution的cell,也可以是比当前cell的spatial resolution大一倍或小一倍的cell。作者将这些空间路径(灰色箭头表示的路径)也赋予一个weight,记作Beta。如图右,每一个cell的输出都是由相邻spatial resolution的cell结合而成,而Beta的值可以理解成不同路径的probability。为了更直观,我们把图右的三个cell分别用蓝色,黄色和绿色标注,对应图左的三个cell。与DARTS类似,我们将operation的parameters记作W,将cell内部operation的权重记作Alpha。所以搜索最优网络结构,即迭代计算并更新W,Alpha和Beta。文中给出每一个cell的实际输出为:

从上面公式可以看出,W和{Alpha,Beta}要分别计算和更新。所有的weight都是非负数。Alpha的计算方式依然是ArgMax,而计算Beta用了经典的贪心算法Viterbi算法。下图给出的宏观网络结构是基于Cityscapes搜索到的结果,对应代码中的backbone是[0,0,0,1,2,1,2,2,3,3,2,1], 数字代表downsample倍数。在模型中,每一个cell中的node由两个路径组成,如图右。

文中用了三组开源数据PASCAL VOC 12, Cityscapes和ADE20k做了对比实验。具体实验参数设置和对比算法在论文中有详细说明,这里只对比和Deeplab v3+。Cityscapes训练数据尺寸是[769x769],而PASCAL VOC 12和ADE20k训练数据尺寸是[513x513]。一般来说,Auto-DeepLab和DeepLabv3+准确度相差无几,但是速度上要快2.33倍,并且Auto-DeepLab可以从零开始训练。

除了文中给出的实验结果以外,我们在PASCAL VOC 12数据上从零开始训练了Auto-DeepLab,用代码中给出的模型结构,并且与DeepLabv3+(xception65)进行结果对比。但是并不是所有结果都能复现,分析原因大概是这样:首先,上文中给出的模型结构是用Cityscapes数据集搜索得到,也许在PASCAL VOC 12上并不是最优解;其次没有用ImageNet做pre-training,训练环境也不同。我们在下面表格中对比了FLOPs, 参数数量, 在K80 GPU上面的fps和mIoU。

下图中直观对比了ground truth(第二列),deeplabv3+(第三列)和Auto-DeepLab-S(第四列)的分割结果。与上面的mIoU一致,DeepLabv3+的分割结果要比Auto-DeepLab更精准一些,尤其是在边缘。对于简单的图像案例,两者分割结果相差无几,但是在较难的情况下,Auto-DeepLab会有很大误差(在第三个案例中,Auto-DeepLab将女孩识别成狗)。

总结
本文简单介绍了NAS的发展现况和在语义分割中的应用,并且详细解读了两篇流行的work:DARTS和Auto-DeepLab。从整体实验结果来看,还不能看出NAS的方法比传统的模型有压倒性优势,尤其在准确度上。但是NAS给深度学习注入了新鲜的血液,为研究者提供了一种新的思路,并且还有很大的提升空间和待开发领域。也许人工设计网络结构将会被自动网络搜索取代。
翻译或有误差,请参考原文https://medium.com/@majingting2014/neural-architecture-search-on-semantic-segmentation-1801ee48d6c4
对这块比较关注的同学可以移步继续阅读《自动网络搜索(NAS)在语义分割上的应用(二)》
References
[1] Zoph, Barret, and Quoc V. Le. "Neural architecture search with reinforcement learning." The International Conference on Learning Representations (ICLR) (2017)
[2] Elsken, Thomas, Jan Hendrik Metzen, and Frank Hutter. "Neural Architecture Search: A Survey." Journal of Machine Learning Research 20.55 (2019): 1-21.
[3] Zoph, Barret, et al. "Learning transferable architectures for scalable image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR). 2018.
[4] Zhang, Yiheng, et al. "Customizable Architecture Search for Semantic Segmentation." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2019.
[5] Chen, Liang-Chieh, et al. "Searching for efficient multi-scale architectures for dense image prediction." Advances in Neural Information Processing Systems (NIPS). 2018.
[6] Liu, Chenxi, et al. "Auto-deeplab: Hierarchical neural architecture search for semantic image segmentation." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2019.
[7] Nekrasov, Vladimir, et al. "Fast neural architecture search of compact semantic segmentation models via auxiliary cells." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2019.
[8] Lin, Peiwen, et al. "Graph-guided Architecture Search for Real-time Semantic Segmentation." arXiv preprint arXiv:1909.06793 (2019).
[9] Liu, Hanxiao, Karen Simonyan, and Yiming Yang. "Darts: Differentiable architecture search." The International Conference on Learning Representations (ICLR) (2019).
