【摘要】本文将为大家带来使用Atlas 200 DK的原版YOLOv3(基于Darknet-53)实现的展示。
前言
YOLOv3可以算作是经典网络了,较好实现了速度和精度的Trade off,成为和目标检测的首选网络,堪称是史诗巨作级别(我是这么认为的)。YOLOv3是在YOLOv1和YOLOv2的基础上,改进而来,如果希望深入了解,建议看看前两个版本,这里附上网络上比较好的分析博文:
YOLOv1 https://blog.csdn.net/litt1e/article/details/88814417
YOLOv2 https://blog.csdn.net/litt1e/article/details/88852745
对于今天的主角YOLOv3,强烈建议看看作者的原版论文,像是一篇报告,篇幅很短,写的十分风趣幽默,是论文届一股清流啊。附上论文链接:
论文地址:https://pjreddie.com/media/files/papers/YOLOv3.pdf
论文:YOLOv3: An Incremental Improvement
环境要求:
Atlas 200 DK
配置好的虚拟机,可连接Atlas 200 DK
这里提供完整的工程,包括转化好的模型,只要你有Atlas 200 DK即可运行。
介绍
好了,下面该今天的主角登场了——YOLOv3,先看看结构图,来个直观的了解:
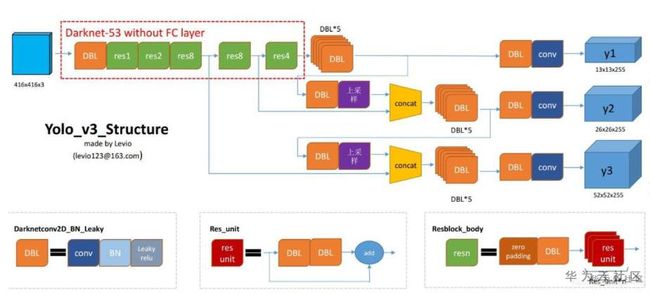
是的,没错,这张图是我在博客上看到的,附博客链接:https://blog.csdn.net/leviopku/article/details/82660381,这篇博客解析了YOLOv3,写的不错,大家可以看看。在博客中,作者总结了YOLOv3的特点,如下:
yolo_v3作为yolo系列目前最新的算法,对之前的算法既有保留又有改进。先分析一下yolo_v3上保留的东西:
1. 分而治之”,从yolo_v1开始,yolo算法就是通过划分单元格来做检测,只是划分的数量不一样。
2. 采用"leaky ReLU"作为激活函数。
3. 端到端进行训练。一个loss function搞定训练,只需关注输入端和输出端。
4. 从yolo_v2开始,yolo就用batch normalization作为正则化、加速收敛和避免过拟合的方法,把BN层和leaky relu层接到每一层卷积层之后。
5. 多尺度训练。在速度和准确率之间tradeoff。想速度快点,可以牺牲准确率;想准确率高点儿,可以牺牲一点速度。
YOLO系列的提升很大一部分决定于backbone网络的提升,从v2的darknet-19到v3的darknet-53。yolo_v3还提供替换backbone——tiny darknet。要想性能牛叉,backbone可以用Darknet-53,要想轻量高速,可以用tiny-darknet。
总之,YOLO就是天生“灵活”,所以特别适合作为工程算法。这里要说明的是,leaky ReLU在Ascend 310上适配不是很好,可能只有TensorFlow1.12版本可以用,大家注意,如果使用TensorFlow版本模型去转化为.om模型,建议使用TensorFlow 1.12版本,据说适配比较好哦。
整体流程
整体例程和PC端类似,分为数据输入,预处理,送入模型推理,推理结果解析四部分。这里是基于我以前发的另一个工程修改的,你可以在本工程看到原来工程的痕迹哦,附上原工程链接:https://bbs.huaweicloud.com/blogs/170452,在原工程上修改,这样可以提高效率,比如创建Graph等操作都直接就行了,建议大家也可以参考,在实现自己工程时,最好在官方例程或现有能运行代码上修改,这样比较快,也更容易成功。
1.模型获取和转换
先来看看模型转化,模型使用的是基于COCO数据集训练的TensorFlow版本的YOLOv3模型。
模型来自https://github.com/wizyoung/YOLOv3_TensorFlow/releases/ 里面的yolo_tf_weights.zip,可自行下载,不过不下载也没事,这里提供了完成的代码,只要你有Atlas 200 DK即可运行。下载后按照帖子转换完成,得到.pb模型。帖子链接:https://bbs.huaweicloud.com/forum/thread-45383-1-1.html
下面是模型转化,通过Netron可以看到模型输入节点为Placeholder 输入为1, 416,416,3。这表示模型输入为一张图片,图片为416*416大小,3通道,也就是我们常用的RGB格式。

这里我们输入的是视频,使用OpenCV读取的视频,得到视频帧,对每一视频帧进行逐帧处理,注意OpenCV得到的帧是BGR格式,需要转为RGB格式,而且视频帧大小不一定符合模型输入要求的416*416, 所以还要做resize。我在模型转化时,开启AIPP,完成BGR到RGB的色域转换,而resize使用OpenCV来完成。之后送入模型,得到推理结果,对推理结果解析,最终将结果写入图片保存。
主要代码
主代码 main.py
# -*- coding: utf-8 -*-
# !/usr/bin/python3
# Author: Tianyi_Li
# Last Date: 2020/5/29
# YOLOv3_COCO,基于COCO数据集训练的TensorFlow版本,检测80种类别的物体。
# 主函数部分
import sys
import re
import cv2
import yolo3_resnet18_inference
import time
import datetime
# Get Video
lenofUrl = len(sys.argv)
# The number of parameters is incorrect.
if lenofUrl <= 1:
print("[ERROR] Please input mp4/Rtsp URL")
sys.exit()
elif lenofUrl >= 3:
print("[ERROR] param input Error")
sys.exit()
URL = sys.argv[1]
# match Input parameter format
URL1 = re.match('rtsp://', URL)
URL2 = re.search('.mp4', URL)
# Determine if it is a mp4 video based on matching rules
if URL1 is None:
if URL2 is None:
print("[ERROR] should input correct URL")
sys.exit()
else:
mp4_url = True
else:
mp4_url = False
# Init Graph and Engine
yolo3_resnet18_app = yolo3_resnet18_inference.Yolo3_Resnet18Inference()
if yolo3_resnet18_app.graph is None:
sys.exit(1)
# Get Start time
run_starttime = datetime.datetime.now()
# Get Frame
cap = cv2.VideoCapture(URL)
ret, frame = cap.read()
print("视频是否打开成功:", ret)
# Get Video Information
frames_num = cap.get(7)
frame_width = cap.get(3)
frame_height = cap.get(4)
# According to the flag,Perform different processing methods
if mp4_url:
try:
while ret:
# Processing the detection results of a frame of pictures
strattime = time.time()
ret = yolo3_resnet18_inference.dowork(frame, yolo3_resnet18_app)
endtime = time.time()
print('Process this image cost time: ' + str((endtime - strattime) * 1000) + 'ms')
if ret is None:
sys.exit(1)
# Loop through local video files
ret, frame = cap.read()
# Run done, print input video information
run_endtime = datetime.datetime.now()
run_time = (run_endtime - run_starttime).seconds
print("输入视频的宽度:", frame_width)
print("输入视频的高度:", frame_height)
print("输入视频的总帧数:", frames_num)
print("程序运行总时间:" + str(run_time) + "s")
print('-------------------------end')
except Exception as e:
print("ERROR", e)
finally:
# Turn off the camera
cap.release()
else:
print("[ERROR] Run Failed, please check input video.")
return True推理代码
# -*- coding: utf-8 -*-
# !/usr/bin/python3
# YOLOv3_COCO,检测80种类别的物体
from ConstManager import *
import ModelManager
import hiai
from hiai.nn_tensor_lib import DataType
import numpy as np
import cv2
import utils
import datetime
'''
Yolo3_COCO模型, 输入H = 416, W = 416,模型的图像输入为RGB格式,这里使用OpenCV读取的图片,得到BGR格式的图像,在AIPP中完成BGR到RGB的色域转换和
image/255.0的归一化操作
bj_threshold 置信度阈值,取值范围为0~1。推理的时候,如果预测框的置信度小于该值,那么就会过滤掉, 默认为0.3
nms_threshold NMS阈值,取值范围为0~1。默认为0.4
'''
class Yolo3_Resnet18Inference(object):
def __init__(self):
# 由用户指定推理引擎的所在Graph的id号
self.graph_id = 1000
self.model_engine_id = 100
# 基于输入图片框坐标
self.boxList = []
# 置信度
self.confList = []
# 概率
self.scoresList = []
# 输入图片中行人部分
self.personList = []
# 实例化模型管理类
self.model = ModelManager.ModelManager()
self.width = 416
self.height = 416
# 描述推理模型以及初始化Graph
self.graph = None
self._getgraph()
def __del__(self):
self.graph.destroy()
def _getgraph(self):
# 描述推理模型
inferenceModel = hiai.AIModelDescription('Yolo3_Resnet18', yolo3_resnet18_model_path)
# 初始化Graph
self.graph = self.model.CreateGraph(inferenceModel, self.graph_id, self.model_engine_id)
if self.graph is None:
print("Init Graph failed")
'''
1.定义输入Tensor的格式
2.调用推理接口
3.对一帧推理的正确结果保存到self.resultList中
4.根据返回值True和False判断是否推理成功
'''
def Inference(self, input_image):
if isinstance(input_image, np.ndarray) is None:
return False
# Image PreProcess
resized_image = cv2.resize(input_image, (self.width, self.height))
inputImageTensor = hiai.NNTensor(resized_image)
nntensorList = hiai.NNTensorList(inputImageTensor)
# 调用推理接口
resultList = self.model.Inference(self.graph, nntensorList)
if resultList is not None:
bboxes = utils.get_result(resultList, self.width, self.height) # 获取检测结果
# print("bboxes:", bboxes)
# Yolov_resnet18 Inference
output_image = utils.draw_boxes(resized_image, bboxes) # 在图像上画框
output_image = cv2.resize(output_image, (input_image.shape[1], input_image.shape[0]))
img_name = datetime.datetime.now().strftime("%Y-%m-%d%H-%M-%S-%f")
cv2.imwrite('output_image/' + str(img_name) + '.jpg', output_image)
else:
print('no person in this frame.')
return False
return True
def dowork(src_img, yolo3_resnet18_app):
res = yolo3_resnet18_app.Inference(src_img)
if res is None:
print("[ERROR] Please Check yolo3_resnet18_app.Inference!")
return False
else:
# print("[ERROR] Run Failed, dowork function failed.")
pass
return True代码中加了一些注释,应该比较好理解,有机会再加更详细的注释吧。
执行过程
首先要下载完整代码,并提供了三段测试视频,供选择。代码下载链接:
链接:https://pan.baidu.com/s/1E86SFEYjmhaGoQVc6Y7gfg
提取码:ok0l
下载后,解压缩,可以得到:

之后将包含上述文件的文件夹拷贝到Atlas 200 DK上,在存放目录下执行命令
1
scp -r YOLOv3_COCO [email protected]:/home/HwHiAiUser注意,我是在YOLOv3_COCO文件下目录下使用的命令,所以直接用文件夹名字就行,否则需要指定路径,使用的是USB连接开发板,如果用网线连接,IP可能不同,更多拷贝文件的方法,请参考博文每天进步一点点——使用scp命令在Atlas 200 DK和虚拟机之间传输文件(文件夹)
链接为 https://bbs.huaweicloud.com/blogs/168928
这里模型有点大,传输可能需要点时间,传输完成结果为
之后登陆开发板,执行命令即可。因为前面,我拷贝到了开发板的/home/HwHiAiUser目录下,所以直接登陆就能看到了,直接执行命令进入文件夹即可
1
cd YOLOv3_COCO下面执行程序
1
python3 main.py input_video/person.mp4在input_video文件夹下放了三个用于测试的视频,分辨率分别是1920*1080 、1280*720和640*480,这里使用的是person.mp4,分辨率1920*1080

等待程序执行,最后得到
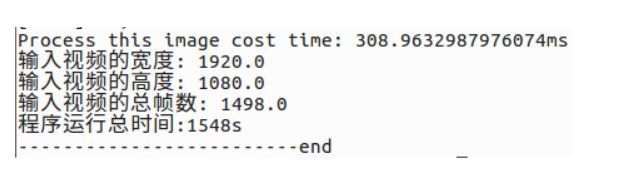
表示程序运行完成,处理一帧大概需要300ms,比较慢,分析可知,主要是读取视频和后处理较慢,推理速度挺快的,后期可能要对后处理做优化,比如使用算子完成后处理,或者硬件解码视频,使用OpenCV读取视频应该不较慢,而且图像质量感觉一般。
最后,将输出的结果图片拷贝到虚拟机就可以查看了,我的命令为
1
scp -r [email protected]:/home/HwHiAiUser/YOLOv3_COCO/output_image /home/ascend/tmp我拷贝到了虚拟机的tmp文件夹下,具体拷贝文件到虚拟机细节可参考博文https://bbs.huaweicloud.com/blogs/168928
总的来说,Atlas 200 DK挺强的,运行118M的YOLOv3模型毕竟很耗资源。在1920*1080 、1280*720和640*480分辨率的视频下,速度还可以,如图
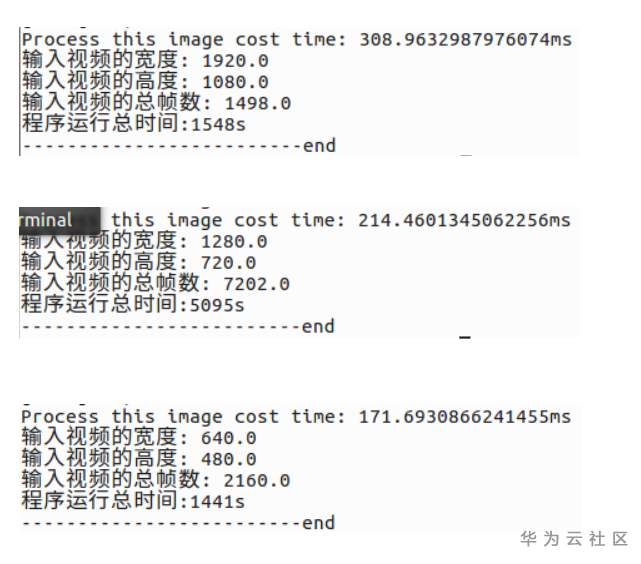
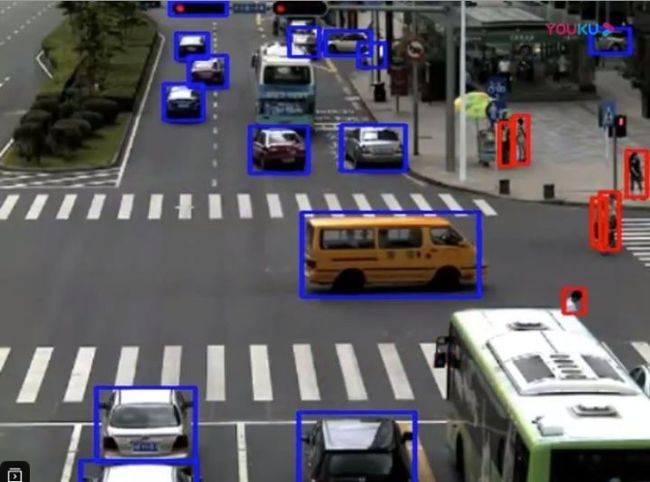
最终效果展示
这里是做了人(红色),自行车(绿色)和car(蓝色)类别的绘制矩形框。可自行修改代码,绘制COCO数据集80类矩形框,不过速度会慢哈。