【直击DTCC】Intel程浩:Spark SQL优化与硬件选型
【IT168 资讯】5月12日,我们迎来了2017第八届中国数据库技术大会(DTCC2017)第二天。本届大会以“数据驱动 价值发现”为主题,汇集来自互联网、电子商务、金融、电信、政府、行业协会等20多个领域的120多位技术专家,共同探讨Oracle、MySQL、NoSQL、云端数据库、智能数据平台、区块链、数据可视化、深度学习等领域的前瞻性热点话题与技术。
大会共设定2大主场和21个技术专场,吸引了5000多名IT人士参会,为数据库人群、大数据从业人员、广大互联网人士及行业相关人士提供最具价值的交流平台。今天下午,我们来到了“数据库性能优化”专场,Intel亚太研发中心Spark团队研发经理程浩进行了题为《Spark SQL优化与硬件选型》主题演讲。

▲Intel亚太研发中心Spark团队研发经理,程浩
嘉宾介绍:程浩,Intel亚太研发中心Spark团队研发经理,Apache Spark活跃开发者,致力于Spark框架在Intel平台架构上的性能分析与优化。
在Spark大数据应用中,如何让硬件得到更好的效能发挥和更高的性价比一直是我们关心的话题。
如何收集硬件利用率和Spark应用程序性能瓶颈分析;当新硬件采购时,如何验证怎样的硬件配置对Spark应用可以有最佳的效能或者最好的性价比。
在这个主题中,程浩为我们展示了不同特性的典型Spark应用的性能分析和调优手段,揭示如何释放硬件资源,监控硬件性能发挥,并在此基础上,测试不同硬件配置诸如内存、网络、磁盘、CPU选型,对于Spark大数据应用程序性能的影响,指导运维人员决策购买或者升级新的硬件零部件时候,可能可以采取的测试验证方法。
此外,程浩还比较了Spark应用程序在物理机、虚拟机以及容器技术下的性能分析和对比,提供大数据应用部署在不同基础设施架构下的硬件性价比参考。
Spark概要简介
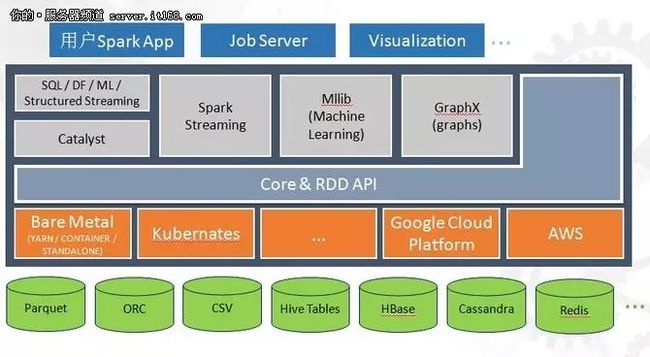
为什么选Spark?而不是MR?程浩总结了以下几条原因:
简单易用:同一个软件栈搞定一切(Streaming, SQL, GraphX, Machine Learning, BigDL);多种语言支持(SQL, Java, Scala, Python, R);Declarative (DataSet / DataFrames / RDD) API VS. Imperative API;活跃的数据源连接器开源组件(Hbase, Cassandra, Redis, ElasticSearch, MongoDB)。
更快的处理引擎:DAG Based任务调度机制;缓存API与内存计算;开放式的Catalyst执行计划优化器&Tungsten系列优化执行加速。
Spark拥有良好的生态圈
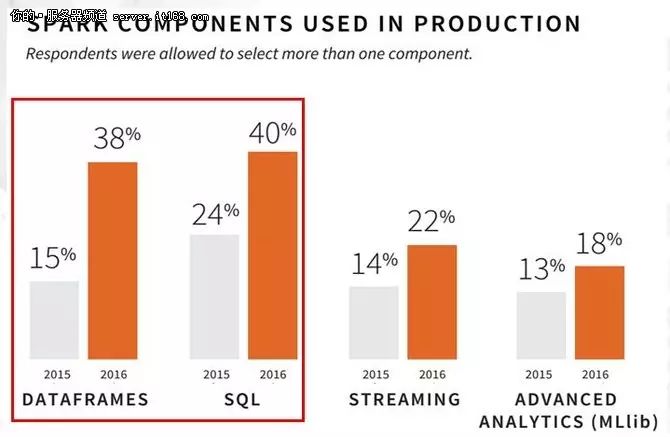
Spark SQL性能基准测试
实验环境和测试集如下:

Performance Analysis Tool(PAT) 适用于与在分布式环境下收集系统资源信息,包括CPU、磁盘、网络、内存等,并以图形化的形式展现出来。

性能比较分析
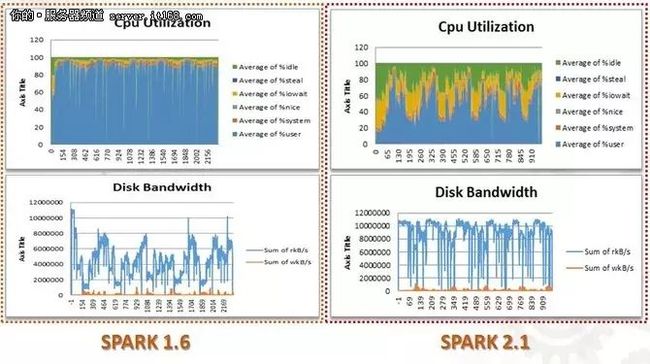
#SPARK 1.6 VS. SPARK 2.1 (吞吐量测试)
#升级磁盘到Intel PCI-E SSD P3600 (2650v3)
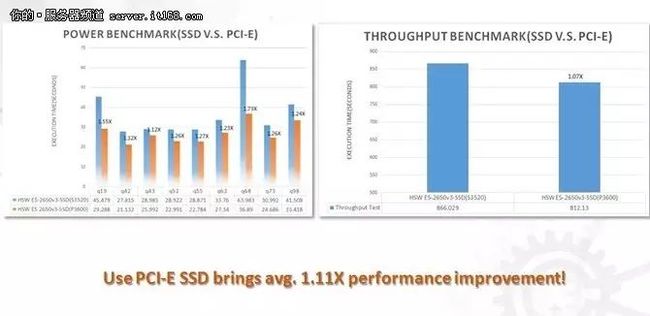
完整性能分析对比
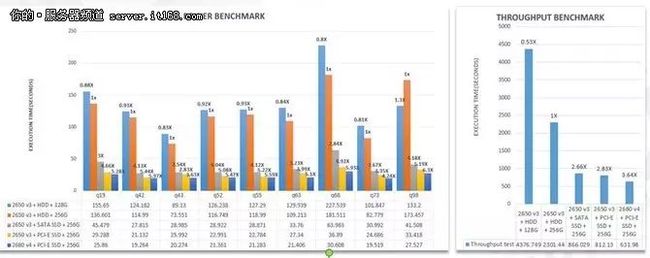
总结:128GB内存可能会极大制约性能;SATA SSD (Intel S3520)相对HDD性能提升非常明显;PCI-E SSD (Intel P3600)相对HDD性能也会有明显提升,但是只有配合更高端的CPU(E5 2680v4)才能充分发挥其优势。
推荐硬件选型
SPARK SQL推荐硬件配置

下一步?
最后,程浩总结了影响Spark(SQL)性能的主要因素有网络、磁盘、内存、CPU、调度本地性、集群规模、数据均衡。可以优化的方向思考:更高的数据压缩比;HDFS缓存或者层次化数据存储;更加合理的任务调度(利用数据本地性);避免数据倾斜;自适应的任务数调节。
品读之后,
愿享同感。

by.数据库技术大会
