文章内容概览
内部网关路由协议之RIP协议
距离矢量(DV)算法
在介绍RIP协议之前,先了解一下DV算法,因为该协议是通过DV算法进行实现的
该算法是运行在图中的
- 每一个节点使用两个向量Di和Si
- Di描述的是当前节点到别的节点的距离
- Si描述的是当前节点到别的节点的下一个节点
对于该算法,它是如何运行的?
- 每一个节点和相邻的节点交换向量Di和Si的信息
- 每一个节点根据交换的信息,更新自己的节点信息
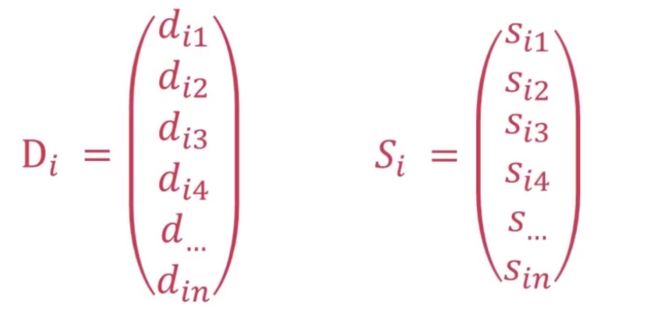
- Di1表示从节点i到节点1的距离
- Si1表示从节点i到节点1的下一个节点
- n表示节点的数量
对于DV算法,他其实就是计算D的距离的最小值。比如Dij的最小值就等于:min(Dix+Dxj)。通过一个例子来理解这个DV算法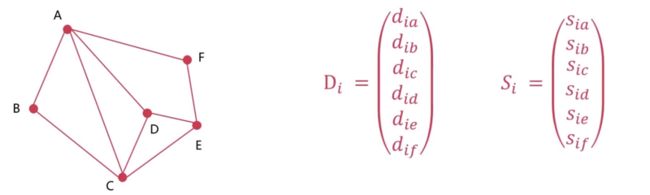
图中有A、B、C、D、E、F这六个顶点和若干条边,对于这六个节点,就有右边这样的Di和Si的距离矢量信息。对于Di,它有六个元素,分别是Dia、Dib...到Dif,他表示的是,i这个节点到A、B、C、D、E、F这六个节点的距离。对于Si,它也有六个元素,分别是Sia、Sib...到Sif,他表示的是,i这个节点到A、B、C、D、E、F这六个节点的下一个节点是什么
下边会以A这个节点为例来展示DV算法是如何运行的,也就是求Da和Sa这两个向量。假设A的距离矢量信息(Da)如下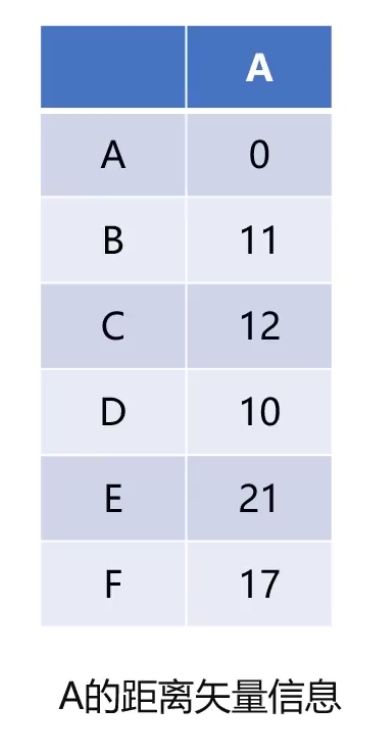
它表示的是A到其它的每个节点的距离分别为右侧列的值。在上边介绍DV算法时有提到,该算法会与相邻的节点交换Da和Sa的信息。假设A收到了来自B、C、D、F这四个相邻节点的信息,并且在接收到距离矢量信息的时候,知道了A到各个相邻节点的直线距离是多少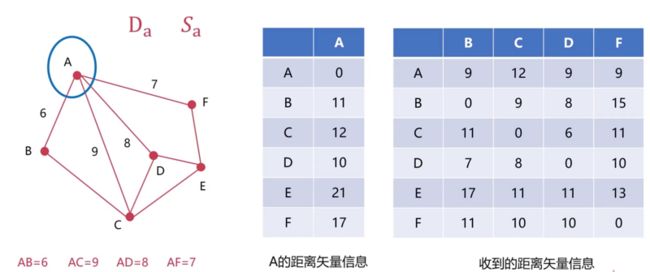
为了更加方便的了解DV的过程,将A的距离矢量信息和A到其它四个相邻节点的矢量信息合在一起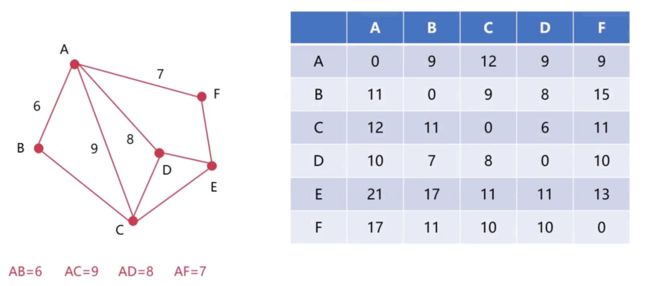
图中的每一列表示的是某一个节点到达A、B、C、D、E、F节点的距离是什么
可能大家对表中的数据有疑问,为什么A到B的距离是11,而B到A的距离却是9。这个是因为里边的距离矢量信息并不是最新的。比如说,A到B的距离可能是通过A->C->B所得到的,因此这里A到B的距离可能是11。而B到A的距离可能是通过B->C->D->A所得到的,所以这里A到B的距离矢量信息可以和B到A的距离矢量信息不一样
列出A的S向量,默认初始化为空,S向量表示的是A到其它几个节点的下一个节点是什么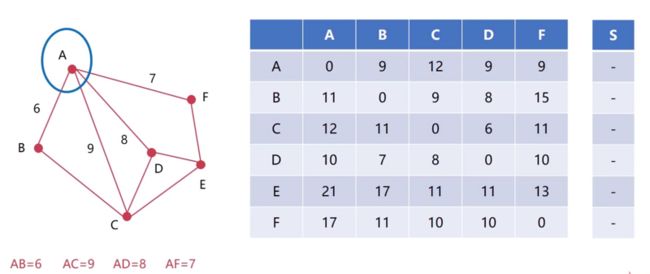
假设此时A在和B这个节点交换信息,A就得到了B这个节点的信息,也就是得到了B到每一个节点的距离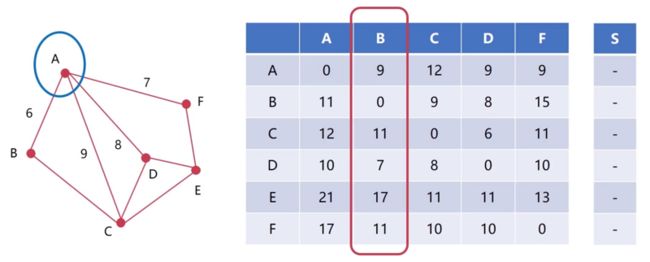
A得到这些信息之后,首先会进行运算。因为A和B是直接进行通信的,所以A知道A到B的距离是什么。然后会通过从B那里得到的B到其它节点的距离,来计算A到其它节点的距离
A->B = 6
A->B->C = 6+11 = 17
A->B->D = 6+7 = 13
A->B->E = 6+17 = 23
A->B->F = 6+11 = 17以上就是A得到B的数据之后进行的运算,然后他会把得到的这些数据和自己的距离矢量进行比较,如果比自己到其它节点的距离更小,那么它就会把它填充到自己的距离矢量中。所以拿到B的数据,经过计算之后,发现A到B的距离6,比自己原来的11小,所以把自己原来的11,替换成6;然后发现自己原来A到F的距离为17,和计算之后A到F的距离17相等,那么A也会进行替换。替换为完之后,A就会把相应的下一个节点设为B。以上就是A获取到B的信息之后的整个过程,如下图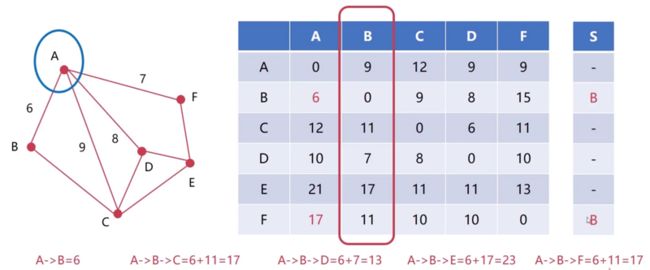
接下来A又接收到了节点C的信息,这其中就包括C到A、B、C、D、E、F的距离。A接收到C的信息之后,也会进行和之前一样的运算
A->B->C = 9+9 = 18
A->C = 9
A->C->D = 9+8 =17
A->C->E = 9+11 = 20
A->C->F = 9+10 = 19经过计算之后,也会和自己现有的距离矢量进行比较。比如A->C的距离为9,要比A之前到C的距离12小,所以就会用9把原来的12替换掉,并且对应的S会填充为C,后边的同理,如图:
A和D、F交换信息的过程也是和上边一模一样的。当A和每一个相邻的节点交换完信息之后,得到如下的结果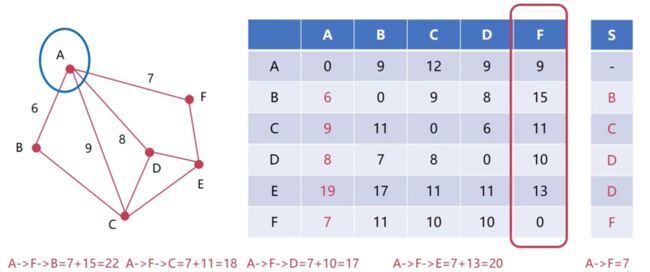
以上就是DV算法的整个过程,回看前边介绍的DV算法,再来理解它的定义会好明白很多
- 每一个节点使用两个向量Di和Si
- Di描述的是当前节点到别的节点的距离
- Si描述的是当前节点到别的节点的下一个节点
- 每一个节点和相邻的节点交换向量Di和Si的信息
- 每一个节点根据交换的信息,更新自己的节点信息
RIP协议的过程
- RIP(Routing Information ProtoCol)协议
- RIP协议是使用DV算法的一种路由协议
- RIP协议把网络的跳数(hop)作为DV算法的距离(其实就是跳数越多,距离就越长)
- RIP协议每隔30s交换一次路由信息(这里的路由信息就包含Di和Si)
- RIP协议认为跳数>15的路由则为不可达路由
使用RIP协议的路由器
- 路由器会初始化路由信息(两个向量Di和Si)
- 根据相邻路由器X发过来的信息,对信息的内容进行修改(下一跳地址设为X,所有距离加1。意思就是,通过X,它可以到达X所发过来信息的每一个节点,只需要将距离加1就可以了)
- 修改了之后,首先检索本地路由,将信息中新的路由插入到路由表里边(因为有些目的地,本地路由表里边可能是没有的)
- 检索本地路由,对于下一跳为X的,更新为修改后的信息
- 检索本地路由,对比相同目的地的距离,如果新信息的距离更小,则更新本地路由表
- 如果3分钟没有收到相邻的路由信息,则把相邻的路由设置为不可达(也就是设置为16跳)
通过例子来理解上边的描述。假设路由中初始化的信息如下最左边部分: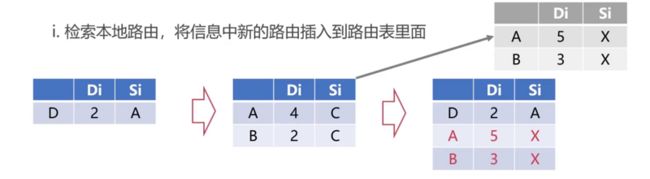
第一步:检索本地路由,将信息中新的路由插入到路由表里边
初始化路由表中的信息,表示路由到D的距离为2,并且其下一跳地址为A。假设此时收到来自路由器X发来的信息。信息有到达A的距离4,下一跳地址为C。到达B的距离为2,下一跳地址为C。收到这些信息之后,路由器会对自身信息进行修改,将所有的距离都加一,并且将下一跳地址都设为X。接下来就会检索本地的路由,发现A、B都是原来路由里边没有的,所以会把A、B的信息插入到路由表中。就得到了更新之后的路由表
第二步:检索本地路由,对于下一跳为X的,更新为修改后的信息
假设初始化的路由信息如下最左边部分: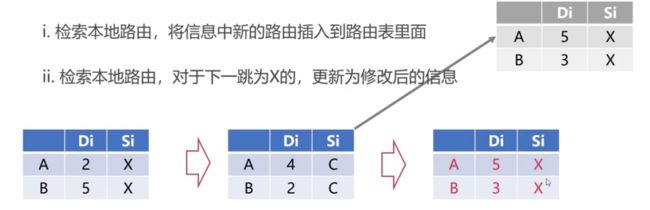
当初始路由器,收到中间的路由信息,该路由信息首先会进行修改,修改之后,就会根据接收到的路由信息对自身进行修改,因为这是最新的信息,所以会把原来的覆盖掉
第三步:检索本地路由,对比相同目的地的距离,如果新信息的距离更小,则更新本地路由表
这一步其实就是前边介绍的DV算法过程,当初始路由收到另一个路由信息之后,另一个路由的信息先进行更新,然后和初始路由进行对比,如果新信息的距离更小,则更新本地路由表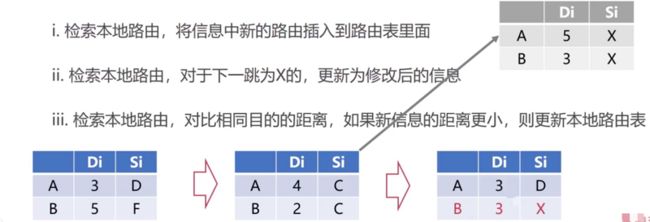
以上便是RIP协议的完整过程
RIP协议的缺点
通过一个例子来了解一下RIP协议的缺点。假设有A、B、C三个节点,并且他们是线性连接的。B、C到达A的距离分别是1和2,B是直接到达A,C是通过B到达A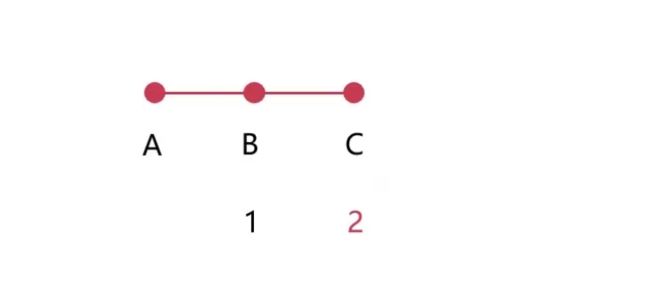
假设在某一个时刻,路由器A宕掉了,即A不可达。此时,B发现A不可达之后,就会询问C,询问C之后发现,通过C可以到达A,因此把下一跳设置为C,并且距离加一(也就是3)。C在某一个时刻也发现A不可达了,那么C也会询问B,发现B通过3跳之后可以到达A,所以它也会更新自己的路由信息,将到达A的距离设为4,并且下一跳设置为B,此时就会死循环下去,一直到距离为16(上边有介绍到,最多16跳,会认为目标不可达),才发现是不可达的
所以RIP协议最致命的缺点是:故障信息传递慢
RIP为什么会有这个特点?
- 随便相信“隔壁老王”(不管是B还是C,如果说B得到了C的路由信息,它将会无条件的相信C。同样,如果是C,他也会无条件相信B,因此就会导致循环,直到跳数为16,才发现不可达)
- “自己不思考”、“视野不够”(对于RIP协议,每一个路由器只看到相邻路由的信息,看不到更远的信息)
因为网络中经常出现故障,如果每一次故障,都需要这么多跳才能发现的话,会导致整个网络非常不可控,这就是RIP协议致命的缺点
在快速变化的技术中寻找不变,才是一个技术人的核心竞争力。知行合一,理论结合实践