Spark Streaming使用Kafka作为数据源
官网:Spark Streaming + Kafka Integration Guide
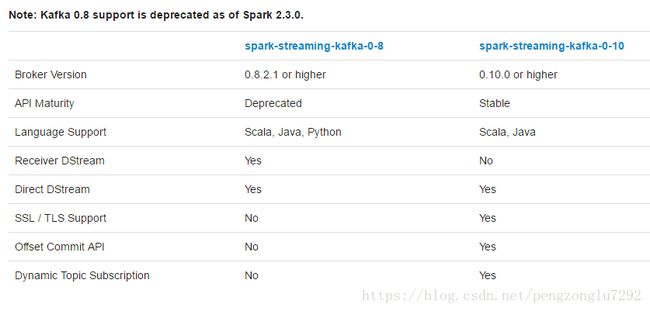
由于kafka在0.8和1.0之间引入了新版本的Consumer API,所以这儿有两个独立的集成方案。0.8版本的集成方案可以兼容0.9或1.0的kafka,而1.0版本的集成方案则不可以兼容1.0以下版本的kafka。
---------------------------------------------------------------------------------------------------------------
我们以下以spark-streaming-kafka-0-8作为演示。(spark-streaming-kafka-0-10可以参考)
--------------------------------------------------------------------------------------------------------------
1、搭建kafka环境:见本人博客 kafak介绍及部署。
2、将kafka与spark做集成,有两种方式,以下分别作介绍。
-----------------------------------------------------------------------------------------------------------------
一、基于Receiver的方法(Receiver-based Approach)
使用一个Receiver来接收数据,这个Receiver实现了kafka的高级别Consumer API,Receiver从Kafka这儿接收数据并储存在Spark的Executor中,作业运行后由Spark Streaming来处理数据。但是,在默认的配置下当任务失败时这种方式会丢失数据(可参考Receiver Reliablitily),为了保证数据的零丢失,你可以在Spark Streaming中添加Write Ahead Logs(在spark1.2引入)。这可以同步地将所有接收到的kafka数据保存在分布式文件系统的Write Ahead Logs中。接下来展示如何使用这种方法。
注意点:
A。kafka的topic中的分区与RDD中的分区没有关系。如果你增大KafkaUtils.createStream()的第四个参数的值,只是增大了Receiver的Topic使用的线程数,并没有增加Spark处理数据的并行度。
B。可以用不同的Group和Topic创建多个kafka input DStream,以便使用多个Receiver并行接收数据。
C。如果你启用了分布式文件系统的Write Ahead Logs机制,接收到的数据就以多副本的方式存在log中。则Input DStream则可以采用StorageLevel.MEMORY_AND_DISK_SER方式(that is, use KafkaUtils.createStream(..., StorageLevel.MEMORY_AND_DISK_SER))。
1、连接
添加依赖
2、编程
import org.apache.spark.streaming.kafka._
val kafkaStream = KafkaUtils.createStream(streamingContext,
[ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume])3、具体代码
package com.ruozedata.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object KafkaWordCountApp {
def main(args: Array[String]) {
if(args.length != 4) {
System.err.println("Usage: KafkaWordCountApp
System.exit(1)
}
val Array(zkQuorum,groupId, topics, numThreads) = args
val sparkConf = new SparkConf()
.setAppName("SocketWordCountApp")
.setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(10))
val topicMap = topics.split(",").map((_,numThreads.toInt)).toMap
val messages = KafkaUtils.createStream(ssc, zkQuorum, groupId, topicMap)
messages.map(_._2) // 是我们的value
.flatMap(_.split(",")).map((_,1))
.reduceByKey(_+_)
.print()
ssc.start()
ssc.awaitTermination()
}
}
4、传参
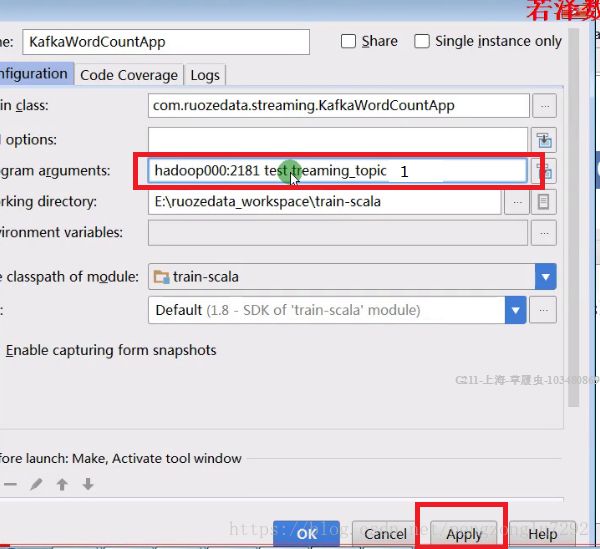
5、此时运行程序,在zk的生产者中输入数据回车,数据能够打印出来
##若要使用Spark-submit提交可参考Spark Streaming使用Flume作为数据源。
-------------------------------------------------------------------------------------------------------------------------------
二、没有Receiver的直接方式(Direct Approach (No Receivers)
这种方式在spark1.3版本引入,这种方式会周期性地查询kafka的分区和topic的offset,这样可以定义每个批次中要处理数据的offset范围。当作业提交运行时,kafka 的Consumer API会从kafka读取定义的offset范围(和从File System读取数据一样)。
这种方式比起基于Receiver有以下的优点:
A。简化了并行度:这种方式不需要你创建多个Input DStream,然后再执行union操作。因为directStream这个方法,Spark Streaming将会创建和Kafka分区数一样多的分区数,使得Spark Streaming可以并行地从kafka读取数据。这种kafka 和RDD之间一对一的映射关系,便于理解和调优。
##若要增加Spark Streaming读取kakfa数据的并行度,调整kafka的分区数即可。调优中十分重要的一个点。
B。高效:在第一种方式中若要实现数据的零丢失必须引入副本性质的Write Ahead Logs,这是十分低效的。第二种方式的话因为没有Receiver,所以也就不用引入Write Ahead Logs机制。只要你设置了kafka的log.retention.hours参数,你就可以从kafka中恢复数据。
C。精准一次的消费语义:第一种方式是使用kafka高级别API进行消费,然后将offset保存在zookeeper上,这种方式结合Write Ahead Logs在至少一次地消费语义(数据被消费后未来得及将offset写入zk,driver重启后需要再次去Write Ahead Logs中消费)下是能够保证数据的零丢失的,但在任务失败的情况下部分数据可能被消费两次。第二种方式的offset并没有使用zk来存储,而是由Spark Streaming的checkpoint 来跟踪,这种方式就算任务失败也只会被消费一次。
缺点:由于offset并不是保存在zk上,当使用基于zk的kafka监控工具时,任务情况无法展示在UI上。但是可以在每一个批次后访问offset并更新zk解决这个问题。
1、连接
添加依赖
2、编程
import org.apache.spark.streaming.kafka._
val directKafkaStream = KafkaUtils.createDirectStream[
[key class], [value class], [key decoder class], [value decoder class] ](
streamingContext, [map of Kafka parameters], [set of topics to consume])3、具体代码
package com.ruozedata.streaming
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object DirectKafkaWordCountApp {
def main(args: Array[String]) {
if(args.length != 2) {
System.err.println("Usage: DirectKafkaWordCountApp
System.exit(1)
}
val Array(topics, brokers) = args
val sparkConf = new SparkConf()
.setAppName("DirectKafkaWordCountApp")
.setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(10))
val topicSet = topics.split(",").toSet
val kafkaParams = Map[String, String]("metadata.broker.list"-> brokers)
val messages =KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](
ssc,
kafkaParams,
topicSet
)
messages.map(_._2) // 是我们的value
.flatMap(_.split(",")).map((_,1))
.reduceByKey(_+_)
.print
ssc.start()
ssc.awaitTermination()
}
}
4、传参
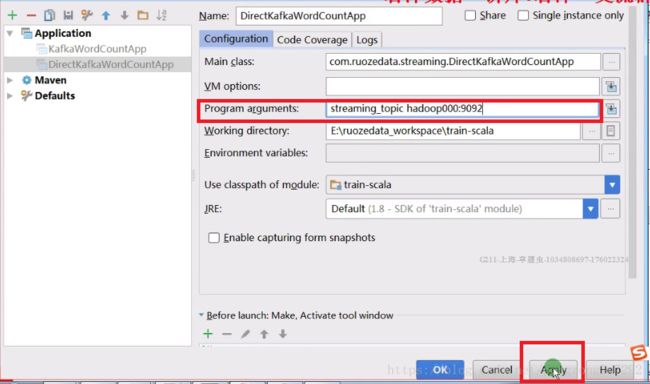
5、此时运行程序,在zk的生产者中输入数据回车,数据能够打印出来
##若要使用Spark-submit提交可参考Spark Streaming使用Flume作为数据源。
-----------------------------------------------------------------------------------------------------------------------------
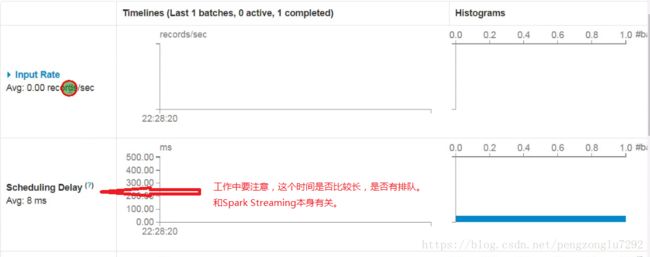
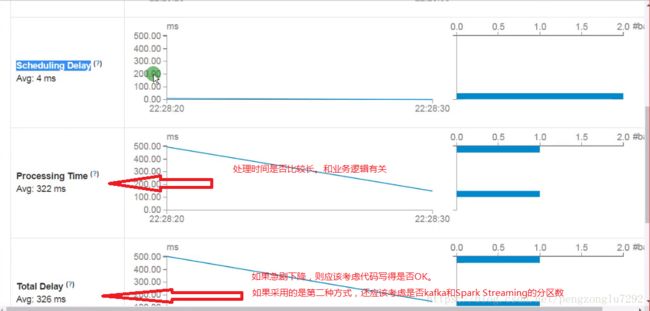
三、监控(Monitoring Applications)
UI地址:ip:4040/streaming
四、优化
1、减少批处理时间(Reducing the Batch Processing Times)
a.接受数据的并行度(Level of Parallelism in Data Receiving)
b.处理数据的并行度(Level of Parallelism in Data Processing)
c.数据序列化(Data Serialization)
d.任务开销(Task Launching Overheads)
2、设置合理的批处理时间(Setting the Right Batch Interval)
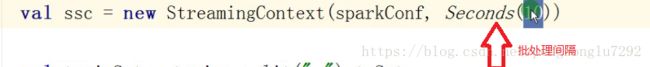
3、内存调优(Memory Tuning)
注意点:
A DStream is associated with a single receiver. For attaining read parallelism multiple receivers i.e. multiple DStreams need to be created. A receiver is run within an executor. It occupies one core. Ensure that there are enough cores for processing after receiver slots are booked i.e.
spark.cores.maxshould take the receiver slots into account. The receivers are allocated to executors in a round robin fashion.When data is received from a stream source, receiver creates blocks of data. A new block of data is generated every blockInterval milliseconds. N blocks of data are created during the batchInterval where N = batchInterval/blockInterval. These blocks are distributed by the BlockManager of the current executor to the block managers of other executors. After that, the Network Input Tracker running on the driver is informed about the block locations for further processing.
An RDD is created on the driver for the blocks created during the batchInterval. The blocks generated during the batchInterval are partitions of the RDD. Each partition is a task in spark. blockInterval== batchinterval would mean that a single partition is created and probably it is processed locally.
The map tasks on the blocks are processed in the executors (one that received the block, and another where the block was replicated) that has the blocks irrespective of block interval, unless non-local scheduling kicks in. Having bigger blockinterval means bigger blocks. A high value of
spark.locality.waitincreases the chance of processing a block on the local node. A balance needs to be found out between these two parameters to ensure that the bigger blocks are processed locally.Instead of relying on batchInterval and blockInterval, you can define the number of partitions by calling
inputDstream.repartition(n). This reshuffles the data in RDD randomly to create n number of partitions. Yes, for greater parallelism. Though comes at the cost of a shuffle. An RDD’s processing is scheduled by driver’s jobscheduler as a job. At a given point of time only one job is active. So, if one job is executing the other jobs are queued.If you have two dstreams there will be two RDDs formed and there will be two jobs created which will be scheduled one after the another. To avoid this, you can union two dstreams. This will ensure that a single unionRDD is formed for the two RDDs of the dstreams. This unionRDD is then considered as a single job. However the partitioning of the RDDs is not impacted.
If the batch processing time is more than batchinterval then obviously the receiver’s memory will start filling up and will end up in throwing exceptions (most probably BlockNotFoundException). Currently there is no way to pause the receiver. Using SparkConf configuration
spark.streaming.receiver.maxRate, rate of receiver can be limited.