阿里DataX介绍以及使用记录
目录
前言
一、阿里云开源离线同步工具DataX3.0介绍
二、DataX架构及原理
三、DataX程序流程介绍
四、DataX 如何使用
五、DataX Java使用
六、DataX部分核心源码解析
前言
最近接到需求是,需要一个用来解决异源数据库之间数据全量同步(部分支持实时同步)的数据交换工具。而阿里的开源的DataX 刚好满足需求,因此我们使用以DataX为基础,开发了一个满足异源数据库同步的数据交换工具。以下是一些心得体会,与诸君共勉。一、二、三节内容主要参考github introduction.md文档,详情内容,可以到github 去浏览。
一、阿里云开源离线同步工具DataX3.0介绍
DataX github地址 https://github.com/alibaba/DataX
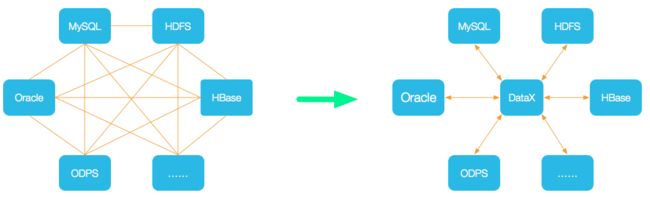
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库MySQL、Oracle、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。目前DataX支持数十种各类数据存储、计算系统,每天为阿里集团传输数据高达数十T。
-
设计理念
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。(这里我解释一下左边的网状结构是什么意思,譬如我们要做一个从MySql到Oracle的同步工具,我们需要写一个mysql-oracle,这时,如果我们需要MySql到SqlServer的同步工具,我们又需要写一个mysql-sqlserver,以此类推,会构成一个复杂网状结构。而DataX的理念就是,所有的异源数据库只需将数据从元数据同步到DataX,再由DataX同步到目的数据库,以此架构即构成右边星形数据链路。)
-
当前使用现状
DataX在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务,并已持续稳定运行了6年之久。目前每天完成同步8w多道作业,每日传输数据量超过300TB。
DataX解决的问题
实现跨平台的、跨数据库、不同系统之间的数据同步及交互。
二、DataX架构及原理
框架设计

DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
- Reader:Reader�为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
DataX目前支持数据如下:
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
|---|---|---|---|---|
| RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
| Oracle | √ | √ | 读 、写 | |
| SQLServer | √ | √ | 读 、写 | |
| PostgreSQL | √ | √ | 读 、写 | |
| DRDS | √ | √ | 读 、写 | |
| 达梦 | √ | √ | 读 、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读 、写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读 、写 |
| ADS | √ | 写 | ||
| OSS | √ | √ | 读 、写 | |
| OCS | √ | √ | 读 、写 | |
| NoSQL数据存储 | OTS | √ | √ | 读 、写 |
| Hbase0.94 | √ | √ | 读 、写 | |
| Hbase1.1 | √ | √ | 读 、写 | |
| MongoDB | √ | √ | 读 、写 | |
| Hive | √ | √ | 读 、写 | |
| 无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
| FTP | √ | √ | 读 、写 | |
| HDFS | √ | √ | 读 、写 | |
| Elasticsearch | √ | 写 |
核心架构
DataX 3.0 开源版本支持单机多线程模式完成同步作业运行,本小节按一个DataX作业生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系。

核心模块介绍:
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
DataX调度流程:
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
- DataXJob根据分库分表切分成了100个Task。
- 根据20个并发,DataX计算共需要分配4个TaskGroup。
- 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
技术原理
虽然上述架构和框架设计不是能很快理解,但是其最底层的技术原理,究其本质,所谓 数据同步无非是从源数据库查出数据,然后再将数据插入到目的数据库而已。框架也就是对这一基础动作进行封装,便于用户使用。
如此说来,底层的技术原理并不复杂,涉及到的最基本的技术就是JDBC连接数据库,通过Reader插件从源数据库select查出数据然后通过Writer插件insert插入到目的数据库。
底层说来简单,但是关于实际的处理却相对复杂,例如如何拼接sql,如何解决异源数据库的连接,同步,如何进行多通道传输数据,何时查询数据,何时插入数据,查与插之间如何调度等等,依赖于DataX巧妙的插件(Plugin)模式以及星形链路架构,得以实现。
三、DataX程序流程介绍
框架介绍时已经提及到了,DataX采用的时Framework + Plugin 模式,
- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
三者职责介绍完毕,程序流程就是,
1.Framework 读取配置文件(配置文件包含插件信息,用于初始化插件;数据源信息,用于JDBC连接数据库等内容)
配置文件内容如下所示:可粗略看看了解大概内容 (填写配置文件是我们自己主要需要做的事,其余的DataX已经帮我们做好)
{
"job": {
"setting": {
"speed": {
//设置传输速度 byte/s 尽量逼近这个速度但是不高于它.
// channel 表示通道数量,byte表示通道速度,如果单通道速度1MB,配置byte为1048576表示一个channel
"byte": 1048576
},
//出错限制
"errorLimit": {
//先选择record
"record": 0,
//百分比 1表示100%
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "oraclereader",
"parameter": {
// 数据库连接用户名
"username": "root",
// 数据库连接密码
"password": "root",
"column": [
"id","name"
],
//切分主键
"splitPk": "db_id",
"connection": [
{
"table": [
"table"
],
"jdbcUrl": [
"jdbc:oracle:thin:@[HOST_NAME]:PORT:[DATABASE_NAME]"
]
}
]
}
},
"writer": {
//writer类型
"name": "streamwriter",
// 是否打印内容
"parameter": {
"print": true
}
}
}
]
}
}
2.配置文件读取完毕后,Framework完善配置,确定通道数(单进程多线程传输数据)等
3.Framework 初始化Reader Writer插件
4.Framework 调用插件的切分通道split方法,进行通道切分
5.切分完毕,Framework 开启同步task,通过启动Reader 的内部类 Task 的 startRead方法,开始读取数据,然后存在Framework队列中
6.Framework 通过调用Writer的 内部类 Task 的startWriter方法,开始写出数据
7.同步结束,任务终止。Framework调用插件的destroy方法,结束线程。
四、DataX 如何使用
详情参考DataX Quick Start https://github.com/alibaba/DataX/blob/master/userGuid.md
五、DataX Java使用
欲了解本节需先对此链接 https://github.com/alibaba/DataX/blob/master/userGuid.md 浏览过。
准备工作:
1.首先,要使用DataX我们需要先将DataX clone 到本地 git clone https://github.com/alibaba/DataX.git
2.使用IDEA IntelliJ进行开发,使用maven进行项目模块管理。
3.运行项目前确保本地已经将上文提及的外部依赖install到本地
要求maven环境,在DataX-master目录下执行以下命令,等待打包完成后再Datax-master目录下会生成target文件
mvn clean package assembly:assembly -Dmaven.test.skip=true准备工作完毕,接下来进行代码的编写
1.编写configure 阅读过DataX的quick start 之后,我们知道,要想使用DataX,需要先编写DataX使用的Configure文件,只要配置文件拼接好以后,我们启动dataX即可进行传输,所以,我们的主要工作就是编写configure
2.拼接 配置文件的json 字符串,然后切割成 String[] args 字符串数组
拼接如下json 字符串 示例 json 以Oracle为例, 各个数据库配置文件略有不同(大同小异),详情可知git上 每个插件的doc文档中均有配置模板
String dataXconfig = "{"job": {"setting": {"speed": {"channel": 1}},"content": [{"reader": {"parameter":{"autoDestroy":false,"password":"tiger","column":["NAME"],"connection":[{"jdbcUrl":["jdbc:oracle:thin:@localhost:1521:orcl"],"table":["SOURCE"]}],"position":"2018-11-22 10:50:53","username":"test"},"name":"oraclecdcreader"},"writer": {"parameter":{"autoDestroy":false,"password":"tiger","column":["NAME"],"connection":[{"jdbcUrl":"jdbc:oracle:thin:@localhost:1521:orcl","table":["SOURCE"]}],"username":"scott"},"name":"oraclewriter"}}]}}";json 查看如下
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [{
"reader": {
"parameter": {
"password": "tiger",
"column": ["NAME"],
"connection": [{
"jdbcUrl": ["jdbc:oracle:thin:@localhost:1521:orcl"],
"table": ["SOURCE"]
}],
"username": "test"
},
"name": "oraclecdcreader"
},
"writer": {
"parameter": {
"autoDestroy": false,
"password": "tiger",
"column": ["NAME"],
"connection": [{
"jdbcUrl": "jdbc:oracle:thin:@localhost:1521:orcl",
"table": ["SOURCE"]
}],
"username": "scott"
},
"name": "oraclewriter"
}
}]
}
}继续拼接,作如下处理
String SPLIT_STRING = " ";
String jobId = "自定义";
String modeStr = "-mode" + SPLIT_STRING + "standalone" + SPLIT_STRING;
String jobId = "-jobid" + SPLIT_STRING + jobId + SPLIT_STRING;
String job = "-job" + SPLIT_STRING + "string" + dataxConfig;
String[] args = (modeStr + jobId + job).split(SPLIT_STRING);如此过后 即得到DataX需要的参数args
3.调用 如下所示方法,即可进行传输
Engine.entry(final String[] args) Engine engine = new Engine();
engineMap.put(exchange.getId(), engine);
engine.entry(args);//开始交换
当插件成功结束后,会有打印如下内容:
2018-11-23 10:12:55.229 [job-1] INFO com.alibaba.datax.core.job.JobContainer -
任务启动时刻 : 2018-11-23 10:12:04
任务结束时刻 : 2018-11-23 10:12:55
任务总计耗时 : 50s
任务平均流量 : 0B/s
记录写入速度 : 0rec/s
读出记录总数 : 0
读写失败总数 : 0