本文主要记录一些关于Flink与storm,spark的区别, 优势, 劣势, 以及为什么这么多公司都转向Flink.
What Is Flink
一个通俗易懂的概念: Apache Flink 是近年来越来越流行的一款开源大数据计算引擎,它同时支持了批处理和流处理.
这是对Flink最简单的认识, 也最容易引起疑惑, 它和storm和spark的区别在哪里? storm是基于流计算的, 但是也可以模拟批处理, spark streaming也可以进行微批处理, 虽说在性能延迟上处于亚秒级别, 但也不足以说明Flink崛起如此迅速(毕竟从spark迁移到Flink是要成本的).
最显而易见的原因
网上最热的两个原因:
- Flink灵活的窗口
- Exactly once语义保证
这两个原因可以大大的解放程序员, 加快编程效率, 把本来需要程序员花大力气手动完成的工作交给框架, 下面简单介绍一下这两个特征.
1.什么是 Window
在流处理应用中,数据是连续不断的,因此我们不可能等到所有数据都到了才开始处理。当然我们可以每来一个消息就处理一次,但是有时我们需要做一些聚合类的处理,例如:在过去的1分钟内有多少用户点击了我们的网页。在这种情况下,我们必须定义一个窗口,用来收集最近一分钟内的数据,并对这个窗口内的数据进行计算。
窗口可以是时间驱动的(Time Window, 例如: 每30秒钟), 也可以是数据驱动的(Count Window, 例如: 每一百个元素). 一种经典的窗口分类可以分成: 翻滚窗口(Tumbling Window, 无重叠), 滚动窗口(Sliding Window, 有重叠), 和会话窗口(Session Window,活动间隙).
我们举个具体的场景来形象地理解不同窗口的概念. 假设, 淘宝网会记录每个用户每次购买的商品个数, 我们要做的是统计不同窗口中用户购买商品的总数. 下图给出了几种经典的窗口切分概述图:
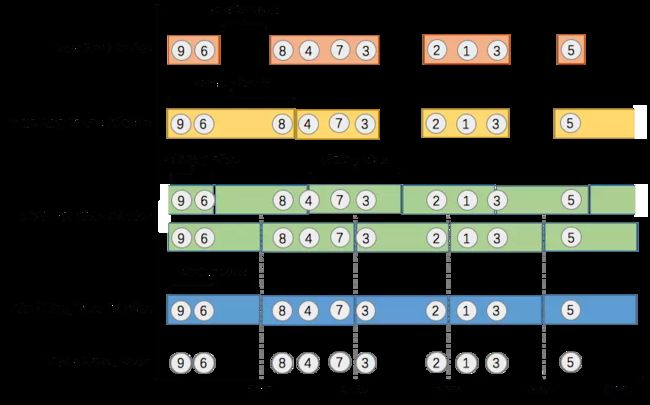
上图中, raw data stream 代表用户的购买行为流, 圈中的数字代表该用户本次购买的商品个数, 事件是按时间分布的, 所以可以看出事件之间是有time gap的. Flink 提供了上图中所有的窗口类型. 关于Flink窗口的更多细节可以参考Flink 原理与实现:Window 机制.
Exactly-once语义保证
Exactly-once语义是Flink的特性之一, 这到底是什么意思呢? 是否以为这每一份到达Flink的数据, 只会被处理一次?
官网的表述, 引用日期: 2019-01-31:
Exactly-once state consistency: Flink’s checkpointing and recovery algorithms guarantee the consistency of application state in case of a failure. Hence, failures are transparently handled and do not affect the correctness of an application.
可以看出, Exactly-once 是为有状态的计算准备的!!!
换句话说, 没有状态的算子操作(operator), Flink无法也无需保证其只被处理Exactly-once! 为什么呢? 因为即使失败的情况下, 无状态的operator(map, filter等)只需要数据重新计算一遍即可. 例如:
dataStream.filter(_.isInNYC)
当机器(节点)等失败时, 只需从最近的一份快照开始, 利用可重发的数据源重发一次数据即可, 当数据经过filter算子时, 全部重新算一次即可,根本不需要区分哪个数据被计算过,哪个数据没有被计算过,因为没有状态的算子只有输入和输出,没有状态可以保存.
此外, Flink的Exactly-once需要从最近的一份快照开始重放数据, 因此这也和数据源的能力有关, 不是所有的数据源都可以提供Exactly-once语义的. 以下是apache官网列出的数据源和Exactly-once语义保障能力列表.
| Source | Guarantees | Notes |
|---|---|---|
| Apache Kafka | exactly once | Use the appropriate Kafka connector for your version |
| AWS Kinesis Streams | exactly once | |
| RabbitMQ | at most once (v 0.10) / exactly once (v 1.0) | |
| Twitter Streaming API | at most once | |
| Collections | exactly once | |
| Files | exactly once | |
| Sockets | at most once |
有没有更深入的原因
api只是表层,有没有更深入的原因呢?例如, 基于窗口的统计, 统计最近5分钟内用户点击过的商品种类, spark streaming(或storm trident)这样的mini-batch模式也可以实现, 并且它们也提供了Exactly-once语义, 那Flink与这二者相比有什么区别呢, 又或者说有什么优势呢? 找到了两个方面的原因:
- 流处理与mini-batch的区别
- Exactly-once语义实现原理
1.流处理与mini-batch的区别
mini-batch模式的处理过程:
1.在数据流中收集记录,
2.收集若干记录后, 调度一个批处理作业进行数据处理,
3.在批处理运行的同时, 收集下一批次的记录.
也就是说spark为了处理一个mini-batch, 需要调度一个批处理作业, 相比于flink延迟较大, spark的处理延迟在秒级.
而flink只需启动一个流计算拓扑, 处理持续不断的数据, Flink的处理延迟在毫秒级别. 如果计算中涉及到多个网络shuffle, spark streaming和Flink之间的延迟差距会进一步拉大.
2.Exactly-once语义实现原理
Flink实现Exactly-once语义的原理与spark streaming是不一样的, 下文简要介绍一下流式架构的演变来了解这种区别.
流式架构的演变
在实践中, 流处理时既要保证高性能同时又要保证容错是非常困难的. 在批处理中, 当作业失败时, 可以容易地重新运行作业的失败部分来重新计算丢失的结果. 这在批处理中是可行的, 因为文件可以从头到尾重放. 但是在流处理中却不能这样处理. 数据流是无穷无尽的, 没有开始点和结束点. 带有缓冲的数据流可以进行重放一小段数据, 但从最开始重放数据流是不切实际的(流处理作业可能已经运行了数月). 此外, 如果当前的流计算是有状态的, 那就意味着除了输出之外, 系统还需要备份和恢复中间算子状态. 由于这个问题比较复杂, 因此在开源生态系统中有许多方案尝试去解决容错与性能兼容的问题.
下面介绍一些流处理架构的几种容错方法, 从记录确认到微批处理, 事务更新和分布式快照. 从以下几个维度讨论不同方法的优缺点:
- Exactly-once语义保证: 这个上文已经介绍
- 低延迟: 延迟越低越好, 许多应用程序需要亚秒级延迟(例如欺诈拦截这样的需求)
- 高吞吐量: 随着数据速率的增长, 通过管道推送大量数据至关重要.
- 强大的计算模型: 框架应该提供一种编程模型, 该模型不会对用户进行限制并保证应用程序在没有故障的情况下容错机制的低开销.
- 流量控制: 处理速度慢的算子产生的背压应该由系统和数据源自然吸收, 以避免因消费缓慢而导致崩溃或性能降低.
- 失败后的快速恢复: 这一点主流的大数据框架基本都能做到.
1.记录确认机制(Apache Storm)
开源中第一个广泛使用的大规模流处理框架可能是Apache Storm. Storm使用上游备份和记录确认机制来保证在失败后重新处理消息. Storm本身不保证状态一致性, 任何可变状态的处理都需要委托给用户处理(Storm的Trident API可以确保状态一致性, 但更加类似于spark streaming的mini-batch方式).
storm的无状态模块设计和纯记录确认体系结构, 不适合进行有状态的流计算, 也无法提供Exactly-once语义保证.
2.微批处理(Apache Storm Trident, Apache Spark Streaming)
容错流式架构的下一个发展阶段是微批处理或离散化流. 这个想法非常简单:为了解决连续计算模型(处理和缓冲记录)所带来的记录级别同步的复杂性和开销, 连续计算分解为一系列小的原子性的批处理作业(称为微批次). 每个微批次可能会成功或失败, 如果发生故障, 重新计算最近的微批次即可.
微批处理可以应用到现有引擎(有能力进行数据流计算)之上. 例如, 可以在批处理引擎Spark之上应用微批处理以提供流功能(这是Spark Streaming背后的基本机制), 也可以应用于流引擎Storm之上提供 Exactly-once 语义保证和状态恢复(这是Storm Trident背后的基本机制). 在 Spark Streaming 中, 每个微批次计算都是一个 Spark 作业, 而在Storm Trident 中, 每个微批次中的所有记录都会被合并为一个大型记录.