生产环境Full GC并宕机的亲身经历
文章目录
- 惨案的发生
- 解决方案
- 后续分析
- 可怕的String.split()
- 总结
惨案的发生
Full GC很正常,但是频繁的Full GC并且导致线上CPU飙升,然后服务直接宕掉,这是很可怕的。(前提是垃圾收集器并不是CMS)
2018年11月19号,项目升级,起初观察日志都OK,但是半小时后,服务无法访问,界面无法打开(最初是Zabbix监控CPU飙升,然后邮件告警才知道)。
然后拜托性能测试的同事帮忙一起分析问题,首先是线上Full GC异常频繁,每隔几十秒一次,半小时后CPU飙升直接宕机。我们再结合本次升级的内容及排查是否有频繁的外部请求、频繁的读取数据库的操作,终于找到问题所在:
外部会请求一个http接口,然后该接口内部,在本次升级过程中有个功能是会去读取数据库
- 外部请求该接口每秒十几笔
- 读取数据库的数据量是400万+
综上,相当于每秒会有十几次的请求数据库几百万的数据!!!
解决方案
临时解决方案
为了上线成功,当时的临时解决方案是,先将该接口的读取数据库的这一部分功能下架(因为该功能外部还不会使用到这些数据)。
后续解决方案
将这部分数据缓存起来,然后每次请求都会拿缓存的数据,而不是读取数据库(这部分数据主要是拿来对比用的)
后续分析
因为这次的问题,我专门在后续抽时间分析了这个项目的内存使用情况,造成升级失败的根本原因,其实另有隐情!而那个接口是直接导火索而已!
JVM设置情况
线上的JVM配置信息如下:
JDK1.7
-Xms4096m
-Xmx20480m
-XX:PermSize=256m
-XX:MaxPermSize=2048m
-XX:-UseGCOverheadLimit
堆设置的非常大,足足20G!!!这种情况下竟然还会频繁FullGC且服务宕掉,令人匪夷所思。
UAT环境
因为我们线上不能操作,非常严格。所以我转移到UAT环境进行持续观察,UAT的数据量、环境配置和线上是一致的。
为了观察方便,我使用本地电脑安装好的JDK工具jvisualvm进行观察,不过在观察之前需要手动配置一些东西。
-
开放jmx连接:
因为我们项目是web项目,因此需要修改tomcat中的JVM配置
cd /usr/local/tomcat/bin vim setenv.sh #JAVA_OPTS中添加如下参数 JAVA_OPTS="$JAVA_OPTS -Djava.awt.headless=true -Xms20480m -Xmx20480m -XX:PermSize=256m -XX:MaxPermSize=2048m -XX:-UseGCOverheadLimit -Dcom.sun.management.jmxremote.port=19999 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -Djava.rmi.server.hostname=183.61.26.210" export JAVA_OPTS -
本地打开jvisualvm进行连接



观察结果
-
永久代
永久代很正常,没问题。不过也是理所当然,因为永久代主要是保存一些常量、类、方法等信息

-
堆对象
令人可怕的地方就在这里,每隔两分钟Full GC,一次持续8秒左右,全世界都安静了!!!因为这个原因,CPU也不断持续的跑高。


这里顺便用命令行工具查看下堆的情况:
sudo -u tomcat jps
sudo -u tomcat jstat -gcutil 3168 1000 #每隔10秒显示堆比例
sudo -u tomcat jstat -gc 3168 10000 #每隔10秒显示堆使用大小,单位KB


堆区域说明:
- S0C:第一个幸存区的大小,单位kb
- S1C:第二个幸存区的大小,单位kb
- S0U:第一个幸存区的使用大小,单位kb
- S1U:第二个幸存区的使用大小,单位kb
- EC:伊甸园区的大小,单位kb
- EU:伊甸园区的使用大小,单位kb
- OC:老年代大小,单位kb
- OU:老年代使用大小,单位kb
- MC:方法区大小,单位kb
- MU:方法区使用大小,单位kb
- CCSC:压缩类空间大小,单位kb
- CCSU:压缩类空间使用大小,单位kb
- YGC:年轻代垃圾回收次数,单位s
- YGCT:年轻代垃圾回收消耗时间,单位s
- FGC:老年代垃圾回收次数,单位s
- FGCT:老年代垃圾回收消耗时间,单位s
- GCT:垃圾回收消耗总时间,单位s
由上图可知:
- Eden区一直在创建新对象,请求内存空间
- 当Eden区100%时触发一次YGC,然后回收垃圾,S0和S1互换,然后存活对象移到老年代O区
- 当老年代O区100%时,则触发一次Full GC,进行所有的垃圾回收
- 可以看出,主要原因是Eden区一直不断的产生很多大对象,导致很多还未来得及退出方法的对象(即某个方法执行时间比较久,方法内产生的对象有被引用,会被当做存活对象)被当做存活对象移到老年代,如此反复,发生Full GC
除此之外,我们还能知道各个区域的内存大小:
S0:1.5g
S1:1.5g
Eden:3.5g
Old:14g
这种分配比例是合理的
分析
因为这个项目是我从别人手里接手的,凭经验觉得应该是有两个线程(这里定为线程A、线程B吧)在反复的读取、组装、缓存、写文件造成的,这两个线程是每个10S运行一次的!
然后我就暂时把这两个线程停止掉,再次观察CPU和堆的消耗,结果是:一条直线,非常平稳!!!果然是这两个线程搞的鬼。(因为当时还原场景的时候没有保存图片,这里就不附图了,也懒得再去还原一遍了)
进一步分析
知道是这两个线程搞的鬼,但是这两个线程里面的业务逻辑非常复杂,一坨坨的,具体是哪个环节出问题呢?
好的,JVM最强大的分析工具要上场了:MAT
当然,第一步是要先dump文件啦!visualVM工具有dump功能。
这里是手动dump,在接近Full GC那个点的时候,请戳一下"堆 dump"按钮。会生成到指定的路径

除此之外,还可以自动在Full GC的时候出发文件dump,不过需要在JVM配置(如果dump文件巨大,比如6G以上,那么线上环境请谨慎开启,因为dump一次要几十秒):
-XX:+HeapDumpOnOutOfMemoryError
笔者dump下来的文件足足有8G多~~

第二步使用MAT工具啦。Eclipse有支持MAT的插件,具体使用百度。笔者用的是IntelliJ IDEA,如果为了一个MAT再去下载安装Eclipse,那是及其麻烦的!那么,集成版、绿色版的MAT工具来了。
下载地址:https://eclipse.org/mat/downloads.php
双击打开即可

友情提示:如果你的dump文件太大,比如我的8.5G,那么需要配置MAT的JVM参数。修改安装目录下的MemoryAnalyzer.ini文件(这里我直接上8G,电脑配置好就是任性):

这里上几张MAT分析的图吧:


其中,占据内存空间最大的是三个东东:InitListener、myScheduler-3、NgbLastCoverUtil。
其中InitListener这个类缓存很多数据,属于真正存活的对象,所以问题不是这个类。

myScheduler-3就是我上面所猜测的线程A、B,NgbLastCoverUtil类是线程A、B中会引用的类,所以之前的猜测是正确的!
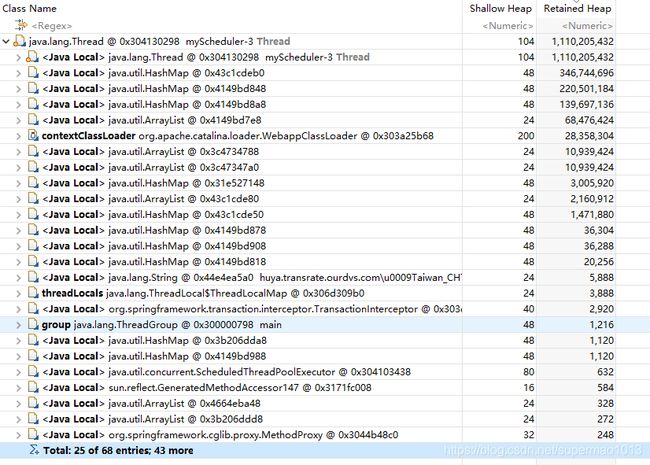

继续分析,看下myScheduler-3堆栈信息,发现最终会指向String.split()这个函数

可怕的String.split()
赶紧追溯代码,看看是不是哪里有用到String.split()函数。果不其然:
for (String line : lines) {
String[] segments = line.split("\t");
......
}
是的,有一段逻辑会用到这个函数,乍一看,lines这个变量是List< String >类型,数据量最大的时候是66w条,每一条数据按 \t 切割后,平均会有5个数组对象。
冷静思考,先google下String.split()的可怕之处,发现JDK1.6和JDK1.7下的这个方法处理方式还不一样。
JDK1.6
底层实现是这样的:
public String substring(int beginIndex, int endIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
if (endIndex > count) {
throw new StringIndexOutOfBoundsException(endIndex);
}
if (beginIndex > endIndex) {
throw new StringIndexOutOfBoundsException(endIndex - beginIndex);
}
return ((beginIndex == 0) && (endIndex == count)) ? this :
new String(offset + beginIndex, endIndex - beginIndex, value);
}
public String(int offset, int count, char value[]) {
this.value = value;
this.offset = offset;
this.count = count;
}
JDK1.6中使用String.split(),切割出来的字符串数据是直接复用了原String对象的char[],用偏移量和长度来表示不同的字符串内容,并不会创建新对象!
JDK1.7
底层实现是这样的:
public String substring(int beginIndex, int endIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
if (endIndex > value.length) {
throw new StringIndexOutOfBoundsException(endIndex);
}
int subLen = endIndex - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
return ((beginIndex == 0) && (endIndex == value.length)) ? this
: new String(value, beginIndex, subLen);
}
public String(char value[], int offset, int count) {
if (offset < 0) {
throw new StringIndexOutOfBoundsException(offset);
}
if (count <= 0) {
if (count < 0) {
throw new StringIndexOutOfBoundsException(count);
}
if (offset <= value.length) {
this.value = "".value;
return;
}
}
// Note: offset or count might be near -1>>>1.
if (offset > value.length - count) {
throw new StringIndexOutOfBoundsException(offset + count);
}
this.value = Arrays.copyOfRange(value, offset, offset+count);
}
public static char[] copyOfRange(char[] original, int from, int to) {
int newLength = to - from;
if (newLength < 0)
throw new IllegalArgumentException(from + " > " + to);
char[] copy = new char[newLength];
System.arraycopy(original, from, copy, 0,
Math.min(original.length - from, newLength));
return copy;
}
char[] copy = new char[newLength]
是的,在JDK1.7中,切割出来的每一个字符串都会创建一个新的char[]对象,而我们项目用的就是JDK1.7
那么,按照上述的数据量,则创建的新对象总数有:66w * 5 = 330w,一个巨量级,可怕!
验证
那么我们来验证一下吧,把这个线程中有关String.split()的代码去掉吧,部署上去,观察结果如下:



Full GC现在变为每隔6分钟执行一次了,虽然情况仍然很糟,但是至少有所改善,String.split()确实是一个原因所在。
所以唯一的办法就是重构这段逻辑。
总结
-
大数据量情况,避免使用String.split()
-
面对复杂的业务逻辑、大数据量的时候,如何定义数据结构、如何保存数据确实是一个难题,一定要慎重!