Naive Bayes(朴素贝叶斯)
Naive Bayes
Bayes’ theorem(贝叶斯法则)
在概率论和统计学中,Bayes’ theorem(贝叶斯法则)根据事件的先验知识描述事件的概率。贝叶斯法则表达式如下所示:
- P(A|B) – 在事件B下事件A发生的条件概率
- P(B|A) – 在事件A下事件B发生的条件概率
- P(A), P(B) – 独立事件A和独立事件B的边缘概率
Bayesian inferenc(贝叶斯推断)
贝叶斯定理的许多应用之一就是贝叶斯推断,一种特殊的统计推断方法,随着信息增加,贝叶斯定理可以用于更新假设的概率。在决策理论中,贝叶斯推断与主观概率密切相关,通常被称为“Bayesian probability(贝叶斯概率)”。
贝叶斯推断根据 prior probability(先验概率) 和统计模型导出的“likelihood function(似然函数)”的结果,再由贝叶斯定理计算 posterior probability(后验概率):
- P(H) – 已知的先验概率
- P(H|E) – 我们想求的后验概率,即在B事件发生后对于事件A概率的评估
- P(E|H) – 在事件H下观测到E的概率
- P(E) – marginal likelihood(边际似然),对于所有的假设都是相同的,因此不参与决定不同假设的相对概率
- P(E|H)/P(E) – likelihood function(可能性函数),这是一个调整因子,通过不断的获取信息,可以使得预估概率更接近真实概率
贝叶斯推断例子
假设我们有两个装满了饼干的碗,第一个碗里有10个巧克力饼干和30个普通饼干,第二个碗里两种饼干都有20个。我们随机挑一个碗,再在碗里随机挑饼干。那么我们挑到的普通饼干来自一号碗的概率有多少?
我们用 H1 代表一号碗,H2 代表二号碗,而且 P(H1) = P(H2) = 0.5。事件 E 代表普通饼干。由上面可以得到 P(E|H1) = 30 / 40 = 0.75,P(E|H2) = 20 / 40 = 0.5。由贝叶斯定理我们可以得到:
- P(E|H1)P(H1), P(E|H2)P(H2) – 分别表示拿到来自一号碗的普通饼干、来自二号碗的普通饼干的概率
- P(E|H1)P(H1) + P(E|H2)P(H2) – 表示拿到普通饼干的概率
在我们拿到饼干前,我们会选到一号碗的概率是先验概率 P(H1),在拿到了饼干后,我们要得到是后验概率 P(H1|E)
Naive Bayes Classifiers(朴素贝叶斯分类器)
在机器学习中,朴素贝叶斯分类器是一个基于贝叶斯定理的比较简单的概率分类器,其中 naive(朴素)是指的对于模型中各个 feature(特征) 有强独立性的假设,并未将 feature 间的相关性纳入考虑中。
朴素贝叶斯分类器一个比较著名的应用是用于对垃圾邮件分类,通常用文字特征来识别垃圾邮件,是文本分类中比较常用的一种方法。朴素贝叶斯分类通过选择 token(通常是邮件中的单词)来得到垃圾邮件和非垃圾邮件间的关联,再通过贝叶斯定理来计算概率从而对邮件进行分类。
由单个单词分类邮件
假设可疑消息中含有“sex”这个单词,平时大部分收到邮件的人都会知道,这封邮件可能是垃圾邮件。然而分类器并不知道这些,它只能计算出相应的概率。假设在用户收到的邮件中,“sex”出现在在垃圾邮件中的频率是5%,在正常邮件中出现的概率是0.5%。
我们用 S 表示垃圾邮件(spam),H 表示正常邮件(healthy)。两者的先验概率都是50%,即:
我们用 W 表示这个词,那么问题就变成了计算 P(S|W) 的值,根据贝叶斯定理我们可以得到:
P(W|S)和P(W|H)的含义是,这个词语在垃圾邮件和正常邮件中,分别出现的概率。通过计算可以得到 P(S|W) = 99.0%,说明“sex”的判断能力很强,将50%的先验概率提高到了99%的后验概率。
结合独立概率
大多数贝叶斯垃圾邮件分类器基于这样的假设:邮件中的单词是独立的事件,实际上这种条件一般不被满足,这也是为什么被称作朴素贝叶斯。这是对于应用情景的理想化,在此基础上,我们可以通过贝叶斯定理得到以下公式:
- p 是可疑邮件是垃圾邮件的概率
- pN 当邮件中包含第 Nth 个单词时邮件是垃圾邮件的概率 p(S|WN)
对于输出的概率,我们将它和一个 threshold(阈值)相比较,小于阈值的是正常邮件,否则认为它是垃圾邮件。
Parameter estimation and event model(参数估计和事件模型)
每一个分类的先验概率可以通过假设它们等概率(即先验概率 = 1 /(类别树)),或者通过从训练集中计算类别概率的估计得到(即先验概率 = 该分类的样本数 / 总样本数)。为了估计特征分布的参数,必须为训练集中的特征假设特征分布或者生成非参数模型。
特征分布的假设被称为朴素贝叶斯分类器的 event model(事件模型)。对于文档分类中遇到的离散事件,多项分布和伯努利分布比较适合。这些对于特征分布的不同的假设会导致最后结果并不完全相同,这些概念也经常被混淆。
Gaussian naive Bayes(高斯朴素贝叶斯)
处理连续数据的时候,一个比较典型的假设是与每个分类相关的连续值是按照高斯分布分布的。假设训练集中包含连续值 x,我们按照类别将数据分类,并计算每个分类的均值和偏差。μk是对应类别 Ck 下 x 值的均值,σk2是方差。假设我们已经收集到一些观测值 v。在给定分类 Ck 下 v 的概率分布 p(x = v | Ck 可以通过将 v 带入到由 μk 和 σk2 决定的高斯分布公式中得到。
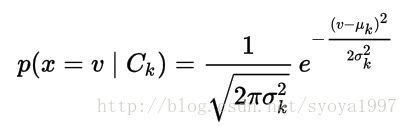
Multinomial naive Bayes(多项式朴素贝叶斯)
对于一个多项分布事件模型,样本表示了一个特定事件出现的频率,由多项分布(p1, p2, …, pn)产生,其中,pi 表示事件 i 发生的频率。特征向量 X = (x1, …, xn)可以用直方图来表示,其中 xi 表示事件 i 在特定特定情境下被观察到的次数。这是个典型的用于文档分类的事件模型,其中事件表示在单个文档中某个单词的出现。观察到特征向量的可能性为:
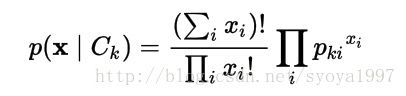
在对数空间中,多项朴素贝叶斯分类器变成了线性分类器:
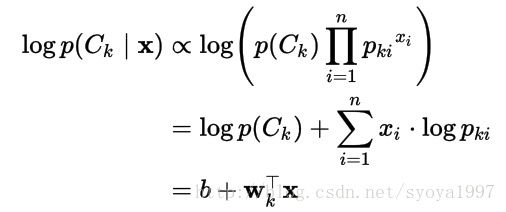
其中 b = log p(Ck),wki = log pki
如果给定的类别和特征在训练集没有一起出现,那么基于频率的概率估计就为0。当它们相乘时,将消除其他概率中的所有信息。因此我们通常希望在所有概率估计中包含被称为 pseudocount(伪计数)的小样本校正,防止由估计概率被设置为0.这种规则化朴素贝叶斯的方法被称为 Laplace smoothing(拉普拉斯平滑),当伪计数为1时,一般情况下使用 Lidstone smoothing(莱德斯通平滑)。
Bernoulli naive Bayes(伯努利朴素贝叶斯)
在多元伯努利事件模型中,特征是描述输入的二元变量。和多项式模型一样,这个模型通常用于文本分类,其中使用的是二项出现特征而不是词频。如果 xi 是用于描述词表中第 i 个单词是否出现的二元变量, 文档中给定分类 Ck 的可能性为:
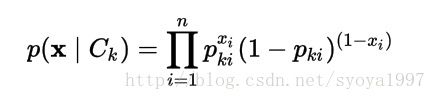
其中 pki 表示分类 Ck 产生单词 xi 的可能性。这个事件模型特别适合用于短文本分类。
Python 用法
numpy.meshgrid
Return coordinate matrices from coordinate vectors.
Make N-D coordinate arrays for vectorized evaluations of N-D scalar/vector fields over N-D grids, given one-dimensional coordinate arrays x1, x2,…, xn.
>>> import numpy as np
>>> x, y = np.meshgrid(np.arange(0, 3), np.arange(0, 2))
>>> x
array([[0, 1, 2],
[0, 1, 2]])
>>> y
array([[0, 0, 0],
[1, 1, 1]])根据给定的坐标向量创建坐标矩阵。在上面的例子中,所得到的是 X 轴上 [0, 1, 2] 和 Y 轴上 [0, 1] 构成的一个 3x2 的网格,共有 6 个点。返回的两个值中的 x 是这 6 个点 在 X 轴上的投影, y 则是这 6 个点在 y 轴的投影。
通常我们将 meshgrid 用于绘制图形:
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('ggplot')
x, y = np.meshgrid(np.arange(-1, 1, 0.01), np.arange(-1, 1, 0.01))
contor = np.sqrt(x ** 2 + y ** 2)
plt.figure()
plt.imshow(contor)
plt.colorbar()
plt.grid(False)
plt.show()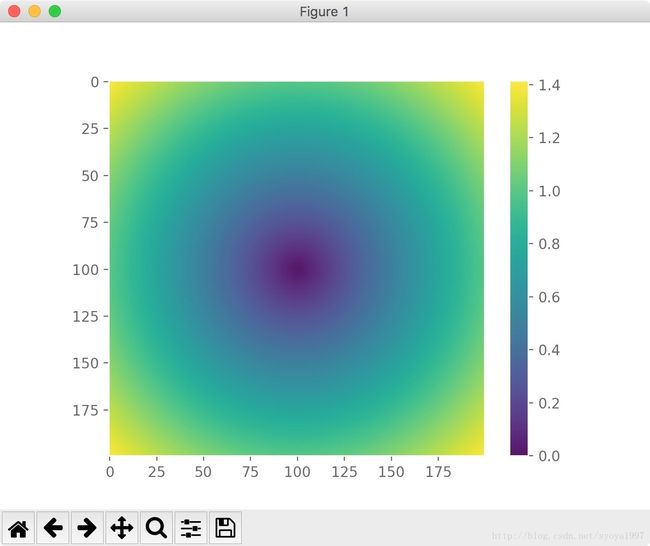
numpy.c_ (CClass object)
Translates slice objects to concatenation along the second axis.
>>> np.c_[np.array([1,2,3]), np.array([4,5,6])]
array([[1, 4],
[2, 5],
[3, 6]])
>>> np.c_[np.array([[1,2,3]]), 0, 0, np.array([[4,5,6]])]
array([[1, 2, 3, 0, 0, 4, 5, 6]])将切片对象沿第二个轴(按列)转换为连接。
numpy.ravel
Return a contiguous flattened array.
A 1-D array, containing the elements of the input, is returned. A copy is made only if needed.
>>> import numpy as np
>>> x = np.array([[1, 2], [3, 4]])
>>> y = np.array([[1, 2], [3, 4]])
>>> x.flatten()[1] = 100
>>> x
array([[1, 2],
[3, 4]])
>>> y.ravel()[1] = 100
>>> y
array([[ 1, 100],
[ 3, 4]])numpy.quiver 将多维数组降低为一位数组,和 numpy.flatten 实现的功能一样。两者的区别在于返回 copy 还是返回视图 view,numpy.flatten 返回一份拷贝,对拷贝所做的修改不会影响原始矩阵,而 numpy.ravel() 返回的是视图 view,会影响原始矩阵。
matplotlib.pyplot.pcolormesh
Create a pseudocolor plot of a 2-D array.
pyplot.pcolormesh 用于创建一个 2D 数组的伪彩色图。pcolormesh 类似于 pcolor,pcolor 返回的是 PolyCollection,但 pcolormesh 返回的是 QuadMesh。pcolormesh要快得多,所以对于大型数组来说,pcolormesh是首选。
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('ggplot')
x_min = 0.0
x_max = 1.0
y_min = 0.0
y_max = 1.0
# create data grid
h = .01
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# create classification
grid = np.c_[xx.flatten(), yy.flatten()]
pred = np.zeros((grid.shape[0], 1))
for i in xrange(0, len(grid)):
if i >= (grid.shape[0] / 2):
pred[i] = 1
pred = pred.reshape(xx.shape, order='F')
# plot figure
plt.figure()
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.pcolormesh(xx, yy, pred)
plt.show()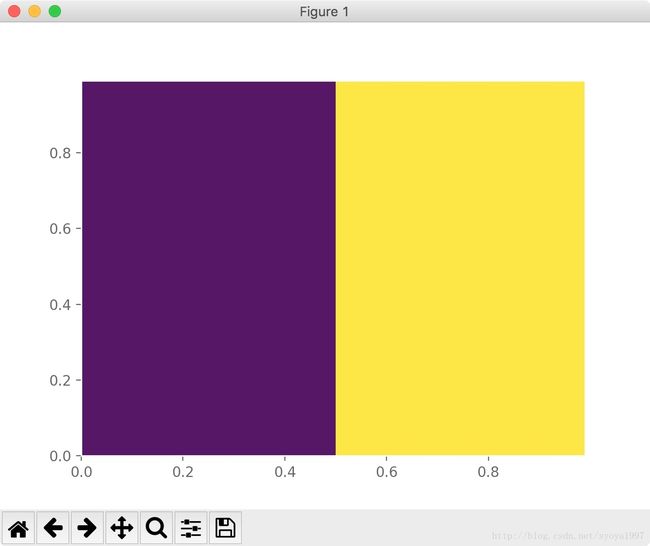
Reference
- Naive Bayes spam filtering
- Bayesian inference
- Bayesian inference
- Bayes’ theorem
- Naive Bayes classifier
- 贝叶斯推断及其互联网应用(一):定理简介
- 贝叶斯推断及其互联网应用(二):过滤垃圾邮件