Shusen Wang NLP课程学习笔记 RNN+NLP
RNN+NLP学习笔记(点击标题查看视频课程)
cyq总结(就是博主啦)
文章目录
- RNN+NLP学习笔记(点击标题查看视频课程)
- Data Processing Basics
- Processing Categorical Features
- Processing Text Data
- Tokenization
- Count Word Frequencies
- One-hot Encoding
- Text Processing and Word Embedding(嵌入)
- Text to Sequence
- Tokenizetion
- Build Dictionary
- One-Hot Encoding
- Align Sequences
- Word Embedding:Word to Vector
- One-Hot Encoding
- Word Embedding
- RNNs(Recurrent Neural Networks循环神经网络)
- model sequential data (时序数据)
- Simple RNN
- LSTM(Long Short Term Memory)
- Conveyor Belt
- Forget Gate
- Input Gate
- New Value
- Update the Conveyor Belt
- Output Gate
- Making RNNs More Effective
- stacked RNN(多层RNN)
- Bidirectional RNN(双向RNN)
- Pretrain(预训练)
- Text Generetion
- Main Idea
- example
- How to train such an RNN
- Training a Text Generator
- prepare training data
- character to vector
- Predict the Next Char
- greedy selection
- sampling from the multinomial distribution(多项式分布)
- adjusting the multinomial distribution
- Neural Machine Translation(Seq2Seq model)
- machine translation data
- Seq2Seq Model
- 网络结构(encoder-decoder network)
- 训练过程
- 翻译过程
- How to Improve
- Bi-LSTM instead of LSTM (Encoder Only!)
- Word-Level Tokenization
- Multi-Task Learning
- Attention机制
- Attention
- Attention原理
- 计算hi与s0的相关性(Weight)方法
- Option1(原论文方法)
- Option2(常用方法)
- Weights 的意义
- Self-Attention
Data Processing Basics
Processing Categorical Features
categorical features -> Numeric features(可以比较大小)
可以建立字典映射,如国家 -> one-hot encoding [0…010…0],缺失 -> [0…0]
不能用一个标量来表示categorical features
Processing Text Data
Text -> set of words (categorical features) -> Numeric vector
Tokenization
Text -> set of words
Count Word Frequencies
-
using hashmap
-
Sort the table so that the frequency is in descending order(降序)
-
Replace frequency by index (starting from 1)
The hashmap is called a dictionary, which transform a word into a number
vocabulary(词汇量): num of unique words
保留高频词,删除低频词 如保留前10K个单词,其余单词删掉
- 低频词往往无意义,如name entities,拼写错误
- bigger vacabulary -> higher-dim one-hot vectors
One-hot Encoding
-
map every word to its index
-
(transform every index to a one-hot vector)
Text Processing and Word Embedding(嵌入)
Text to Sequence
Tokenizetion
如,文本分割为单词 (text -> list of tokens)
通常,有如下思考:
- 将大写变为小写,但有时大小写不是一样的单词(Apple,apple)
- 移除stop words, 如"the", “a”, “of”
- 拼写纠错 Typo correction
Build Dictionary
一句话变为一个序列(sequences,如[1,2,3,4,1,5])
One-Hot Encoding
Align Sequences
问题:sequences长度各不相同
解决:将每个序列调整到固定长度w(对其)
- 若序列长度超过w,切割,只保留w个单词
- 若序列长度小于w,用null(0)补齐(padding)
Word Embedding:Word to Vector
One-Hot Encoding

如上图,向量维数过高会导致RNN参数过多,为此做word Embedding,目的为降维。
Word Embedding
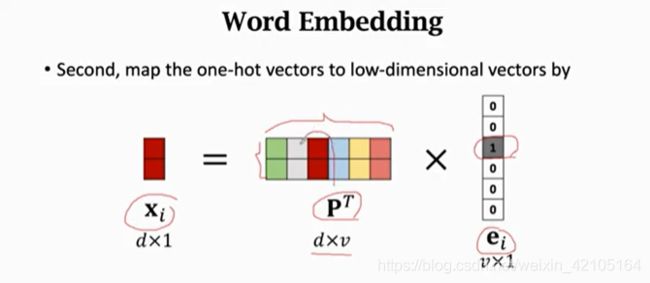
将 ei 转换为 xi 向量,其中 ei 为one-hot向量,xi 为将维后的向量。
上图中的转换其实是将一个单词转换为一个训练好的低维向量(xi和PT中的红色列向量相同),P转置中每一列为一个词向量
参数矩阵P
- 行数d用户决定,应该用cross validation来选择
- 列数v为vocabulary
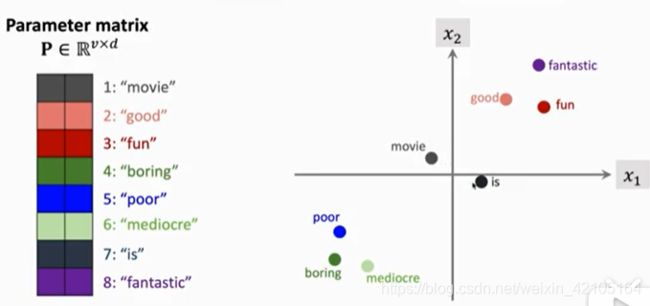
词向量是具有感情色彩的(数据集来自电影评论),假设为2d(高维的在高维空间结果应该是类似的),同一感情色彩的词应该分布在靠近的位置
RNNs(Recurrent Neural Networks循环神经网络)
model sequential data (时序数据)
FC Nets & CNN 都是one-to-one形式的神经网络,有时不适合语音的问题,因为输入和输出的长度不固定
RNNs对于model sequential data更适合(many to one)
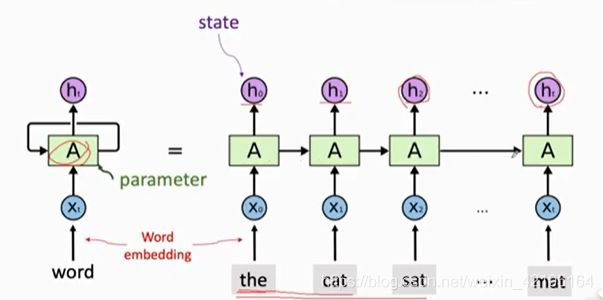
- 按顺序学习
- 使用同一个参数A
- 不断更新state,最后的state对应整个sequences
Simple RNN
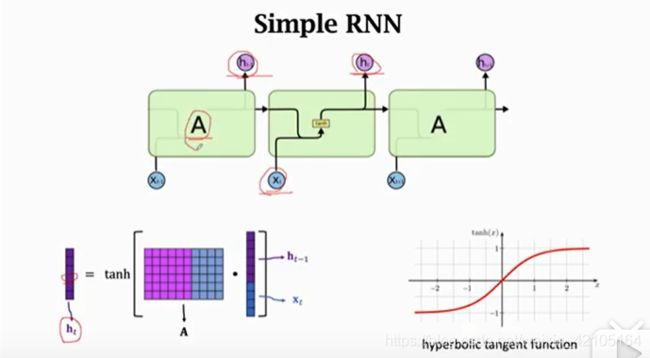
每一层都是一个函数 f(ht-1,xt) = ht,通过xt和ht-1结合成新向量后乘矩阵A,再对结果做tanh运算得到
缺点:不擅长long-term dependence
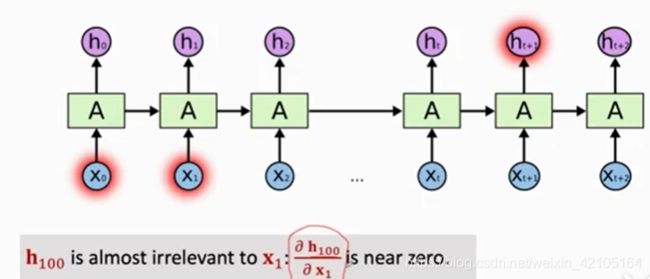
如图,对x1的改变几乎传递不到h100,这是不合理的
LSTM(Long Short Term Memory)
优点
-
对simple RNN的改进
-
避免梯度消失
-
更长的记忆

Conveyor Belt

过去信息通过传输带送到下一个时刻,不会发生太大的变化
LSTM通过传输带避免梯度消失
Forget Gate
有选择地让信息通过
- forget gate中元素为1则完全保留
- forget gate中元素为0则完全不能通过

- sigmoid将每一个元素压到0-1之间,得到f(Forget Gate)
- 将c与f进行elementwise multiplication运算
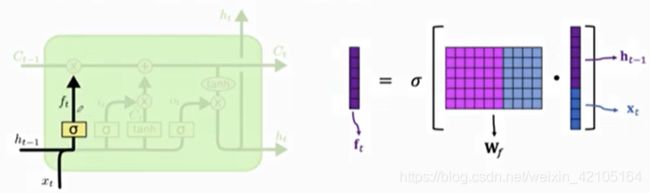
Forget Gate(f)的计算方法如上图所示,f也是一个向量
Wf需要通过反向传播从训练数据中学习
Input Gate
输入门(it)决定更新传输带中的哪一个值
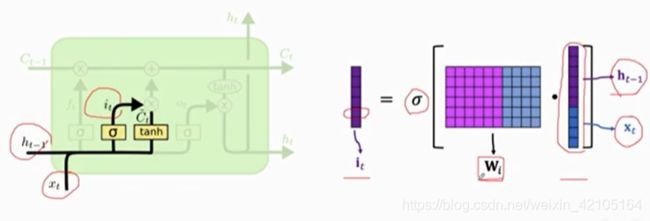
Wi需要通过反向传播从训练数据中学习,结构类似与遗忘门
New Value
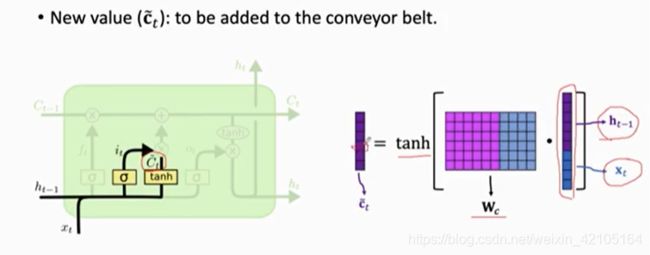
激活函数为tanh,得到的值在(-1,1)之间
Update the Conveyor Belt
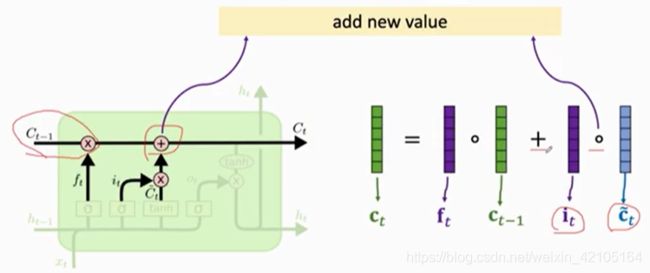
Output Gate
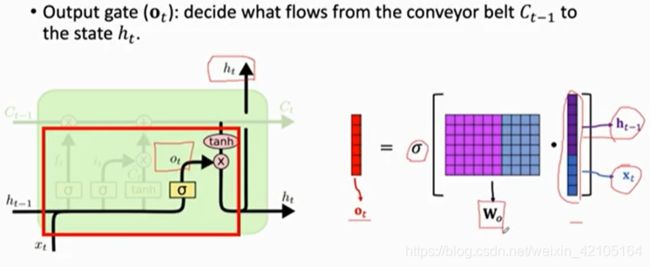
ht为LSTM的输出,输出门也用sigmoid函数

state(ht)复制了两份,一份作为LSTM的输出,一份传到了下一个LSTM中
Making RNNs More Effective
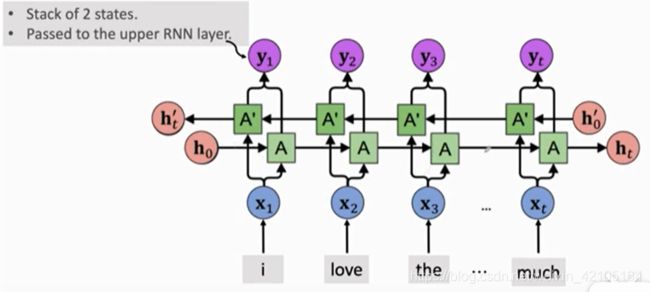
stacked RNN(多层RNN)
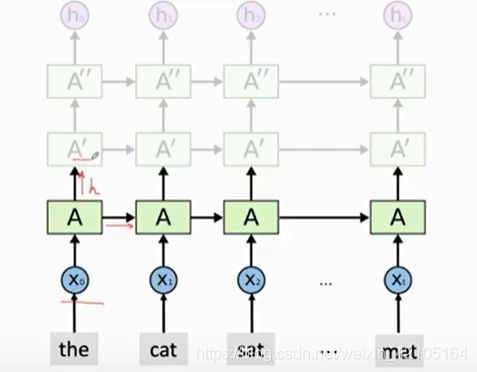
stacked RNN结构如上图所示,
最底层的RNN的输入为词向量xi,底层RNN的输出作为上层RNN的输入,以此类推。最后得到的是最后一层RNN的输出向量ht。下图为Stacked LSTM中的网络结构的概要。
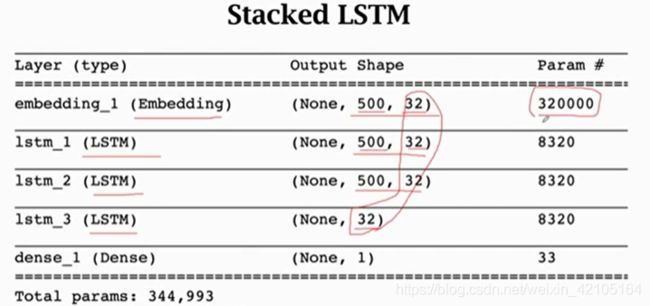
实验表示,stacked LSTM的结果没有对LSTM产生太大改善,可能是embedding中的参数过多,没有足够的训练数据(只有20K个样本),导致产生了过拟合,而这是RNN层无法去解决的
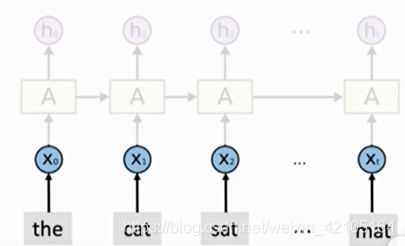
Bidirectional RNN(双向RNN)
两条RNN,一条从左往右,一条从右往左。
- 两条RNN是相互独立的,不共享参数,也不共享状态
- 两条RNN独立计算出两个状态向量,然后做concatenation得到y
如果有多层RNN,yi即为上面一层RNN的输入
如果只有一层RNN或已经是最上层的RNN,只保留ht’和ht即可([ht, ht’])
优点 双向RNN总是比单向RNN效果好,可能是因为单向RNN会遗忘早期的输入特征,而其反向的RNN正好可以予以弥补
Pretrain(预训练)
(比如预训练上文中的EMbedding Layer)
- 让模型在一个更大的数据集上训练,训练的最好是相同类型的数据集,训练使用的数据集和最终的数据集任务越相似,结果越好
- 只保留embedding层和训练好的模型参数,如图:
- 搭建新的RNN网络,新的RNN层参数是随机初始化的,而Embedding层的参数是预训练得到的,embedding layer的参数要固定住,不训练embedding layer
这个方法是不是就是迁移学习?
Always use LSTM instead of SimpleRNN
Always use Bi-RNN instead of RNN
Stacked RNN may be better than a single RNN layer
Pretrain the embedding layer if n is small
Text Generetion
Main Idea
example

假设RNN已经训练好了,输入以char-level被分割成sequence,进入RNN中进行运算(上图中的绿色部分),得到的结果向量输入softmax中进行分类,softmax的输出为如图所示的概率分布,可以看出,下一个最大可能的字符为"t",下下个最大可能的字符可能是“.”,这样生成的句子就是the cat sat on the mat.
**seed:**最初的片段,输入
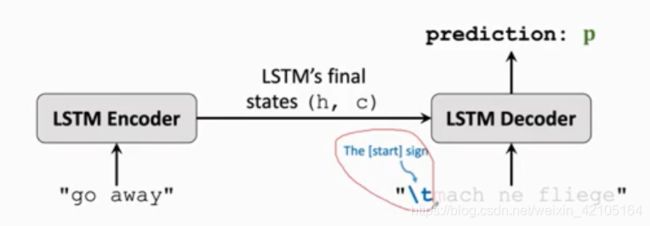
How to train such an RNN

输入文本转换为(片段 + 标签),片段为神经网络的输入,训练输入为pairs( segment, next_char) 。stride为每次获取新的片段时向后移动的字符数量。
Training a Text Generator
prepare training data

文本本身大约有600K个字符,每次stride 3个字符,所以大约有200K个片段
character to vector
character ->v * 1 vector => segment -> l * v matrix


可以看到和上面讨论的是一致的,最后得到的矩阵的列数为vocabulary。但是这里不需要embedding层
这里,一个segment表示为一个矩阵,而next_char为一个向量
注意,这里只能用单向的LSTM,因为文本预测是一个单向的问题
Predict the Next Char
承接上文的例子,预测的结果是一个57维的向量,每一个值表示一个概率。
greedy selection
选择概率最大的字符
- 确定性的,给定初始字符,后面的结果确定(不好)
sampling from the multinomial distribution(多项式分布)
- 过于随机,会产生很多拼写,语法错误
adjusting the multinomial distribution
-
pred = pred ^ (1/ temperature)
-
pred = pred / np.sum(pred)
对概率值做上述变换,大的概率会变大,小的概率会变小

Neural Machine Translation(Seq2Seq model)
(这里用英语德语转换做例子)
machine translation data
**预处理:**大写变小写,去掉标点符号等
tokenization & build dictionary
- 两种语言用两个tokenizers
- 在char-level,语言有不同的字母表
- 在word-level,语言有不同的词汇,分词方法
- 两种语言建立两个字典
- 向目标语言的字典中加入两个符号:起始符、终止符

上图矩阵就是RNN的输入
Seq2Seq Model
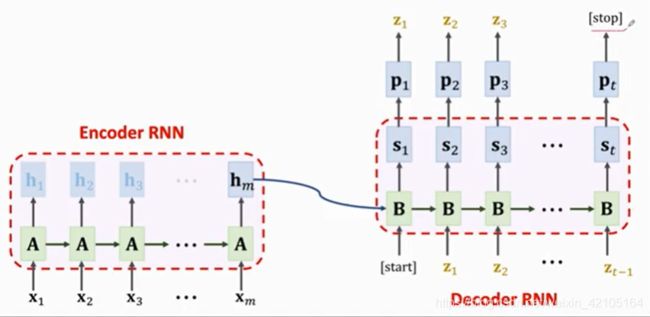
网络结构(encoder-decoder network)
模型如上图所示,encoder提取英文的特征,Decoder就是上面讲到的text generator,这里decoder的 初始状态 是encoder的states(h, c),包含encoder输出和传输带信息
训练过程

decoder输出为概率分布p,假设预测应得的第一个字母为“m”,它经过one-hot后得到的向量和p可以一同计算损失函数,损失函数越小越好,就可以反向用梯度下降更新模型中参数的值
输入为已经得到的部分(初始输入为起始符),每次预测一个字符/单词,就使用预测出的概率模型和实际的下一个输入更新一次模型参数(这里使用双向RNN)
翻译过程

用新生成的字符/单词作为输入,使用更新后的状态,用LSTM得到新的状态states和概率分布,采用一定的方法得到下一个字符/单词,并记录下来。
不断重复这个过程,更新状态,得到新的字符
如果预测到的为终止符,就终止预测,并返回record下的字符串
整个过程如下图所示:
How to Improve
Bi-LSTM instead of LSTM (Encoder Only!)
decoder是一个文本生成器,只能使用单向的LSTM
Word-Level Tokenization
英文每个单词平均4.5字符,这样输入序列长度就要短4.5倍,更短的sequence更不容易被遗忘,但是用word-level必须有足够大的数据集(避免embedding层的overfitting现象)
Multi-Task Learning
除了上文中的英文翻译成德文,还可以添加英文训练成英文等其他任务,这样相当于训练数据凭空增加了一倍,encoder的训练效果会更好
Attention机制
如下文所述
Attention
不用Attention时翻译的效果如下图蓝色曲线,使用后如红色曲线:
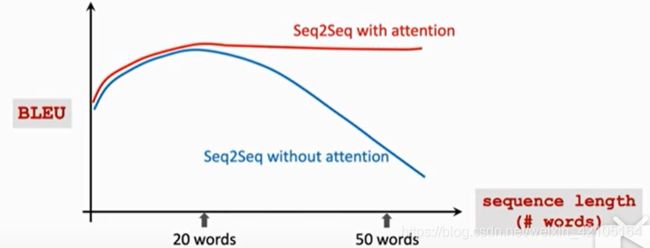
**缺点:**计算量大
Attention原理
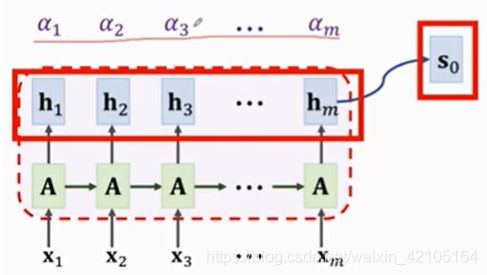
计算每一个hi与s0的相关行,这里用权重Weight表示hi与s0的相关行如下:
![]()
- For Any ai,0< ai < 1
- sum(ai) = 1
计算出结果后,对m个hi做加权平均,如下:
![]()
decoder中计算新的状态s1的方法如下:
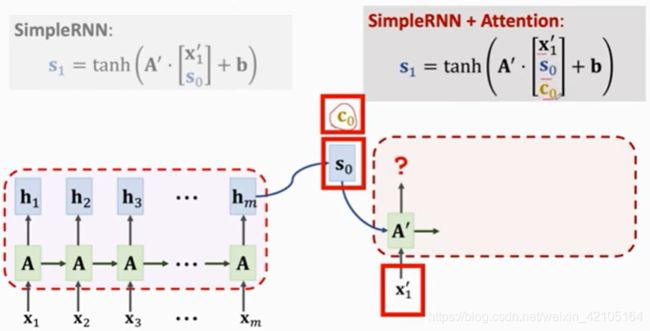
可以看到,新的计算方法使用了上面的context vector,由于context vector是m个hi的加权平均,所以c0中包含了x1-xm的完整的信息,没有遗忘。
下一步计算context vector c1 , 利用如下公式计算权重:
![]()
这里计算的是hi与状态s1的相关行,计算c1方法如下:
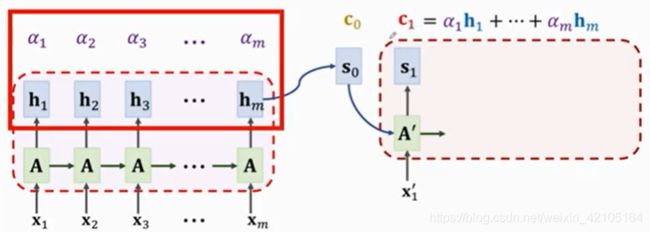
计算decoder新状态如下图所示:

如此重复,计算每一个context vector和state si
计算hi与s0的相关性(Weight)方法
Option1(原论文方法)
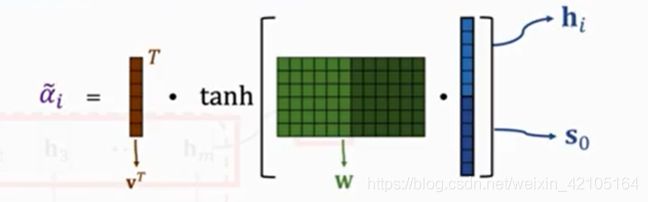
这里v和w都是参数,需要通过学习得到,然后做运算:
![]()
Option2(常用方法)

这里的Wk和Wq都要通过学习得到,这种方法被Transformer模型采用
Weights 的意义

decoder在产生下一个state之前,会看一遍encoder的所有状态。weights代表了翻译前后单词的相关性,告诉decoder应该关注encoder中的哪一个状态
Self-Attention
初始化h0,c0为全0,计算h1如下:

这里和simpleRNN相比,用c0替换了h0
h1计算出来后,就要计算新的context vector c1,c1是已有状态的加权平均,由于初始状态h0为0,所以不做考虑,c1=h1,如下图所示

拥有c1后,要计算新的状态h2如下图所示
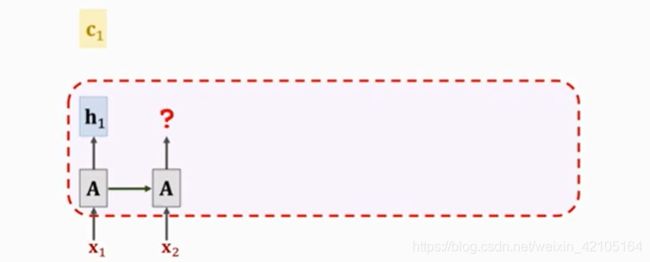
h2是c1与x2的函数,计算公式如下:

接下来计算新的context vector c2
首先计算权重a如下:
![]()
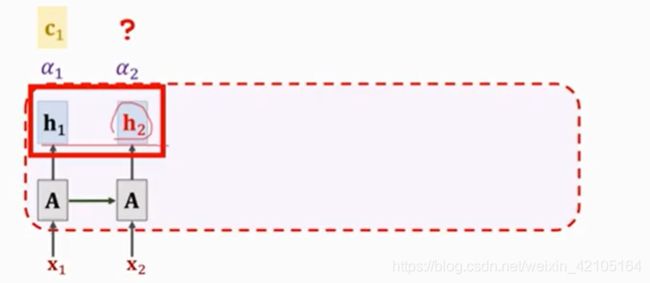
c2的计算公式如下:

重复如上过程直至结束