JUC集合类 LinkedTransferQueue源码解析 JDK8
文章目录
- 前言
- LinkedTransferQueue概述
- 术语解释
- xfer
- 交易后来的一方
- 交易先来的一方
- tryAppend
- tryMatchData
- unsplice
- 为什么是普通语义而不是CAS
- 内部删除 remove
- 迭代器
- 总结
前言
LinkedTransferQueue是一种特殊的无界阻塞队列,它提供一种Transfer的功能,用以保证生产者把数据传输给消费者。其他的普通队列,生产者是不需要关心消费者是否存在的,但现在的LinkedTransferQueue却需要保证生产者把数据确实传输给了消费者,才算是一次成功的入队操作,否则算作入队失败。
JUC框架 系列文章目录
LinkedTransferQueue概述
不管是哪种阻塞队列(无界或是有界),除了一次尝试的情况外,出队操作总会因为队列空而阻塞(或者只阻塞一段时间)。这一点LinkedTransferQueue是一样的。
而在入队情况中,以前我们学的队列,如果无界的是不可能阻塞的,如果有界的话可能因为队列满而阻塞。LinkedTransferQueue是无界的,但它的入队操作却可能阻塞。这是它与其他无界队列的最大不同,它也提供正常的不阻塞的入队操作。
在LinkedTransferQueue中,它把入队和出队两个概念更具象化了。
- 入队,就是生产者。
- 出队,就是消费者。
现在LinkedTransferQueue的队列中可能存在data node(生产者创建的节点,开始时item不为null),也可能存在request node(消费者创建的节点,开始时item为null)。换句话说,以前学的队列里面只有data node。这种request node,我们也称这种为预占模式。所以我们把这样有两种模式节点的队列称为Dual Queue双重队列。
就像以前学的队列中,第一次出队的节点必然是第一次入队的节点,为了保证FIFO嘛。现在根据LinkedTransferQueue中的两种模式的节点,也需要保证FIFO。所以LinkedTransferQueue就像一个特殊版的消消乐一样,即将新增一个data node之前,如果发现队列中有request node(而且肯定是发现的队列第一个request node),那这个data node就不用新增,直接把item传递给创建request node的线程(通过这个request node的item域)。这样,LinkedTransferQueue就保证了FIFO。即将新增request node时,也同理。
而LinkedTransferQueue的特殊功能——可以阻塞的入队操作。生产者线程成功创建并入队一个data node后,它会一直阻塞直到另一个消费者线程来临。这种实现使得生产者线程可以和消费者线程产生联动,即当生产者从阻塞的入队操作返回时,说明生产者的生产的东西已经被消费者消费掉了——这种特殊功能普通队列都无法做到。就好像交易双方(生产者和消费者)需要都在场,交易才能成立一样。但这种联动,对于消费者线程先来的情况,所有的阻塞队列都有这种联动——当消费者从阻塞的出队操作返回时,说明消费者线程消费到了一个生产者生产出来的东西。
但这种Dual Queue要实现阻塞功能不能再依靠AQS的Condition了,虽然貌似可以使用一个Lock+两个Condition来实现,一个用来阻塞生产者线程,一个用来阻塞消费者线程,通过hasWaiters判断是否有没有取消掉的节点,通过getWaitingThreads获得第一个等待的线程。但这种实现对抢锁的需求很大,每一个离开AQS条件队列的线程都会转移到AQS同步队列去抢锁,总之,这种悲观锁的实现方法使得并发量大大减小。
另外由于Condition的封装程度很高,我们其实需要,用来阻塞生产者线程的条件队列的节点,能够放置生产者的item,但这不可能。所以只能自身维护一个和阻塞生产者的条件队列的链表一同增减的存储item的链表,然后每当消费者拿走一个item时就唤醒条件队列里第一个生产者。但现在还有一个问题就是,阻塞生产者的条件队列中,如果一个node因为中断或超时而取消,存储item的链表中的某个item也需要取消,这一点无法实现,因为一个node因为中断或超时而取消并不会返回一个索引出来。总之,Dual Queue要实现阻塞功能不能再依靠AQS的Condition了。
既然不能再依靠AQS的Condition了,LinkedTransferQueue干脆就把自己的内部链表作为一个“条件队列”来实现,但实现方式却比较简单,因为本身的链表就和Condition条件队列类似,所以只需要给节点类新增一个Thread成员用来存储在交易双方先来的那一方,而交易双方后来的那一方则通过这个Thread成员来唤醒先来的一方,交易双方则通过节点类的item域来进行交易。
仔细观察Lock和Condition的实现基础,其实无外乎是CAS + volatile + LockSupport。CAS + volatile保证线程之间对数据产生正确的竞争,LockSupport实现阻塞和唤醒。在LinkedTransferQueue中,交易先来的一方负责创建节点并入队,它负责提供数据,并可能阻塞等待交易对方的到来;交易后来的一方负责CAS将节点的item修改掉。
简单理解的话,交易先来的一方,相当于调用Condition.await()(如果是一个阻塞版本的操作)。交易后来的一方,相当于调用Condition.signal(),负责唤醒沉睡在Condition上的线程。但现在LinkedTransferQueue每个节点都相当于是一个Condition,不过这个Condition最多只能阻塞一个线程——即创建这个节点的线程。
另外,需要head和tail指针一直保持在头尾的附近,因为寻找相反模式节点需要从head开始(比如,消费者从队头开始寻找第一个data node),寻找不到相反模式节点时需要添加自身node到队尾去,这需要从tail开始。在保持head和tail正确性的套路上,和ConcurrentLinkedQueue一样,使用松弛阈值来减小CAS的次数并且还保持head和tail的相对正确性。
术语解释
- data node:生产者创建出来的节点。
- request node:消费者创建出来的节点。
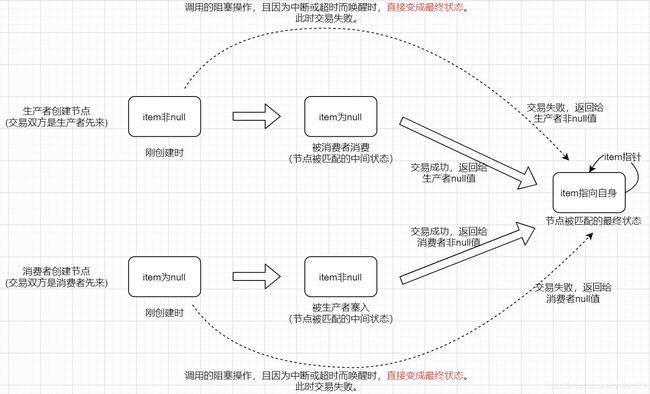
- 节点被匹配有两种状态,上图已经解释了。
- 中间状态:item的值与当初创建时不同(也就是,null和非null的转换)。
- 最终状态:item指向自身。
- 这也解释为什么节点类的item成员的类型不是
E而是Object,因为需要指向自身。
交易成功或失败:
- 生产者创建data node。刚创建时item为非null。
- 交易成功,则返回给生产者
null。即与创建时的item相反。 - 交易失败,则返回给生产者
非null。即与创建时的item相同。非阻塞的入队操作,也是这种表现。
- 交易成功,则返回给生产者
- 消费者创建request node。刚创建时item为null。
- 交易成功。则返回给消费者
非null。 - 交易失败。则返回给消费者
null。注意,出队操作是不存在非阻塞版本。(当然得除开一次尝试的版本poll(),因为一次尝试发现队列空就直接返回null了)
- 交易成功。则返回给消费者
xfer
LinkedTransferQueue所有的出队入队动作都是由xfer函数完成的。
private E xfer(E e, boolean haveData, int how, long nanos) {
if (haveData && (e == null))
throw new NullPointerException();
Node s = null; // the node to append, if needed
retry:
for (;;) { // tryAppend添加节点失败,才可能重新开始外循环
// 该循环为了找到了第一个相反模式的非匹配节点
for (Node h = head, p = h; p != null;) {
boolean isData = p.isData;
Object item = p.item;
// (item != null) == isData说明该模式节点(data or request)和它刚创建时一样,
// 这说明还没有它还没有被匹配到
if (item != p && (item != null) == isData) {
// 需要找到与参数haveData相反模式的节点,如果找到的第一个非匹配节点是相同模式的,
// 这说明后面也不可能找到相反模式的节点了,直接退出循环
if (isData == haveData)
break;
// 执行到这里说明找到了第一个相反模式的非匹配节点
// 1. 如果参数haveData是data类型,那么这里是把null改非null
// 2. 如果参数haveData是request类型,那么这里是把非null改null
if (p.casItem(item, e)) { //将一个非匹配节点变成匹配节点
//此循环永远是 h(head) -> q -> n,总之,q在h后面
//此循环在根据松弛阈值来决定更新head
for (Node q = p; q != h;) {
Node n = q.next; // update by 2 unless singleton
//先确定h确实还是head,现在q != h,q后面还有个n,说明head离n距离为2(可能后继不存在)
if (head == h && casHead(h, n == null ? q : n)) {//更新head为q的后继,如果这个后继存在
h.forgetNext();
break;
}
// 如果h局部变量已不是head,或者casHead失败,都说明h局部变量需要更新
// 更新为h(head) -> q
if ((h = head) == null ||
(q = h.next) == null || !q.isMatched())
//1. (h = head) == null说明队列没有元素
//2. (q = h.next) == null说明队列只有一个元素
//3. !q.isMatched()说明q是未匹配节点,现在head离第一个未匹配节点之间距离为1
break; // 以上情况不需要更新head
}
LockSupport.unpark(p.waiter);//既然刚完成匹配,那么唤醒等待在这个节点上的线程
//1. 如果参数haveData是data类型,说明找到的p为request节点,返回p的item为null
//2. 如果参数haveData是request类型,说明找到的p为data节点,返回p的item为非null
return LinkedTransferQueue.<E>cast(item);
}
}
Node n = p.next;
p = (p != n) ? n : (h = head); // 后移p,如果发现p脱离队列则更新为head
}
//从上面循环退出,说明找到的第一个非匹配节点是相同模式的
if (how != NOW) { // 如果不是立即返回
if (s == null) // 新建节点
s = new Node(e, haveData);
Node pred = tryAppend(s, haveData);//返回添加节点s的前驱,如果成功
if (pred == null)//添加节点失败,再次开始外循环,有可能这次不需要添加而直接Transfer
continue retry; // 添加失败,是因为检测到有相反模式的节点加入了队列
if (how != ASYNC) //只能是SYNC或TIMED,都是属于同步操作
return awaitMatch(s, pred, e, (how == TIMED), nanos);
//如果是ASYNC,那么就不需要阻塞等待交易对方的到来了,直接返回
}
//1. 如果参数haveData是data类型,且没有找到相反模式的节点,返回为非null
//2. 如果参数haveData是request类型,且没有找到相反模式的节点,返回为null
return e; // not waiting
}
}
我们知道不管是消费者还是生产者都是成对出现的,但这个函数对两种线程都能处理。我们更应该关注,它是如何处理 交易先来的一方(既可能是消费者,也可能是生产者) 和 交易后来的一方。
重要的分水岭在于if (isData == haveData) break;这句:
- 如果执行了这句break,说明当前线程是交易先来的一方。最终可能执行
tryAppend和awaitMatch。- 交易先来的一方,可能需要将自身节点入队。并且还可能需要阻塞等待 交易对方 的到来。
- 如果没有执行这句break,说明当前线程是交易先来的一方。最终将执行
return LinkedTransferQueue.直接返回。cast(item) - 交易后来的一方,则十分方便,直接获取数据item即可。
接下来简单梳理下流程,但得区分两种情况。
交易后来的一方
for (Node h = head, p = h; p != null;)循环从head开始遍历,寻找第一个未匹配节点。- 如果第一个未匹配节点的模式和当前线程模式
haveData相反,说明交易双方都到场了。 - 尝试CAS将这个相反模式的节点,变成匹配状态的中间状态。
- 如果CAS成功后,将根据松弛阈值来决定更新head。从队首出队的节点会执行
forgetNext,使得next指针指向自身。 - 然后唤醒交易先到的一方的线程。
- return相反模式的节点的item的初值。即
p.casItem(item, e)修改之前的旧值。
- 如果CAS成功后,将根据松弛阈值来决定更新head。从队首出队的节点会执行
- 如果第一个未匹配节点的模式和当前线程模式
总之,前人栽树后人乘凉,交易后来的一方直接取走数据,甚至连入队操作和阻塞操作 都不需要了。
交易先来的一方
for (Node h = head, p = h; p != null;)循环从head开始遍历,寻找第一个未匹配节点。- 如果第一个未匹配节点的模式和当前线程模式
haveData相同,这说明后面也不可能找到相反模式的节点了,直接退出循环。接下来得等交易对方的到来了。
- 如果第一个未匹配节点的模式和当前线程模式
- 根据
how参数进行不同的处理。NOW,立即返回。这种情况的返回值就是属于“交易失败”的,但这种情况不会执行tryAppend,也就是说,直接让这场交易作废,因为别的线程永远不可能找到 队列中存在交易先来的一方创建的节点。ASYNC,表现也是立即返回,但它会让交易先来的一方创建节点并入队。当前线程返回后就不关心这场交易之后会不会完成,之后可能交易对方来临后能完成这笔交易,但这是之后的时间,所以是异步ASYNC的。- 注意,出队操作可以是
NOW的,即一次尝试后成功或失败。但不可以是ASYNC的,因为出队操作是异步的没有意义,出队除了失败的情况,就必须返回一个节点。
- 注意,出队操作可以是
SYNC,表现则不能立即返回了。它会让交易先来的一方创建节点并入队tryAppend,然后自旋一段时间后再阻塞等待交易对方的到来awaitMatch。完全有可能当前线程一直阻塞在这里,除非交易对方来临、中断来临,所以是同步SYNC的。TIMED,表现也是不能立即返回,但超时后会返回。算是一个折中方案。当交易对方来临、中断来临、超时来临,xfer函数会返回。- 中断来临、超时来临,返回的情况属于“交易失败”。交易对方来临,返回的情况属于“交易成功”。
tryAppend
前面提到,交易先来的一方,除了NOW参数外,肯定会执行入队操作。
//节点类方法
final boolean cannotPrecede(boolean haveData) {
boolean d = isData;
Object x;
return d != haveData && (x = item) != this && (x != null) == d;
}
private Node tryAppend(Node s, boolean haveData) {
//t是锚点,它总是获得最新的tail;p从t这个锚点开始后移
//当p后移到队尾时,才可以尝试append
for (Node t = tail, p = t;;) {
Node n, u;
if (p == null && (p = head) == null) {//head和tail都为null
if (casHead(null, s))//初始化后,第一次append,head不为null但tail还是null
return s;//返回添加节点本身,因为没有前驱。返回非null值
}
//执行到这里,p肯定不为null
//1. 如果p是相同模式的节点(接下来这三种cannotPrecede返回false,代表s可以加在p后面)
//2. 如果p是相反模式,但p已经脱离队列
//3. 如果p是相反模式,且p没有脱离队列,且p是已匹配的
//以上情况都说明了,这与调用tryAppend的前提一样。
//4. 如果p是相反模式,且p没有脱离队列,且p是未匹配的。这就和tryAppend的前提不一样了
// (这一种cannotPrecede返回true,代表s不可以加在p后面)
//前提是:
// 除了开头的已匹配节点,队列中只有相同模式的未匹配节点,所以节点s才只能append,
// 现在说明有相反模式节点加入,所以返回null代表append失败,而且返回后这个s可能不需要加入了,
// 因为队列中可能已经有了相反模式的未匹配节点
else if (p.cannotPrecede(haveData))
return null; // lost race vs opposite mode
//如果p后面可以连接haveData类型的节点
//p的后继不为null,需要把p后移(有多种情况)
else if ((n = p.next) != null)
//1. 如果 p != t 且 t != tail
//这种情况就把p t都更新为最新的tail,像循环开始一样
p = p != t && t != (u = tail) ? (t = u) : // stale tail
//2. 如果 p == t
//3. 如果 p != t 且 t == tail
//以上两种情况都说明没有必要更新为最新tail,只需要后移p即可
(p != n) ? n : null; // 如果p已经脱离队列,那么p将会更新为head从头遍历
//执行到这里,说明p为后继为null,可以尝试添加到队尾
//如果添加到队尾失败
else if (!p.casNext(null, s))
p = p.next; // 直接后移p,因为p现在肯定有后继了(毕竟casNext都失败了)
//如果添加到队尾成功,p后面已经添加s了
else {
//p偏离锚点了,才可能去更新tail。因为p == t说明没超过松弛阈值(p(t) -> s)
if (p != t) {
//如果 p != t且tail == t,说明tail -> p -> s,距离至少为2超过了松弛阈值,则尝试casTail
//如果 tail != t那么根本不尝试CAS,而是尝试以这种形式更新t和s两个局部变量( t(tail) -> s ),如果更新成功
// 下一次循环继续,可能会尝试CAS
while ((tail != t || !casTail(t, s)) &&
//如果casTail失败,则尝试更新t s,且要求t s都不是脱离队列的节点。否则退出循环
(t = tail) != null &&
(s = t.next) != null && // advance and retry
(s = s.next) != null && s != t);
}
return p;//返回添加节点的前驱,总之是个非null值
}
}
简单的说,该函数负责s节点到队尾去。
- 如果添加成功,那么返回s的前驱(或者s本身,因为队列刚初始化,添加后只有一个节点)。
- 如果添加失败,那么返回null。
重点关注一下,返回null会造成什么。回头看xfer函数,如果tryAppend返回null,会使得xfer重新开始外循环,这意味着当前线程又会去寻找第一个相反模式的非匹配节点,虽然之前已经找过发生并没有这种节点。之所以要这样,是因为tryAppend函数执行过程中,队列由于并发 发生了变化,现在队列中已经存在着 相反模式的非匹配节点(通过cannotPrecede判断)了,所以很有必要重试xfer函数。
另外,在添加成功时,会根据松弛阈值来决定是否更新tail。
另外,添加成功的节点的Thread成员还是null的,它可能在tryMatchData中置为当前线程。
tryMatchData
前面我们提到,当参数是SYNC或TIMED时,当前线程会调用tryMatchData来自旋一段时间(有可能)后阻塞等待交易对方的到来。当这个函数退出时,可能是因为交易对方来临、中断来临、超时来临。
//s节点当初就是用e创建的
private E awaitMatch(Node s, Node pred, E e, boolean timed, long nanos) {
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Thread w = Thread.currentThread();
int spins = -1; // 初始化为一个不可能的值,正常值>=0
ThreadLocalRandom randomYields = null; // 在自旋时,用来随机判断是否需要执行yield
for (;;) {
Object item = s.item;
if (item != e) { // 说明s在append后,已经变成匹配状态的中间状态(这代表交易完成)
// assert item != s;
s.forgetContents(); // 不管是data还是request节点,都需要把item指向自身,表示匹配状态的最终状态
//所以判断一个非匹配节点时,需要排除item指向自身的情况
return LinkedTransferQueue.<E>cast(item);//返回的item和当初的e已经不同
}
//执行到这里,说明s没有变成匹配状态,而是因为中断,或者超时才被唤醒
if ((w.isInterrupted() || (timed && nanos <= 0)) &&
s.casItem(e, s)) { //item指向自己,代表匹配状态的最终状态(这是中断或超时造成的)
unsplice(pred, s); //将s从队列中断开链接
return e;
}
//执行到这里,说明s没有变成匹配状态,且当前没有发生中断或超时。这就是正常的自旋操作。
if (spins < 0) {
if ((spins = spinsFor(pred, s.isData)) > 0) //根据CPU核心和前驱类型算出一个自旋次数
randomYields = ThreadLocalRandom.current();
}
else if (spins > 0) { // 开始自旋
--spins;
if (randomYields.nextInt(CHAINED_SPINS) == 0)
Thread.yield(); // occasionally yield
}
else if (s.waiter == null) {//如果自旋结束,那么把当前线程放入s节点中。下一次循环再阻塞
s.waiter = w; // request unpark then recheck
}
//如果自旋结束,且当前线程已放入s节点中。接下来将阻塞
//如果how是TIMED,限时阻塞当前线程
else if (timed) {
nanos = deadline - System.nanoTime();//需要减去自旋已经消耗掉的时间
if (nanos > 0L)//剩余时间还大于0,那么进行 限时的阻塞
LockSupport.parkNanos(this, nanos);
}
//如果how是SYNC,无限阻塞当前线程
else {
LockSupport.park(this);
}
}
}
- 根据
spinsFor计算出一个自旋次数。 - 自旋的最后一次将当前线程放入节点的
Thread成员。下一次循环才阻塞。 - 根据
SYNC或TIMED执行不同的阻塞。 - 如果当前线程是因为 交易对方来临 而唤醒,那么返回交易结果
return LinkedTransferQueue.。cast(item) - 如果当前线程是因为 中断来临、超时来临 而唤醒,那么返回节点s创建时的初始item(e)。
注意,调用该函数时,s节点已经入队,但它的Thread成员只能在自旋完毕后才能赋值为当前线程。
private static int spinsFor(Node pred, boolean haveData) {
if (MP && pred != null) {
if (pred.isData != haveData) // 如果前驱是相反模式,s大概率是在head附近
return FRONT_SPINS + CHAINED_SPINS;
if (pred.isMatched()) // 如果前驱是已匹配节点,s大概率是在head附近
return FRONT_SPINS;
if (pred.waiter == null) // 如果前驱节点的Thread成员为null,说明前驱节点的代表线程正在自旋
return CHAINED_SPINS;
}
return 0;
}
spinsFor如果是多线程环境,会计算出一个非0的自旋次数。有趣的是,如果发现前驱节点的Thread成员为null,说明前驱节点的代表线程正在自旋,那么当前线程就一个二分之一的自旋次数进行自旋。而且,这可能会使得整个队列中出现一个自旋链FRONT_SPINS -> CHAINED_SPINS -> CHAINED_SPINS ...。
unsplice
在awaitMatch函数中如果因为中断来临、超时来临,会将当前线程创建的s节点变成已匹配状态,让交易终止。但这种情况造成的已匹配节点可能出现在链表的任何位置,我们需要清理这些无用节点,避免耗时遍历。
final void unsplice(Node pred, Node s) {
s.forgetContents(); // 变成匹配节点饿最终状态
//还记得tryAppend里,如果是队列第一次初始化入队,返回不是前驱而是s节点自身。
//pred != s就是为了排除这个情况。另外两个条件则是正常判断需要
if (pred != null && pred != s && pred.next == s) {
Node n = s.next;
//1. s的后继为null,直接进入分支
//2. s的后继不为null,且s没有脱离队列,且CAS修改pred的next指针成功,且pred是已匹配节点
//以上两种情况进入分支。注意,只要pred.casNext(s, n),断开链接的操作就已经完成了
//第二种情况CAS之前时:pred -> s -> n,CAS之后pred -> n;第一种情况进入时:pred -> s -> null
if (n == null ||
(n != s && pred.casNext(s, n) && pred.isMatched())) {
//这个循环会尝试把head更新为第一个非匹配节点(如果能找到),通过break退出循环
//如果队列中没有非匹配节点,则会尝试把head更新为最后一个匹配节点,然后通过if (hn == null)直接退出函数
for (;;) {
Node h = head;
//上面说的第一种情况:如果遇到 pred(head) -> s -> null,由于sweep函数不能处理这种情况,所以直接return(而且这符合松弛阈值)
//上面说的第二种情况:如果遇到h == pred || h == s,说明head已经到达unsplice部分,可以停止函数了
//h == null说明队列为空
if (h == pred || h == s || h == null)
return;
if (!h.isMatched())
break;
Node hn = h.next;
if (hn == null) //h是已匹配节点,且没有后继,队列实际为空
return;
if (hn != h && casHead(h, hn)) //即使更新head成功,下一次循环也会获得新head继续检查
h.forgetNext();
}
//执行到这里,说明循环找到了第一个非匹配节点。接下来可能执行sweep
if (pred.next != pred && s.next != s) { // 检查两个节点没有脱离队列
for (;;) {
int v = sweepVotes;
if (v < SWEEP_THRESHOLD) {//小于sweep阈值则加1
if (casSweepVotes(v, v + 1))
break;
}
else if (casSweepVotes(v, 0)) {//等于sweep阈值则清空后执行sweep
sweep();
break;
}
}
}
}
}
}
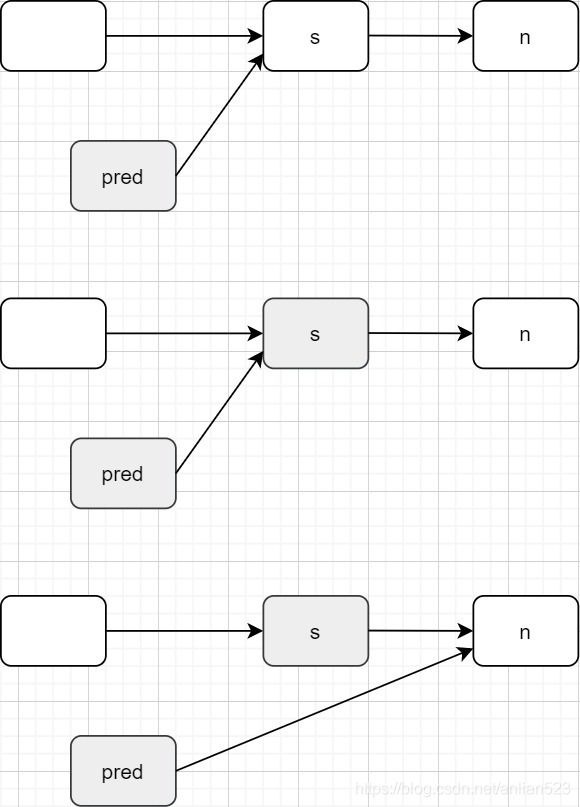
本函数有两个重点,一是使得s节点从链表中断开,二是为sweep操作投票。
函数先检测是否有pred -> s -> n这种链接关系的节点链,然后执行这句pred.casNext(s, n),执行成功就代表断开成功。

如上图,断开链接的结果是这样的,注意,s并没有next指针指向自身,这也足以使得s节点被GC。
但有两种情况,即使执行了if (n == null || (n != s && pred.casNext(s, n) && pred.isMatched())),也会使得已匹配节点留到队列中。
- s为队尾时。这种情况根本不会执行CAS操作。

- s虽然不是队尾,但pred是已匹配节点时。这种情况即使执行了CAS操作,s还是留在了队列中。
所以这两种情况需要进行sweep投票,当投票超过阈值时,则执行sweep函数。
在进行投票之前,会尝试更新head,更新为第一个非匹配节点(如果能找到),或者最后一个匹配节点。并且,排除掉一些不需要做sweep处理的情况,然后直接return。
为什么是普通语义而不是CAS
这两个函数使用的不是CAS操作,而是普通语义的写,这可能造成其他线程看不到,但是没关系。
final void forgetNext() {
UNSAFE.putObject(this, nextOffset, this);
}
final void forgetContents() {
UNSAFE.putObject(this, itemOffset, this);
UNSAFE.putObject(this, waiterOffset, null);
}
看一下forgetNext在xfer中的调用处:
if (head == h && casHead(h, n == null ? q : n)) {
h.forgetNext();
break;
}
既然新head已经生效,那么旧head的自链接是否能被别的线程也不重要了。
看一下forgetContents在awaitMatch中的调用处:
if (item != e) { // 变成了匹配状态的中间状态
// assert item != s;
s.forgetContents(); // avoid garbage
return LinkedTransferQueue.<E>cast(item);
}
既然s节点已经变成了匹配状态的中间状态,那么s节点的匹配状态的最终状态是否能被别的线程也不重要了。因为 匹配状态的中间状态 足以被判断。
内部删除 remove
删除操作自然只能删除掉data node啦。
public boolean remove(Object o) {
return findAndRemove(o);
}
private boolean findAndRemove(Object e) {
if (e != null) {
for (Node pred = null, p = head; p != null; ) {
Object item = p.item;
if (p.isData) {//如果是data node
if (item != null && item != p && e.equals(item) &&//如果节点是未匹配状态,且item与参数相等
p.tryMatchData()) {//且CAS把节点变成匹配状态成功
unsplice(pred, p);//断开p在队列中的链接
return true;
}
}
//如果p是request node
else if (item == null)//且这个request node是未匹配状态,那么说明队列中不可能有data node了,直接退出
break;
//如果p是匹配状态的request node
pred = p;//后移p
if ((p = p.next) == pred) { // 判断p不是自链接节点,否则从head从头开始
pred = null;
p = head;
}
}
}
return false;
}
迭代器
和其他并发队列一样,它的迭代器也是弱一致性的,next数据也是提前就准备好的。不过多了一个lastPred,它一般处于lastRet的前面,用来断开被删除的lastRet。
final class Itr implements Iterator<E> {
private Node nextNode; // next node to return item for
private E nextItem; // the corresponding item
private Node lastRet; // last returned node, to support remove
private Node lastPred; // predecessor to unlink lastRet
private void advance(Node prev) {
Node r, b; // reset lastPred upon possible deletion of lastRet
//lastRet非null,且未匹配
if ((r = lastRet) != null && !r.isMatched())
lastPred = r; // 把lastPred更新为lastRet
//1. lastRet为null,说明lastRet已经被删除
//2. lastRet非null,且已匹配
//1. lastPred为null
//2. lastPred非null,且lastPred已匹配
else if ((b = lastPred) == null || b.isMatched())
lastPred = null; // 这两种情况,lastPred都不能用来断开链接了,所以清空
//3. lastPred非null,且lastPred未匹配
else {//如果b(lastPred) -> s(已匹配) -> n的结构存在,那么使之变成b(lastPred) -> n
//一直循环直到这样的结构不存在
Node s, n; // help with removal of lastPred.next
while ((s = b.next) != null &&
s != b && s.isMatched() &&
(n = s.next) != null && n != s)
b.casNext(s, n);
}
this.lastRet = prev;//传进来的就是nextNode
for (Node p = prev, s, n;;) {
s = (p == null) ? head : p.next;//如果p为null,从头开始寻找;否则p的后继
if (s == null)//p没有后继,迭代器遍历结束
break;
else if (s == p) {//如果p脱离队列,那么继续循环。从头开始,走上面的流程。
p = null;
continue;
}
//p -> s结构成立
Object item = s.item;
if (s.isData) {
if (item != null && item != s) {//需要找到非匹配的data node
nextItem = LinkedTransferQueue.<E>cast(item);
nextNode = s;
return;//准备next数据就return
}
}
//如果s是request node
else if (item == null)//而且request node是个未匹配节点,那么说明队列中不可能有非匹配的data node
break;//循环结束,将清空next数据
// s是一个已匹配的request node,那么还有机会,继续寻找
if (p == null)//如果是从头开始找的,那么p变成head即可
p = s;
else if ((n = s.next) == null)//如果p -> s -> null,那么迭代器遍历结束
break;
else if (s == n)//如果s脱离队列,从头开始
p = null;
else//如果p -> s(已匹配request) -> n成立,断开s链接,下一次循环p的后继变了
p.casNext(s, n);
}
//退出循环,说明迭代器遍历结束,清空
nextNode = null;
nextItem = null;
}
Itr() {
advance(null);
}
public final boolean hasNext() {
return nextNode != null;
}
public final E next() {
Node p = nextNode;
if (p == null) throw new NoSuchElementException();
E e = nextItem;
advance(p);//返回前,准备好next数据
return e;
}
public final void remove() {
final Node lastRet = this.lastRet;
if (lastRet == null)
throw new IllegalStateException();
this.lastRet = null;
if (lastRet.tryMatchData())
unsplice(lastPred, lastRet);
}
}
在advance中,多了一个while循环来清理掉lastPred后面的已匹配节点,这其实是替unsplice擦屁股,因为unsplice有两种情况是无法断开链接的。而现在两种删除Queue.remove和Itr.remove都是使用的unsplice。
总结
- LinkedTransferQueue提供了一种传输的功能,它让生产者或消费者能够感知到对方的存在。
- 普通队列中只有data node,LinkedTransferQueue中既有data node,也有request node。所以它是一个Dual Queue双重队列。
- LinkedTransferQueue的出队入队也是符合FIFO的。
- 相比普通队列,LinkedTransferQueue的特殊功能就是:让入队操作(生产者)阻塞,直到出队操作(消费者)来临。
- 内部链表实现的功能与AQS的
Condition类似,每个节点带有阻塞功能。 - 使用松弛阈值来保持
head和tail的相对正确性。这是为了减小CAS的次数。 - 使用普通语义就能搞定的事情,就不会使用CAS。比如
forgetNext和forgetContents。这也是为了减小CAS的次数。 - 一个节点可能经历:初始状态
==>匹配状态的中间状态(item与刚创建时相反)==>匹配状态的最终状态(item指向自身)。 - 一个节点如果从队头出队,next将自链接;如果从内部删除,则只是断开链接(从队列出发找不到这个节点,从这个节点出发可以到达队列)。