数字图像中手写阿拉伯数字的识别技术概览
数字图像中手写阿拉伯数字的识别技术概览
撰文 周翔
摘要:
图像中手写阿拉伯数字的识别和其他模式的识别所采用的方法是多种多样的。本文论述了图像中手写阿拉伯数字的识别过程,并对手写数字识别的三种方法(基于规则的方法、基于统计的方法和基于神经网络的方法)进行了简要介绍和分析,并通过实例重点对基于规则的方法进行了描述。最后是对这些方法的简要评价。
1. 手写数字图像识别简介
手写阿拉伯数字识别是图像内容识别中较为简单的一个应用领域,原因有被识别的模式数较少(只有0到9,10个阿拉伯数字)、阿拉伯数字笔画少并且简单等。手写阿拉伯数字的识别采用的方法相对于人脸识别、汉字识别等应用领域来说可以采用更为灵活的方法,例如基于规则的方法、基于有限状态自动机的方法、基于统计的方法和基于神经网络的方法等。目前比较流行的方法是基于神经网络的方法和基于统计的方法,但无论使用哪种方法,也需要通过基本的图像处理技术来对图像进行预处理,才能获得这些方法的输入信息。所以,本文的开始部分先对手写阿拉伯数字识别的整个处理流程进行论述,而这个流程也可以用于图像中其他模式的识别。当然这个处理流程也不是唯一的,可以根据不同的模式识别应用场景进行与之不同的预处理流程。
2. 手写数字图像识别的主要流程
在本文中,笔者在对图像进行分析前,先对图像进行了以下处理操作。
第一步:对源图像进行黑白二值化处理,如图1。

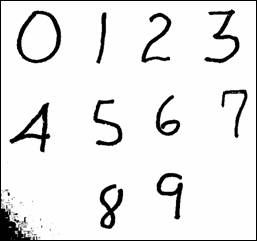
图1:源图像(左)和处理后的图像(右)
第二步:对第一步处理后的图像进行形态学图像处理中的开运算,然后再进行闭运算(如图2),先进行开运算的目的是去除图像中的离散黑色像素点,再进行闭运算可以填补手写数字中的裂缝。为了突出变换前后的区别,图2中将源图像中的一部分放大显示,可以看出,经过处理,数字7上面横线中的空虚白色像素被黑色像素填实。


图2:进行闭操作前的二值图像(左)和经过闭操作后的二值图像(右)
第三步:为了提取出图像中的每一个数字,可用泛洪(FloodFill)算法,从数字上的某个像素开始对数字进行填充,也可以按从左到右、从上到下的顺序扫描图像,找到一个黑色的像素开始填充,当填充结束时,所得到的填充区域就是图中某个手写阿拉伯数字的图像区域,这时,得到这个阿拉伯数字图像区域中像素坐标点对的集合,如图3所示。
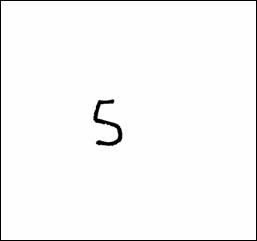
图3:对第二步处理后的图像中的某个像素进行泛洪填充提取出的数字5的图像
第四步:通过第三步得到的某个数字的像素坐标点对的集合,通过骨架提取算法(见参考文献3)提取出手写数字的骨架,再将其骨架图像映射到某个8×8的0/1矩阵,矩阵中值为1的点表示手写数字骨架经过的矩阵中的点,0表示数字的背景,要求数字图像的每一行或每一列都至少有一个值为1,如图4所示。
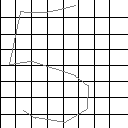

图4:数字5的骨架(左)和映射到8×8矩阵中的情况(图中灰色表示1,白色表示0)
可以想象出,矩阵的行列数越大,表示的骨架越精确,但对于手写阿拉伯数字的识别来说,取8×8的矩阵就足够了。如果要进行汉字手写体的识别,一般需要用64×64的矩阵或者128×128的矩阵。
第五步:对8×8的0/1矩阵进行内容分析。其中分析的方法主要有基于规则的方法、基于统计的方法和基于神经网络的方法,这三种方法将在本文的第3、4、5部分进行介绍。通过这些方法可以识别8×8的0/1矩阵中的数字,然后输出结果,转向第三步对图像中的其他数字进行识别。
3. 基于规则的方法
基于规则的方法主要是根据0/1矩阵的特征对矩阵所描述的图形表示的内容进行描述。在这里,我采用的是对矩阵的一行为一步进行特征判断。可以事先规定阿拉伯数字在矩阵中靠左上角显示,则有这样的规则:如果矩阵第一行中有两个值为1,而且这两个1之间有大于1个的0,则这个矩阵所表示的数字为4。用规则的方法进行识别时,可以采用规则树的结构进行判断,树的每一层对应矩阵某一行的规则,比如,对于n行矩阵,树的第k层对应矩阵的第k行的规则(1<=k<=n),如图5所示,树中的节点是“规则{满足规则的数字的集合}”的形式。

图5:规则树
在运行该算法时,程序会从根节点(开始节点)开始根据规则沿着某条分支到达叶节点,这时候算法结束,输出节点集合中的元素。往往这样的集合中的元素个数为1个,也有时候是多个,比如手写体的数字1和7很像,当算法结束时,有可能会输出两个结果。
这个算法的时间复杂度正比于矩阵的行数,在本例中,因为矩阵有8行,则最多需要进行8步判断可以得出识别结果。可见,算法的复杂度与规则树的分叉数无关。而规则分的越细,分叉数越多,对象的区分度越好,搜索过程中对树的遍历深度越少,识别的正确率就越高。可见,定义一系列精密的规则是采用本方法进行模式识别的关键。
当然,也可以每一步按每列的规则进行判断,方法与上面的叙述类似。
4. 基于统计的方法
基于统计的模式识别方法是根据系统已有的统计信息,在当前的实例情况下,取概率最大的一个模式。这里的模式是阿拉伯数字。如果设当前的实例为E,阿拉伯数字为N,则我们要求的是对所有的E,条件概率值P(N|E)最大的一个N。即:
![]()
对上式的右端进行分母归一化处理并假设所有阿拉伯数字出现的概率是相等的,则上式可简化为:
![]()
也就是要求对于数字N,它的图像是E的概率为最大的那个数字N。当然,对整个图像求概率得到的结果是非常小的,而且求解过程比较困难,我们可以对整个图像进行区域划分,进行粒度计算得出在每个区域中对应的数字出现的概率,并将这些概率值进行平滑处理或放大处理,然后把这些概率值相乘,最后取条件概率最大的一个数字,就是阿拉伯数字的识别结果。
同时,还可以采用隐马尔可夫模型(HMM)的思想(见参考文献2),如果按照在本文第2节中的预处理流程得到的结果,设观察序列是8×8矩阵中的0/1值,状态是阿拉伯数字,可以通过样本进行参数训练,得出HMM的参数,然后通过Viterbi算法得出在已知状态序列(8×8矩阵中的0/1值)的情况下,求出概率最大的状态(即阿拉伯数字,也就是识别结果)。
5. 基于神经网络的方法
神经网络的方法是采用人类大脑神经中学习反馈的思想,通过用户训练得出正确的识别结果。您可以通过网页http://www.vckbase.net/document/viewdoc/?id=1187来查看这种方法的具体实现过程和源代码。
6. 分析与总结
通过上面的分析,我们可以看出,基于规则的方法,相对较为简单,比如手写阿拉伯数字识别等识别对象较少的情况,有比较少的时间复杂度和比较高的识别正确率,这种方法的关键在于规则的定义对模式是否有较高的区分度;这种方法对于比较复杂的情况,则需要一个规则库来保存这些规则,但这时,规则的设计也会变的复杂而且困难。
基于统计的方法需要维护一个具有一定规模的样本库,而且在使用HMM进行数字识别时计算量较大。样本库的规模越大,样本的分布越接近于实际情况,数字识别的正确率越高。在使用基于统计的方法的时候还需要数据平滑的技术来扩大小概率的值。
基于神经网络的方法是当今应用的最广泛的方法,其特点在于样本数可以比较少,神经节点的激励函数的运算与HMM中的概率计算相比较为简单,因此有比较好的运行效率,实现比较简单。但识别的过程需要人的参与(训练),识别的正确率受用户主观因素的影响。
基于有限状态自动机的方法也可以看做是基于规则的方法,单独将这种方法作为数字识别的系统比较少,因为对于复杂的应用,形成的有限状态自动机的拓扑结构往往比较复杂。在比较简单的情况下,如7段码数字识别,将会有较其他基于规则的方法更快的识别效率和更高的准确率。
参考文献:
[1] MICHAEL SIPSER著,张立昂等译,《计算理论导引》,机械工业出版社,2000。
[2] 王晓龙,关毅等编,《计算机自然语言处理》,清华大学出版社,2005。
[3] R.C.Gonzales等著,阮秋崎等译,《数字图像处理》,电子工业出版社,2002。
[4] 王文杰等编,《人工智能原理》,人民邮电出版社,2003。