|
为什么对象-关系数据库的映射对于现代开发者是一件大事呢?一方面,对象技术(例如 Java 技术)是应用于新软件系统开发的最常见的环境。另外,关系数据库仍然是许多人都青睐的持久信息存储方法,并且在较长时间内这种情况不太会改变。请继续读下去,了解如何使用这种技术。
为什么要写有关对象-关系数据库之间的映射的文章呢?因为在对象范例和关系范例之间“阻抗不匹配”。对象范例基于软件工程的一些原理,例如耦合、聚合和封装,而关系范例则基于数学原理,特别是集合论的原理。两种不同的理论基础导致各自有不同的优缺点。而且,对象范例侧重于从包含数据和行为的对象中构建应用程序,而关系范例则主要针对数据的存储。当为访问而寻找一种合适的方法时,“阻抗不匹配”就成了主要矛盾:使用对象范例,您是通过它们的关系来访问对象,而使用关系范例,则通过复制数据来联接表中的行。这种基本的差异导致两种范例的结合并不理想,不过话说回来,本来就预料到会有一些问题。使对象-关系数据库之间的映射成功的一个秘诀就是理解这两种范例和它们的差异,然后基于这些认识来进行明智的取舍。 本文应该能够消除现今开发周期中一些普遍共有的误解,对对象-关系数据库之间映射所涉及到的一些问题提供了切合实际的看法。这些策略基于我的开发经验,项目范围从小到大,涉及金融、销售、军事、远程通信和外购等行业。我已对使用 C++、 Smalltalk、Visual Basic 和 Java 语言编写的应用程序应用了这些原则。 如何将对象映射成关系数据库
在这一节中,我会描述一些将对象成功映射成关系数据库所需的基本技术。
- 将属性映射成列
- 在关系数据库中实现继承
- 将类映射成表
- 映射关联、聚合和组合
- 实现关系
将属性映射成列
类属性将映射成关系数据库中的零或几列。要记住,并不是所有属性都是持久的。例如, Invoice 类会有 grandTotal 属性,这个属性由其实例在计算时使用,但它不保存到数据库中。而且,某些对象属性本身就是对象,例如 Course 对象有一个作为属性的 TextBook 实例,它映射为数据库中的几列(实际上,很有可能 TextBook 类本身就将映射成一个或多个表)。重要的是,这是一个递归定义:有时属性将映射成零或者多列。也有可能将几个属性映射成表中的单一列。例如,代表美国邮递区号代码的类可以有三个数字属性,每个都表示完整邮政编号代码中的每一部分,而邮政编号代码可以在地址表中作为单一的列存储。 在关系数据库中实现继承
在将对象保存到关系数据库中时,继承的概念中发生几个有趣的问题。(请参阅参考资料中的 "Building Object Applications That Work"。)问题从根本上归结为解释如何在您的持久模型中组织继承的属性。解决这个难题所用的方法会对系统设计有很大影响。将继承映射到关系数据库中有三种基本解决办法,为更好地理解它们,我将讨论在图 1 中显示的映射类图表的优缺点。为简化问题,我没有为类的所有属性都建模;也没有为其完整签名或任何类方法建模。 图 1. 简单类层次结构的 UML 类示意图
 将类映射成表
类到表的映射通常不是直接的。除了非常简单的数据库以外,您不会有类到表的一对一映射。在以下章节中,我将讨论为关系数据库实现继承结构的三种策略:
- 整个类层次结构使用一个数据实体
- 每个具体类使用一个数据实体
- 每个类使用一个数据实体
整个类层次结构使用一个数据实体
使用这种方法,您可以将一个完整类层次结构映射成一个数据实体,而层次结构中所有类的所有属性都存储在这个实体中。图 2 描述了采取这个方法时图 1 的类层次结构的持久模型。请注意,为表的主键引入了一个 personOID 列 - 我在所有解决方案中都使用 OID (没有商业含义的标识,又称替代键),只是为了保持一致和使用我所知道的向数据实体分配键的最好办法。 图 2. 将类层次结构映射成单一数据实体
 这种方法的优点是简单,因为所需的所有人员数据都可以在一张表中找到,所以在人们更改角色时支持多态性,并且使用这种方法,专门报告(为一小组用户特定目的所执行的报告,这些用户通常自己写报告)也非常简单。缺点是每次在类层次结构的任何地方添加一个新属性时都必须将一个新属性添加到表中。这增加了类层次结构中的耦合 - 如果在添加一个属性时有任何错误,除获得新属性的类的子类外,还可能影响到层次结构中的所有类。它还可能浪费数据库中的许多空间。我还必须添加 objectType 列来表明行代表的是学生、教授还是其它类型的人员。在人们具有单一角色时这种方法很有效,但如果他们有多个角色(例如,一个人既是学生又是教授),很快就会失效。 每个具体类使用一个数据实体
使用这种方法,每个数据实体就既包含属性又包含它所表示的类继承的属性。图 3 描述了采取这个方法时图 1 的类层次结构的持久模型。有与 Student 类对应的和与 Professor 类对应的数据实体,因为它们是具体类,但没有与 Person 类对应的数据实体,因为它是抽象类(它的名称以斜体字表示)。为每个数据实体都分别分配了自己的主键, studentOID 和 professorOID。 图 3. 将每个具体类映射成单个数据实体
 这种方法最大的好处是,它仍然能相当容易地执行专门报告,只要您所需的有关单一类的所有数据都只存储在一张表中。但也有几个缺点。一个是当修改类时,必须修改它的表和它所有子类的表。例如,如果要向 Person 类添加高度和重量,就需要同时更新两个表,它会涉及很多工作。第二,无论何时,只要对象更改了它的角色 - 可能您聘用了您一个刚毕业的学生作为教授 - 则需要将数据复制到相应的表中,并为它指定一个新的 OID。这又涉及到很多工作。第三,很难在支持多个角色的同时仍维护数据完整性。(这种情况是可能的;只是比原先困难一点。)例如,您会在哪里存储既是学生又是教授的人的姓名呢? 每个类使用一个数据实体
使用这种方法,为每个类创建一张表,它的属性是 OID 和特定于该类的属性。图 4 描述了采取这个方法时图 1 的类层次结构的持久模型。 请注意,将 personOID 用作了所有三个数据实体的主键。图 4 的一个有趣的特性是,为 Professor 和 Student 中的 personOID 列都分配了两个构造型,而这在标准建模语言 (UML) 中是不允许的。我的意见是,这是一个必须由 UML 持久性建模概要解决的问题,甚至可能在这个建模规则中也需要更改。(有关持久性模型的详细信息,请参阅参考资料中的 "Towards a UML Profile for a Relational Persistence Model"。) 图 4. 将每个类映射成它自己的数据实体
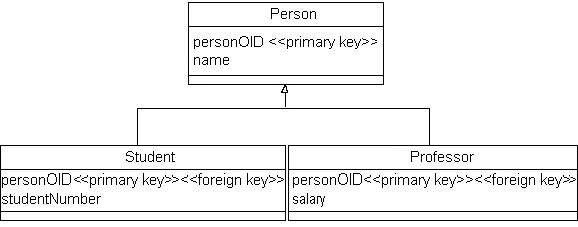 这种方法的最大好处就是它能够最好地适应面向对象的概念。它能够很好地支持多态性,对于对象可能有的每个角色,只需要在相应的表中保存记录。修改超类和添加新的子类也非常容易,因为您只需要修改或添加一张表。这种方法也有几个缺点。第一,数据库中有大量的表 -- 实际上每类都有一个(加上维护关系的表)。第二,使用这种技术读取和写入数据的时间比较长,因为您必须访问多个表。如果通过将类层次结构中的每个表放入不同物理磁盘驱动器盘片(假设每个磁盘驱动器磁头都单独操作)上来智能地组织数据库的话,就可以缓解这个问题。第三,有关数据库的专门报告很困难,除非添加一些视图来模拟所需的表。 比较映射策略
现在,请注意,每个映射策略怎样产生不同的模型。要理解三种策略之间的设计优缺点,请考虑图 5 中显示的对我们的类层次结构做些简单的更改:添加了 TenuredProfessor,这是从 Professor 中继承的。 图 5. 扩展初始类层次结构
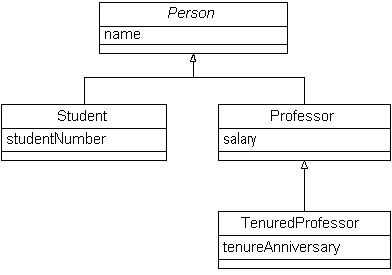 图 6 显示了一个更新过的持久性模型,用于将整个类层次结构映射成一个数据实体。尽管很明显,数据库中的空间浪费增加了,但请注意,按照这种策略操作,只需花非常小的代价就可以更新模型。 图 6. 将扩展的层次结构映射成单一数据实体
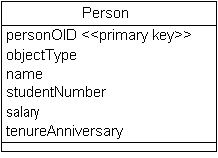 图 7 显示了将每个具体类映射成数据实体时的持久性模型。使用这个策略,虽然因为我们从教授提升到终身教授,这样对象和我们的关系就有了改变(学生变成教授),所以如何处理对象的这个问题更复杂了,但我只需要添加一个新表。 图 7. 将扩展的层次结构的具体类映射成数据实体
 图 8 显示了第三种映射策略的解决方案 -- 将单个类映射成单个数据实体。这需要我添加一个只包括 TenuredProfessor 类的新属性的新表。这种方法的缺点是,要使用新类的实例,它需要好几个数据库访问。 图 8. 将扩展的层次结构的所有类映射成数据实体
 要摒弃这样一种观点,即这些办法都不够好;每种办法都有其优缺点。在下面的表 1 中对它们进行比较。 表 1. 比较映射继承的各种办法
|
考虑因素
|
每个层次结构一张表
|
每个具体类一张表
|
每个类一张表
|
| 专门报告 |
容易
|
中等
|
中等/困难
|
| 实现的难易程度 |
容易
|
中等
|
困难
|
| 数据访问的难易程度 |
容易
|
容易
|
中等/容易
|
| 耦合 |
非常高
|
高
|
低
|
| 数据访问速度 |
快
|
快
|
中等/快
|
| 对多态性的支持 |
中等
|
低
|
高
|
映射关联、聚合和组成
不仅必须将对象映射到数据库中,还必须将对象之间的关系进行映射,这样才能在以后进行恢复。对象之间有四种类型的关系:继承、关联、聚合和组成。要有效地映射这些关系,必须理解它们之间的差异、如何实现一般的关系,以及如何实现特定的多对多关系。 关联、聚合和组合之间的差异
从数据库的角度看,关联和聚合/组合关系之间的唯一不同是对象相互之间的绑定程度。对于聚合和组合,在数据库中对整体所做的操作通常需要同时对部分进行操作,而关联就不是这样。 在图 9 中有三个类,其中两个在它们之间有简单的关联关系,有两个共享聚合关系(实际上,组合可能是这种模型中更确切的说法)。(有关关系的详细信息,请参阅参考资料中的 "Building Object Applications That Work"。)从数据库的观点看,聚合/组合和关联是不同的,在聚合情况下,在整体中读取时,您通常希望在部分中读取,而在关联情况下,需要执行什么操作并不总是那么明显。在将对象保存到数据库中或从数据库中删除对象也存在相同的情况。当然,上述讨论通常特定于商业领域,但这种经验之谈往往在很多情况下出现。 图 9. 关联和聚合/组合之间的差异
 在关系数据库中实现关系
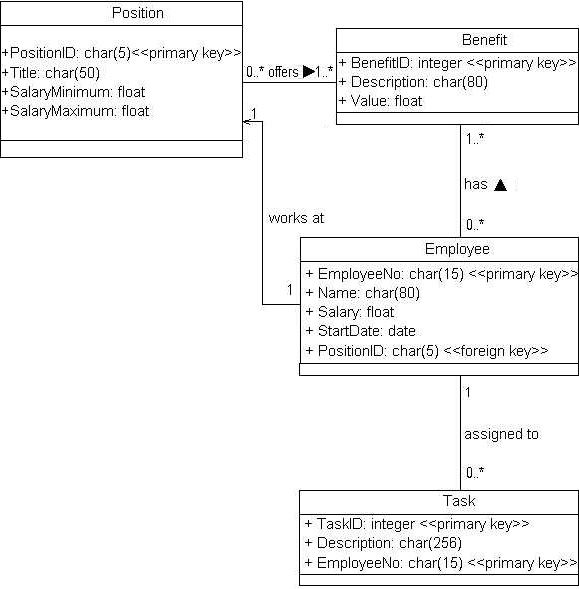
关系数据库中的关系是通过使用外键来维护的。外键是在一张表中出现的一个或多个数据属性;它可以是另一张表的键的一部分,或者干脆碰巧就是另一张表的键。外键可以让您将一张表中的一行与另一张表中的一行相关起来。要实现一对一和一对多的关系,您只需要将一张表的键包括在另一张表中。 在图 10 中有三张表,它们的键 (OID) 和外键用于在它们之间实现关系。首先,在 Position 和 Employee 数据实体间有一个一对一的关联。一对一关联就是它的每个复合度的最大值都是 1 的这么一种关系。要实现这个关系,我在 Employee 数据实体中使用属性 positionOID,Position 数据实体的键。因为关联是单向的 -- employee 那些行知道它们的位置行,但反过来就不行 -- 所以我必须这么做。如果这是个双向的关联,我还会在 Position 中添加一个名为 employeeOID 的外键。然后,使用相同的方法在 Employee 和 Task 之间实现了多对一关联(又称为一对多关联),唯一的不同是将外键放在了 Task 中,因为它在关系的“多”方。 图 10. 简单人力资源数据库的持久性模型。
 实现多对多关联
要实现多对多关系,需要关联表的概念,它是一种数据实体,唯一目标是在关系数据库中维护两个或多个表之间的关联。图 10 中,在Employee 和 Benefit 之间有一个多对多关系。图 11 中,可以看到如何使用关联表来实现多对多关系。在关系数据库中,关联表中包含的属性传统上是关系中涉及到的表中的键组合。关联表的名称通常是它所关联的表的名称组合,或者是它实现的关联的名称。在这种情况下,我选择 EmployeeBenefit 而不是 BenefitEmployee 和 has,因为我觉得它可以更好地反映关联的性质。 图 11. 在关系数据库中实现多对多关系
 看一下图 11 中应用程序的复合度。规则是,一旦引入了关联表,复合度就“交叉”,如图 12 所示。值为 '1' 的复合度总在外边缘引入,如图 11 和 12 中所示,以保留原始关联的整体复合度。原始的关联表明雇员有一种或多种福利,并且任何给定的福利都给予一个或多个雇员。在图 11 中您可以看到,即使在有关联表维护关联的情况下仍然是这种情况。 图 12. 关联表简介
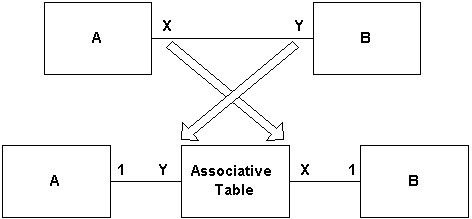 有必要注明我选择应用构造型“<<关联表>>”而不是关联类的说明 -- 将关联类与它所描述的关联连接的虚线行 -- 出于两个原因。首先,关联表的目的是实现关联,而关联类的目的是描述关联。其次,图 11 中采取的方法反映了为使用关系技术所需的实际实现策略。 结束语
在本文中,探索了对象-关系数据库之间的映射的基础。如果按照本文中描述的步骤操作,就可能方便地将对象成功存储在关系数据库中。如果有任何问题,请发电子邮件给我,地址是 [email protected],如果有兴趣对持久性模型的 UML 概要提供建议,请放在关于持久性模型概要开发的工作页面上就可以了。 参考资料
- Building Object Applications That Work: Your Step-By-Step Handbook for Developing Robust Systems with Object Technology by Scott W. Ambler (New York:SIGS Books/Cambridge University Press)
- Process Patterns: Building Large-Scale Systems Using Object Technology by Scott W. Ambler (New York:SIGS Books/Cambridge University Press)
- The Object Primer 2nd Edition -- The Application Developer's Guide to Object-Orientation by Scott W. Ambler (New York:Cambridge University Press)
- Scott W. Ambler 的过程模式资源页面
- Scott W. Ambler 的“增强标准过程”
- Scott W. Ambler 的 Towards a UML Profile for a Relational Persistence Model: Working Page。
关于作者

Scott W. Ambler 是 Ronin International 的总裁,这家公司是专门研究面向对象的软件过程教学、体系结构建模和 Enterprise JavaBeans (EJB) 开发的咨询企业。他创作或与他人合著了几本有关面向对象开发的书籍,包括最近发行的 The Object Primer 2nd Edition,该书详细介绍了本文所概述的主题。可以通过 [email protected] 与他联系。
|