一、为什么需要全文索引?
通过 前面的文章 我们了解到 B+ 树索引具有"最左前缀匹配"的特性,因此,对于以下查询 B+ 树索引能很好的适配。
SELECT * FROM blog WHERE content like 'xxx%'
但是 B+ 树索引对于 '%xxx%' 式的匹配却显得无能为力,而这正是全文索引的用武之地。从 InnoDB 1.2.x 版本开始,InnoDB 存储引擎开始支持全文索引。
全文检索(Full-Text Search)是将存储于数据库中的整本书或整篇文章中的任意内容信息查找出来的技术,它可以根据需要获得全文中有关章、节、段、句、词等信息,也可以进行各种统计和分析。
二、全文索引的实现?
全文索引通常使用倒排索引(inverted index)来实现。倒排索引和 B+ 树索引一样,也是一种数据结构。它在辅助表中存储了单词与单词自身在一个或多个文档中所在位置之间的映射。这通常利用关联数组来实现,其拥有两种表现形式:
- inverted file index,其表现形式为 {单词,单词所在文档的 ID}
- full inverted index,其表现形式为 {单词,(单词所在文档的 ID,在具体文档中的位置)}
InnoDB 存储引擎采用 full inverted index 的方式,将(DocumentId,Position)视为一个 “ilist”。因此在全文索引的表中,有两个列,一个是 word 字段,另一个是 ilist 字段,并且在 word 字段上设有索引。
另外,倒排索引还将 word 存放在一张表中,这个表就是 Auxiliary Table(辅助表),在 InnoDB 存储引擎中,共有 6 张 Auxiliary Table,存放在磁盘上,并且每张表根据 word 的 Latin-1(ISO8859-1)编码进行分区。
全文检索索引缓存(FTS Index Cache)是一个红黑树结构,其根据(word,ilist)进行排序,用来提高全文索引的性能。参数 innodb_ft_cache_size 用来控制 FTS Index Cache 的大小,默认值为 32M。
SHOW GLOBAL VARIABLES LIKE 'innodb_ft_cache_size'
对于 InnoDB 存储引擎而言,其总是在事务提交时将分词写入到 FTS Index Cache,然后通过批量写入到磁盘;当数据库关闭时,在 FTS Index Cache 中的数据会同步到磁盘上的 Auxiliary Table 中。
三、实战全文索引
CREATE TABLE `fts_a` (
`FTS_DOC_ID` bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT,
`body` text CHARACTER SET utf8 COLLATE utf8_general_ci NULL,
PRIMARY KEY (`FTS_DOC_ID`) USING BTREE,
FULLTEXT INDEX `idx_fts`(`body`)
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `fts_a` VALUES (1, 'hello welcome to mysql world');
FTS_DOC_ID 字段名固定,并且必须为 BIGINT UNSIGNED NOT NULL 类型,用来与 word 进行映射,如果没有手动创建该字段,InnoDB 引擎会自动创建并为其加上 Unique Index 索引。
通过 innodb_ft_aux_table 来查看分词对应的信息:
SET GLOBAL innodb_ft_aux_table ='test/fts_a';
SELECT * FROM information_schema.INNODB_FT_INDEX_TABLE;
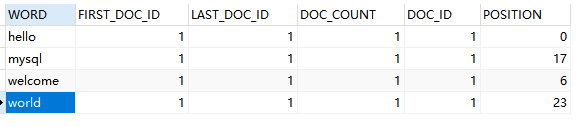
可以看到每个 WORD 都对应了一个 DOC_ID 和 POSITION。此外还记录了 FIRST_DOC_ID、LAST_DOC_ID 以及 DOC_COUNT,分别代表了该 WORD 第一次出现的文档 ID,最后一次出现的文档 ID,以及该 WORD 在多少个文档中存在。
MySQL 数据库支持全文检索(Full-Text Search)的查询,其语法为:
MATCH(col1,col2,…) AGAINST (expr[search_modifier])
search_modifier:
- IN NATURAL LANGUAGEMODE
- IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION
- IN BOOLEAN MODE
- WITH QUERY EXPANSION
EXPLAIN SELECT * FROM fts_a WHERE MATCH(body) AGAINST ('world' IN NATURAL LANGUAGE MODE)

四、其他
stopword 列表(stopword list)表示该列表中的 word 不需要对其进行索引分词操作。InnoDB 存储引擎有一张默认的 stopword 列表,其在 information_schema 架构下 INNODB_FT_DEFAULT_STOPWORD,默认共用 36 个 stopword。
SELECT * FROM information_schema.INNODB_FT_DEFAULT_STOPWORD
此外用户也可以通过参数 innodb_ft_server_stopword_table 来自定义 stopword 列表:
SHOW GLOBAL VARIABLES LIKE 'innodb_ft_server_stopword_table';
SET GLOBAL innodb_ft_server_stopword_table = '库/表';
当前 InnoDB 存储引擎的全文索引还存在以下的限制:
- 每张表只能有一个全文检索的索引;
- 由多个组合而成的全文索引列必须使用相同的字符集和排序规则;
- 不支持没有单词界定符(delimiter)的语言,如中文、日语、韩语等。