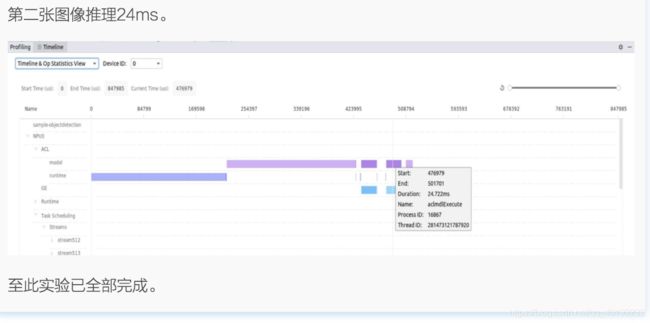
基于昇腾处理器的目标检测应用(ACL)
实验内容
本实验通过模型转換、数据预处理/络模型加载/推理/结果输出全流程屐示昇腾处理器推理应用开发过程,帮助您快速熟悉ACL这套计算加速库。
实验目标:
- 了解华为昇腾全栈开发工具 Mindstudio 及其离线模型转换功能
- 了解如何使用 ACL 开发基于华为昇腾处理器的神经网络推理应用
实验流程总览:
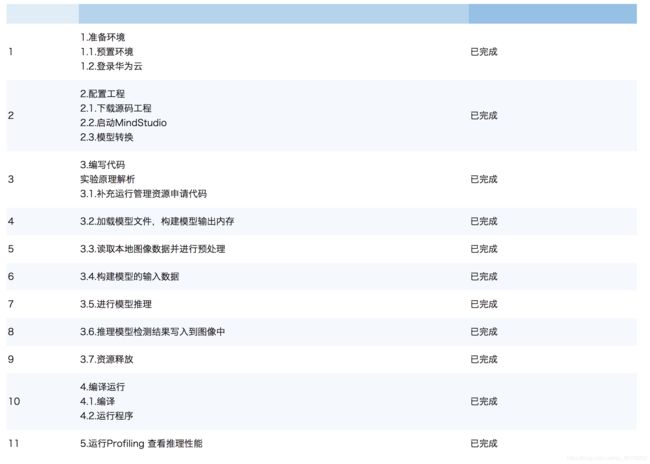
1.准备环境
1.1.预置环境
点击上方“预置实验环境”按钮,【约等待1-3分钟】后预置成功。环境预置会生成名称为“ecs-ai”弹性云服务器ECS,创建配置相关的VPC、弹性公网IP、安全组,并在“ecs-ai”上安装MindStudio开发工具并配置。
1.2.登录华为云
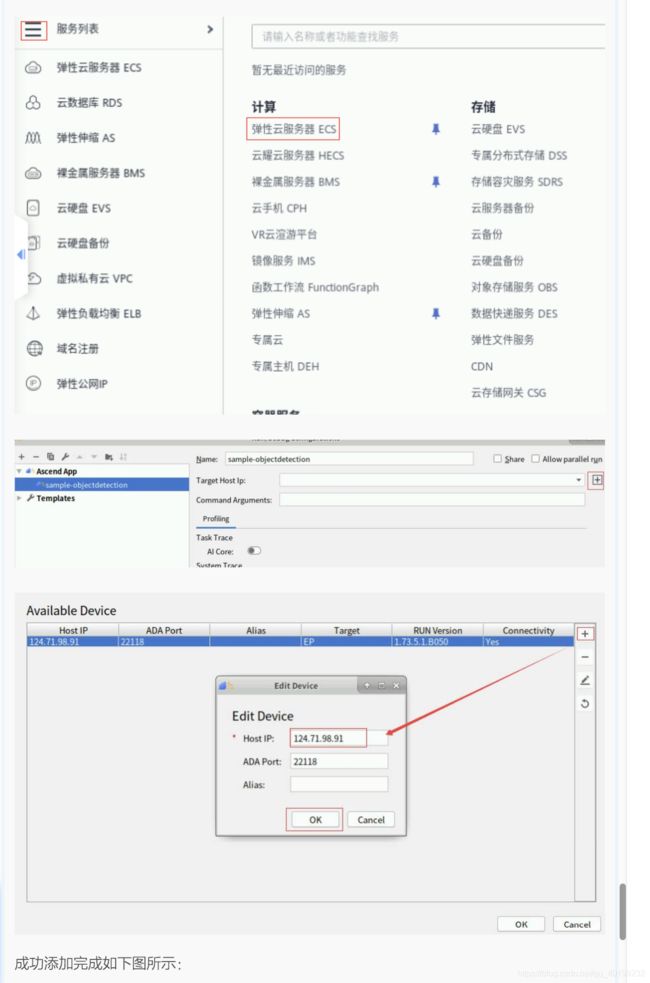
进入【实验操作桌面】,打开火狐浏览器进入华为云,点击“登录”进入,选择【IAM用户登录】模式,输入系统为您分配的华为云实验账号名、用户名和密码,登录华为云,登录华为云是为了创建ECS弹性云服务器资源(即运行环境),获得服务器的公网IP,这样在4.2步骤时,开发环境MindStudio可以用此公网IP连接到运行环境进行推理计算,如下图所示:
账号详见实验手册上方,切勿使用您自己的华为云账号登录
2.配置工程
2.1.下载源码工程切换至实验桌面,双击桌面的“Xfce终端”打开Terminal,执行以下命令创建并进入工程文件夹:
mkdir AscendProjects && cd AscendProjects
执行以下命令下载源码工程:
wget https://sandbox-experiment-resource-north-4.obs.cn-north-4.myhuaweicloud.com/shengteng-image-target/sample-objectdetection.zip
执行以下命令对工程文件解压:
unzip sample-objectdetection.zip
2.2.启动MindStudio输入以下命令启动“MindStudio”:
sh ../MindStudio-ubuntu/bin/MindStudio.sh
启动时可能出现误报错,无需操作,继续等待启动即可。保持当前命令行开启不要关闭。启动成功点击“Open project”,如下图所示:
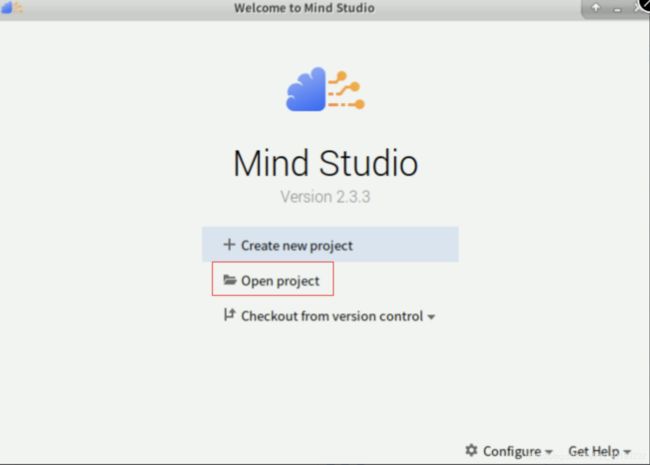
选择如下图所示的工程,点击“OK”。
加载完成如下图所示:
2.3.模型转换下载模型文件到相应目录。新打开一个“Xfce 终端”执行如下两条命令,将vdd_ssd模型下载至工程目录下:
wget -P /home/user/AscendProjects/sample-objectdetection/caffe_model/ https://sandbox-experiment-resource-north-4.obs.cn-north-4.myhuaweicloud.com/shengteng-image-target/vgg_ssd.caffemodel
wget -P /home/user/AscendProjects/sample-objectdetection/caffe_model/ https://sandbox-experiment-resource-north-4.obs.cn-north-4.myhuaweicloud.com/shengteng-image-target/vgg_ssd.prototxt
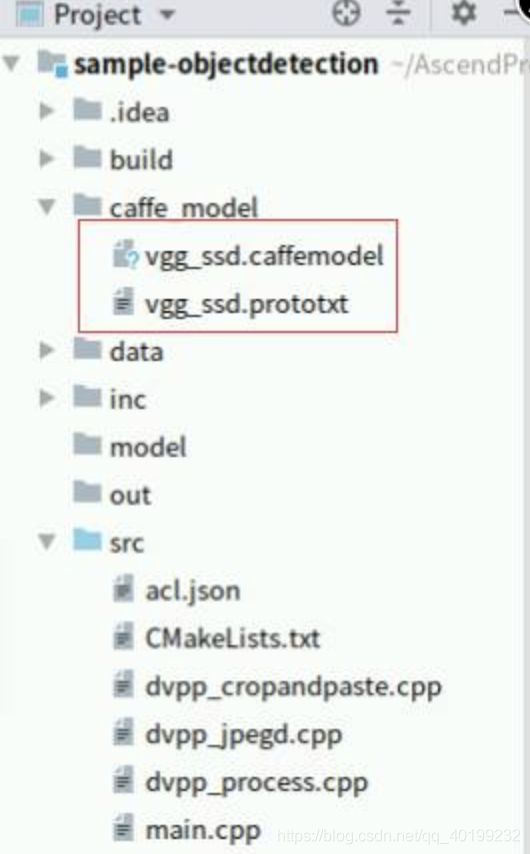
下载成功切换到“MindStudio”如下图所示:
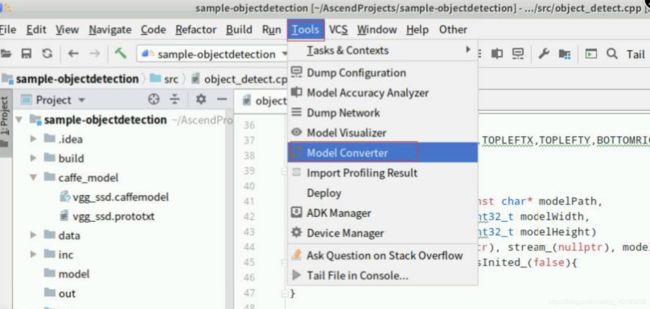
在MindStudio的菜单栏找到“Tools”->“Model Converter”打开模型转换界面,如下图所示:
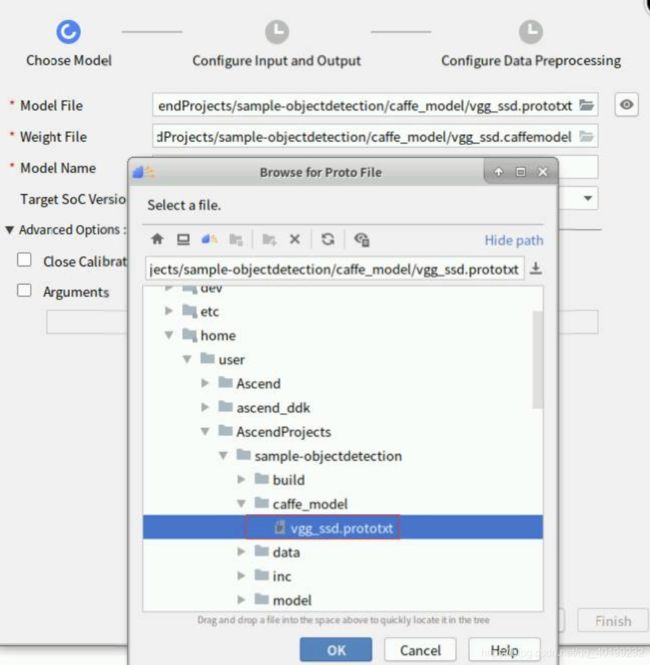
添加要转换的模型,如下图,选中文件夹“/home/user/AscendProjects/sample-objectdetection/caffe_model”下的vgg_ssd.prototxt文件,点击“OK”:
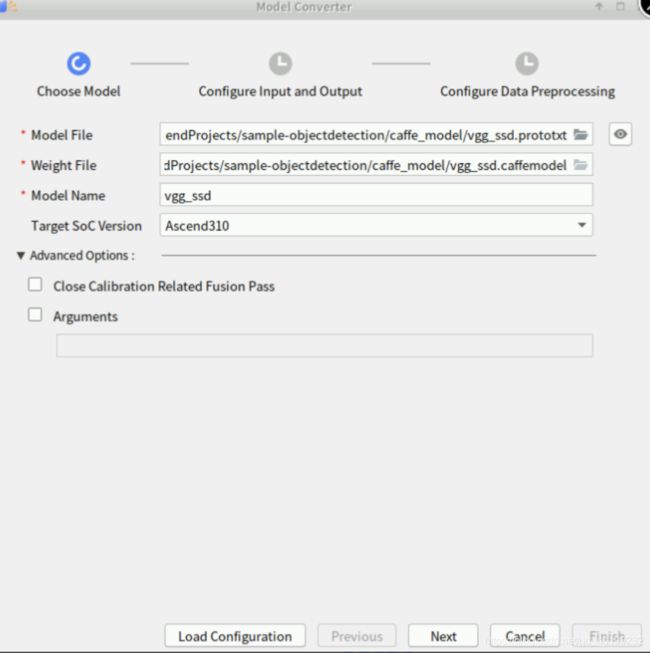
点击“Next”,页面参数默认,如下图所示:
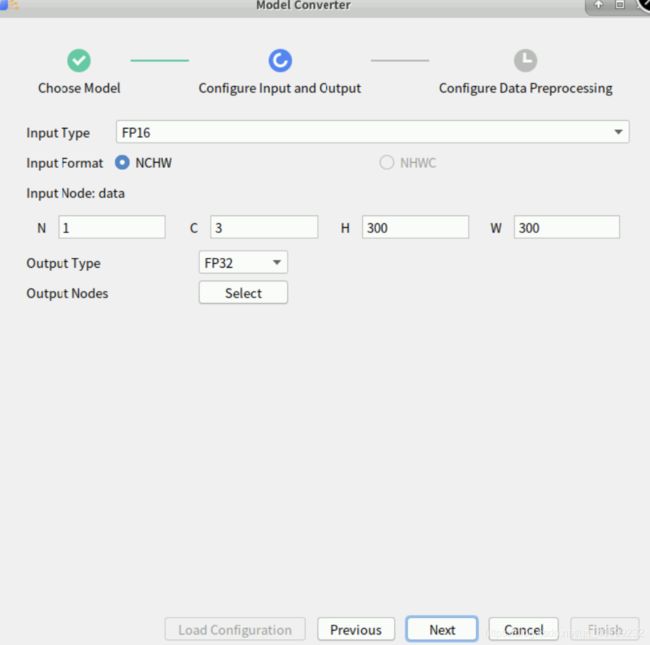
点击“Next”,打开图像预处理功能,可以帮我们做图像减均值,归一化和色域格式转换等操作。
相关配置参数说明: Input Image Format: 输入om模型的图片数据格式(选择YUV420SP)。 Input Image
Resolution: 描述输入图片的大小,若输入为YUV420SP:则要求(Input Image Resolution [W] )%16=0,即输入图片的宽与16对齐。
Model Image Format:描述模型处理的图片的格式,当输入图片格式与模型处理图片格式不同时需要开启,否则关闭,模型要求输入图像数据为BGR格式,与输入图像格式不同所以需要开启。
Crop: 抠图功能,设置抠图的开始位置和抠图的大小,抠图大小不支持修改默认为Input Node 即原始模型要求输入图片的宽高。
Mean: 每个通道要减的均值。 Variance: 每个通道的方差系数。
本工程中模型转换使用的配置参数具体如下图所示
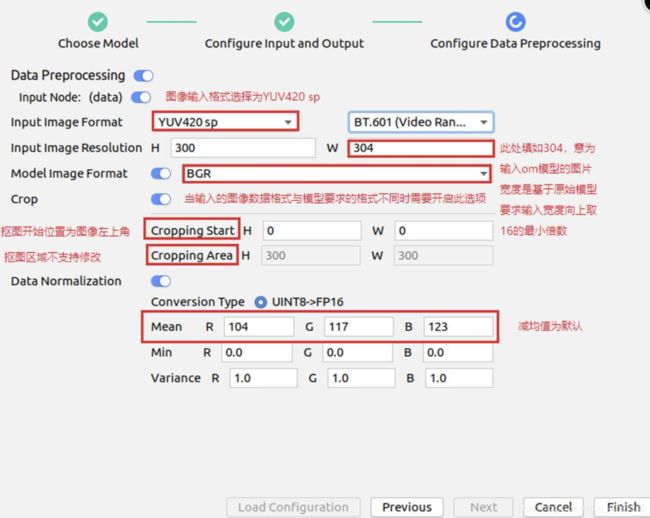
点击“Finish”进行转换,模型转换成功如下图所示:

切换到命令行终端,执行以下命令移动模型文件:
cp /home/user/modelzoo/vgg_ssd/device/vgg_ssd.om /home/user/AscendProjects/sample-objectdetection/model/
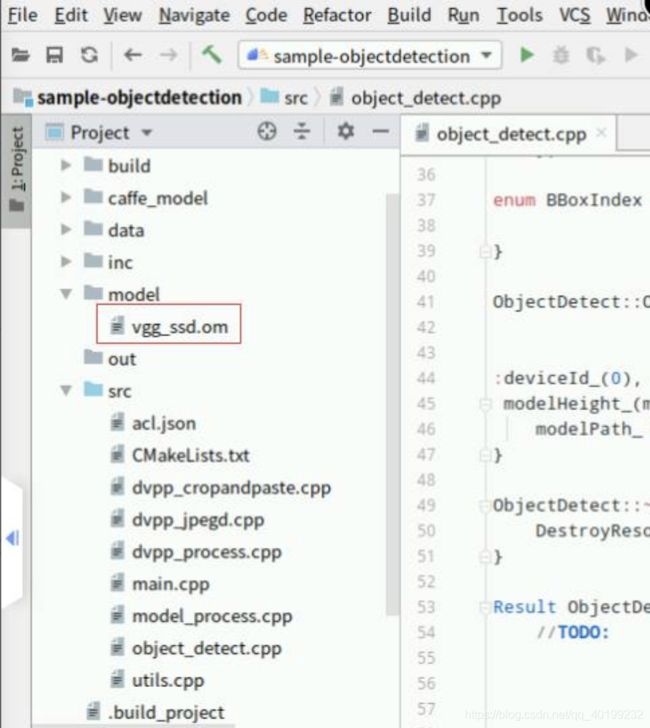
执行成功切回“MindStudio”可看到工程里面的模型文件,如下图所示:
3.编写代码
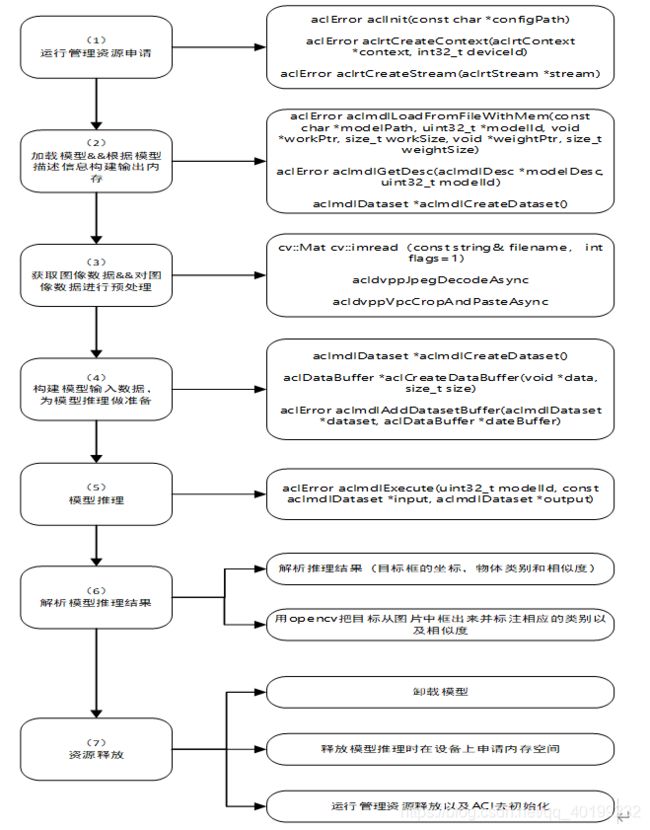
实验原理解析
常见问题解答原理概述
-
运行管理资源申请:用于初始化系统内部资源,固定的调用流程。
-
加载模型文件并构建模型输出内存:加载模型文件到内存中,并根据内存中加载的模型获取模型的基本信息包含模型输入、输出数据的数据buffer大小,据此基本信息构建模型输出内存,为接下来的模型推理做好准备。
-
获取本地图像数据并进行预处理:
基于对原始模型的理解,在图像预处理时DVPP和AIPP分工处理:
DVPP:1.解码:JPEG图片先解码为YUV420SP(输出128*16对齐) 2.图像缩放:cropandpast(300,304) 3.输出图像数据类型:Uint8AIPP:
1. 色域转换:YUV->BGR 2. 减均值 3. 抠出Crop(0, 0,300,300) 4. 图像数据类型转换:Uint8->FP16 (达芬奇推理的要求,模型最后实际的输入是fp16)) -
构建模型输入数据:将经过预处理后的图像数据通过ACL接口,构建模型的输入数据,详细的调用流程在代码编写环节进行详细说明。
-
进行模型推理:根据构建好的模型输入数据进行模型推理。
-
解析模型推理结果:根据模型输出,解析目标检测的结果,得到图像数据中检测到的目标框,检测到的物体类别以及相似度。使用opencv将检测的结果标注在图像上并写入本地文件中。
-
资源释放:程序运行结束时需要卸载模型,释放在设备侧申请的内存空间,对运行管理资源进行释放以及ACL去初始化。
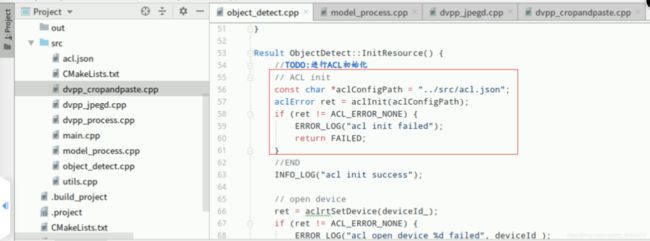
3.1.补充运行管理资源申请代码
复制以下代码,在Mind Studio的左侧栏找到源文件“object_detect.cpp”双击打开,在函数“ObjectDetect::InitResource”中找到如下图所示位置的【//TODO:】后回车下一行(文件第55行),添加如下代码,进行ACL初始化:
// ACL init
const char *aclConfigPath = "../src/acl.json";
aclError ret = aclInit(aclConfigPath);
if (ret != ACL_ERROR_NONE) {
ERROR_LOG("acl init failed");
return FAILED; }
添加成功,“Ctrl+s”保存,最终如下图所示:
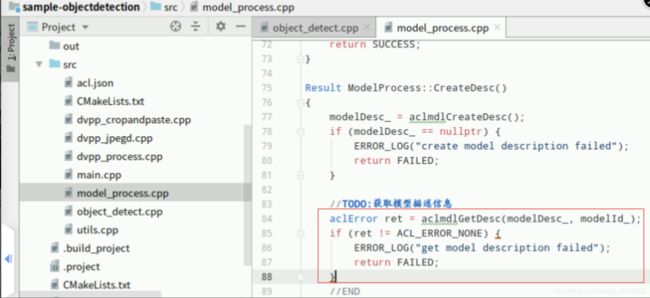
3.2.加载模型文件,构建模型输出内存
① 加载本地om模型文件到内存中复制以下代码,在Mind Studio的左侧栏找到源文件“model_process.cpp”双击打开,在函数“ModelProcess::LoadModelFromFileWithMem”中找到如下图所示位置的【//TODO:】后回车下一行(文件第63行),添加如下代码,加载本地模型文件,并获取已经加载成功的模型ID:
ret = aclmdlLoadFromFileWithMem(modelPath, &modelId_, modelMemPtr_, modelMemSize_, modelWeightPtr_, modelWeightSize_);
if (ret != ACL_ERROR_NONE) {
ERROR_LOG("load model from file failed, model file is s", modelPath);
return FAILED;}
添加成功,“Ctrl+s”保存,最终如下图所示:
③根据模型的描述信息,获取模型的输出个数,以及模型每路输出在设备上所需的空间大小。ACL接口中关于模型推理的输入/输出数据准备流程如下图所示: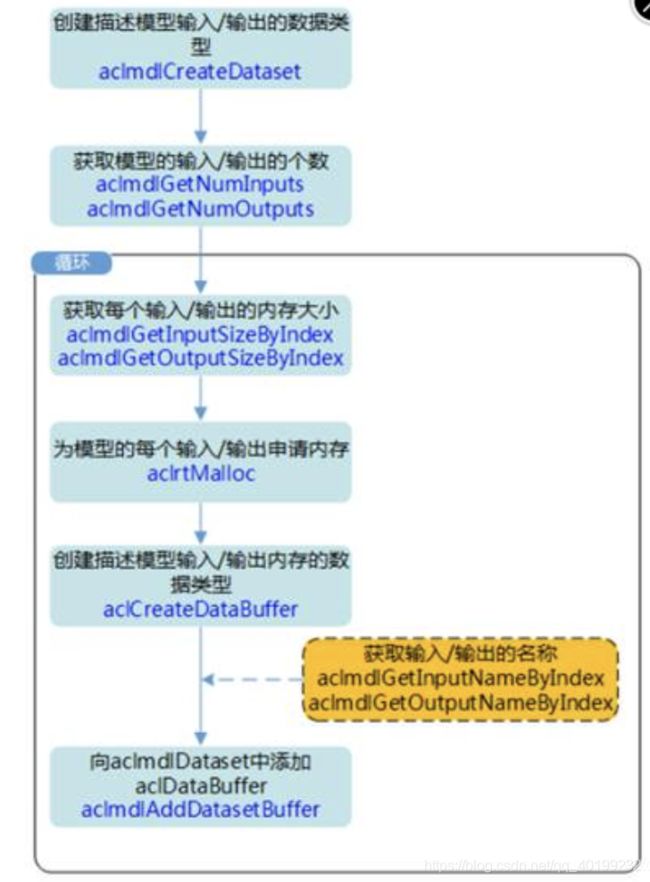
使用aclmdlDesc类型的数据描述模型基本信息(例如输入/输出的个数、名称、数据类型、Format、维度信息等),使用aclmdlDataset类型的数据描述模型的输入/输出数据,模型可能存在多个输入、多个输出,每个输入/输出的内存地址、内存大小用aclDataBuffer类型的数据来描述。
aclmdlDataset类型与aclDataBuffer类型的关系如下图所示:
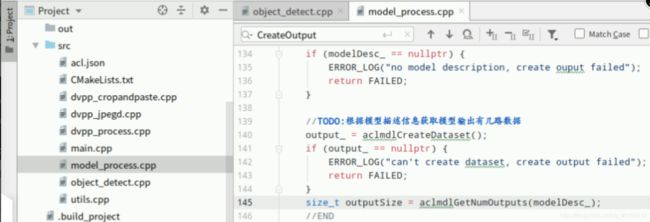
复制以下代码,在打开的源文件“model_process.cpp”中,在函数”ModelProcess::CreateOutput”中找到如下图所示位置的【//TODO:】后回车下一行(文件第140行),添加如下代码,获取aclmdlDataset类型的数据,并根据模型的描述信息,获取模型的输出有几路数据:
output_ = aclmdlCreateDataset();
if (output_ == nullptr) {
ERROR_LOG("can't create dataset, create output failed");
return FAILED;
}
size_t outputSize = aclmdlGetNumOutputs(modelDesc_);
添加成功,“Ctrl+s”保存,最终如下图所示:
复制以下代码,在打开的源文件“model_process.cpp”中,在函数”ModelProcess::CreateOutput”中找到如下图所示位置的【//TODO:】后回车下一行(文件第149行),添加如下代码,根据模型描述信息以及输出数据的下标值(即为第几路输出数据),获取模型每路输出数据所占内存字节大小:
size_t buffer_size = aclmdlGetOutputSizeByIndex(modelDesc_, i);
添加成功,“Ctrl+s”保存,最终如下图所示:

3.3.读取本地图像数据并进行预处理
复制以下代码,在Mind Studio的左侧栏找到源文件“dvpp_jpegd.cpp”双击打开,在函数“DvppJpegD::Process”找到如下图所示位置的【//TODO:】后回车下一行(文件第88行),添加如下代码,使用DVPP的JPEGD功能进行图片解码,将jpg格式的图像解码为YUV420sp格式的图像:
aclError aclRet = acldvppJpegDecodeAsync(dvppChannelDesc_, reinterpret_cast<void *>(imageDevice.data.get()),imageDevice.size, decodeOutputDesc_, stream_);
if (aclRet != ACL_ERROR_NONE) {
ERROR_LOG("acldvppJpegDecodeAsync failed, aclRet = d", aclRet);
return FAILED;}
添加成功,“Ctrl+s”保存,最终如下图所示: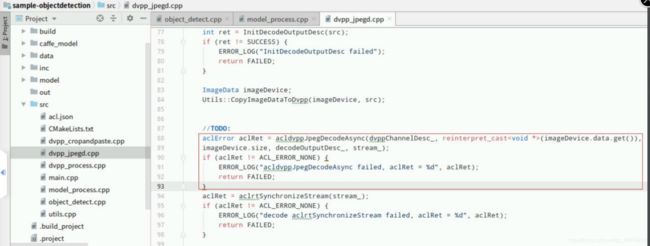
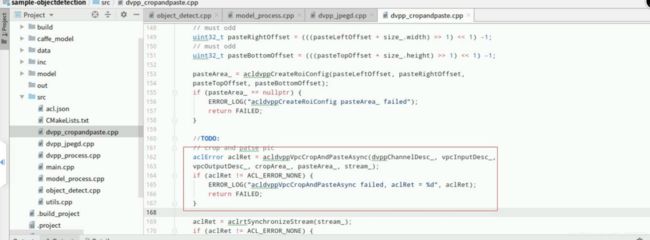
复制以下代码,在Mind Studio的左侧栏找到源文件“dvpp_cropandpaste.cpp”双击打开,在函数“DvppCropAndPaste::Proces”中找到如下图所示位置的【//TODO:】后回车下一行(文件第161行),添加如下代码,使用DVPP的VPC功能进行抠图和贴图,如果抠图区域的宽高和贴图区域的宽高不一致时会对图片自动进行一次缩放,贴图后的内存空间经过AIPP的Crop裁剪掉用于补齐的padding区域,作为om模型进行推理的输入:
// crop and patse pic
aclError aclRet = acldvppVpcCropAndPasteAsync(dvppChannelDesc_, vpcInputDesc_,vpcOutputDesc_, cropArea_, pasteArea_, stream_);
if (aclRet != ACL_ERROR_NONE) {
ERROR_LOG("acldvppVpcCropAndPasteAsync failed, aclRet = d", aclRet);
return FAILED;
}
添加成功,“Ctrl+s”保存,最终如下图所示:
3.4.构建模型的输入数据
构建模型的输入数据,为模型推理做准备。复制以下代码,在Mind Studio的左侧栏找到源文件“model_process.cpp”双击打开,在函数“ModelProcess::CreateInput”中找到如下图所示位置的【//TODO:】后回车下一行(文件第105行),添加如下代码,将模型的每路输入信息(包含描述输入图像数据的内存空间地址和相应大小)添加到aclmdDataset类型的数据input_中:
input_ = aclmdlCreateDataset();
if (input_ == nullptr) {
ERROR_LOG("can't create dataset, create input failed");
return FAILED;}aclDataBuffer* inputData = aclCreateDataBuffer(input, inputsize);
if (inputData == nullptr) {
ERROR_LOG("can't create data buffer, create input failed");
return FAILED;
}
添加成功,“Ctrl+s”保存,最终如下图所示: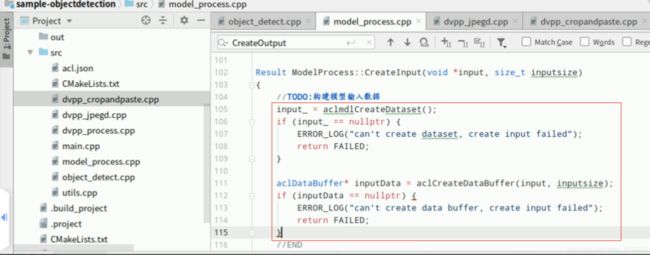
3.5.进行模型推理
复制以下代码,在打开的源文件“model_process.cpp”中,在函数“ModelProcess::Execute”中找到如下图所示位置的【//TODO:】后回车下一行(文件第208行),添加如下代码,根据已经加载到内存中,要进行推理的模型ID、构建好的模型推理输入数据,调用ACL库中模型推理接口进行模型推理:
aclError ret = aclmdlExecute(modelId_, input_, output_);
if (ret != ACL_ERROR_NONE) {
ERROR_LOG("execute model failed, modelId is u", modelId_);
return FAILED;
}
添加成功,“Ctrl+s”保存,最终如下图所示:
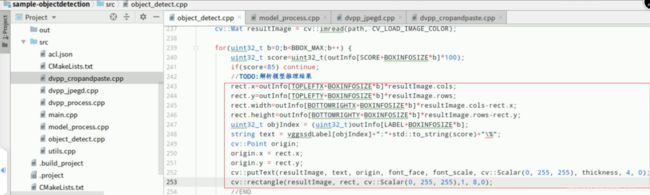
3.6.推理模型检测结果写入到图像中
复制以下代码,在Mind Studio的左侧栏找到源文件“object_detect.cpp”双击打开,在函数“ObjectDetect::Postprocess”中找到如下图所示位置的【//TODO:】后回车下一行(文件第243行),添加如下代码,解析出目标框的左上角坐标值、目标检测框的宽度和高度以及检测出的物体类别索引。并将检测结果通过opencv写入到图像中:
rect.x=outInfo[TOPLEFTX+BOXINFOSIZE*b]*resultImage.cols; rect.y=outInfo[TOPLEFTY+BOXINFOSIZE*b]*resultImage.rows; rect.width=outInfo[BOTTOMRIGHTX+BOXINFOSIZE*b]*resultImage.cols-rect.x;rect.height=outInfo[BOTTOMRIGHTY+BOXINFOSIZE*b]*resultImage.rows-rect.y;uint32_t objIndex = (uint32_t)outInfo[LABEL+BOXINFOSIZE*b];string text = vggssdLabel[objIndex]+":"+std::to_string(score)+""; cv::Point origin; origin.x = rect.x;origin.y = rect.y; cv::putText(resultImage, text, origin, font_face, font_scale, cv::Scalar(0, 255, 255), thickness, 4, 0); cv::rectangle(resultImage, rect, cv::Scalar(0, 255, 255),1, 8,0);
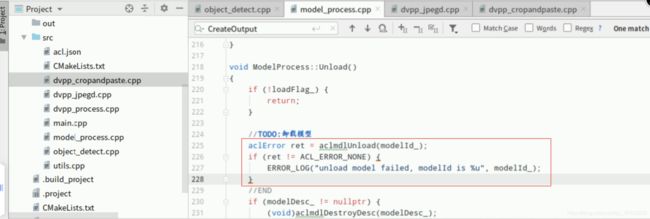
3.7.资源释放
复制以下代码,在Mind Studio的左侧栏找到源文件“model_process.cpp”双击打开,在函数“ModelProcess::Unload()”中找到如下图所示位置的【//TODO:】后回车下一行(文件第225行),添加如下代码,推理结束之后要卸载加载到内存中的模型:
aclError ret = aclmdlUnload(modelId_);
if (ret != ACL_ERROR_NONE) {
ERROR_LOG("unload model failed, modelId is u", modelId_);
}
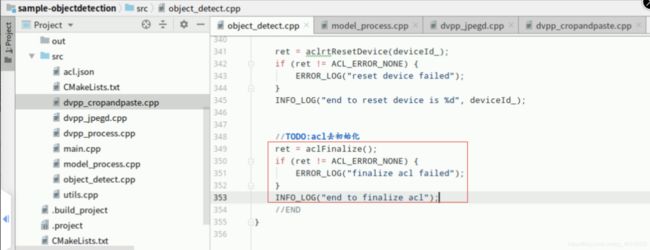
复制以下代码,在Mind Studio的左侧栏找到源文件“object_detect.cpp”双击打开,找到如下图所示位置的【//TODO:】后回车下一行(文件第349行),添加如下代码,对acl进行去初始化:
ret = aclFinalize();if (ret != ACL_ERROR_NONE) { ERROR_LOG("finalize acl failed");}INFO_LOG("end to finalize acl");
添加成功,“Ctrl+s”保存,最终如下图所示:

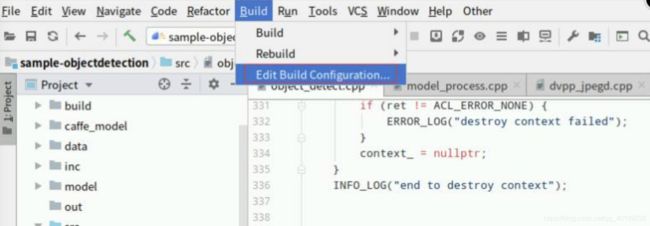
4.编译运行
4.1.编译添加完关键代码后,在MindStudio的顶部菜单栏点击“Build”->“Edit Build Configuration…”打开设置页面,如下图所示: