mysql索引知识点
先提前剧透:有4个知识点是极其重要的
1、创建索引的过程就是建B+树的过程,B+树中节点的值就是创建的索引
2、复合索引的B+树,叶子节点存储的是复合的索引字段与主键字段,主键字段是用于回表的
3、如果回表的次数过多,是不走索引的
4、如果没有where条件,select 索引字段的话,是走索引的,因为索引字段少的话,一页就能存储非常多行记录,这样页的数目就变少了,IO次数也就变少了,所以应该走索引,而不是全表扫描,全表扫描IO次数实在是太多了!!!结论:页的个数越少越好,因为页越多,就会使得B+树的结构发生较大的变化,会使得B+树的高度变高,而B+树的高度正是IO的次数
5、对索引进行操作,运算的sql语句,都不会走索引
6、主键ID插入的时候,要递增,不要乱序,因为乱序插入时,会使得B+树的页结构里面的行记录移动得非常大,这样插入效率就很低了!!而顺序插入的话,就只需要在后面依次的增加行记录
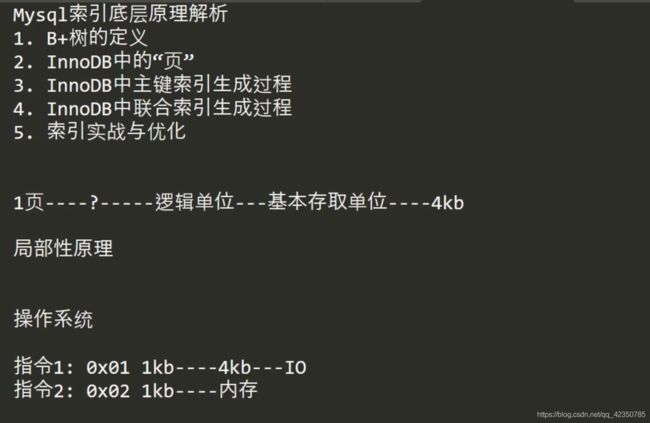
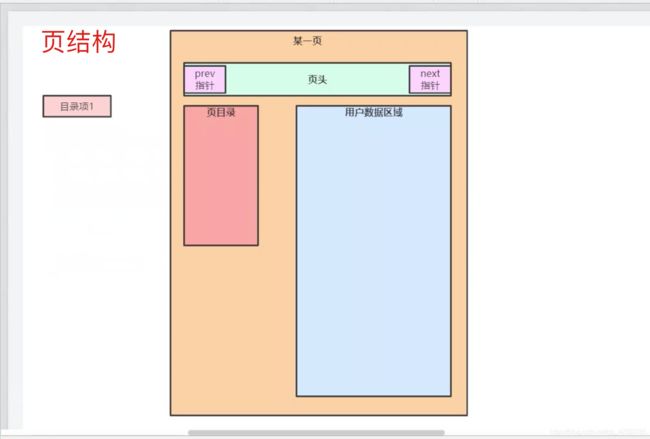
一页是16kb,而一行数据根据字段的大小来确定,就知道一页能存储多少行数据了 16kb / 4b = 4k 条数据了
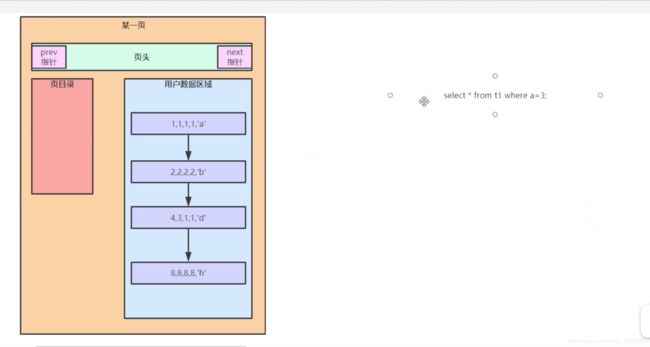
插入的时候,要按照主键的顺序来进行插入,所以效率就比较低了,之所以用这种低效率的插入方式,是为了便于查询,查询的时候就特别方便了
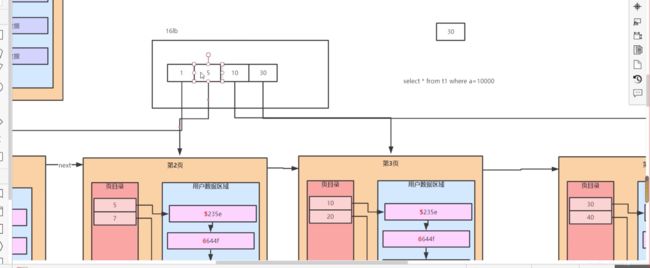
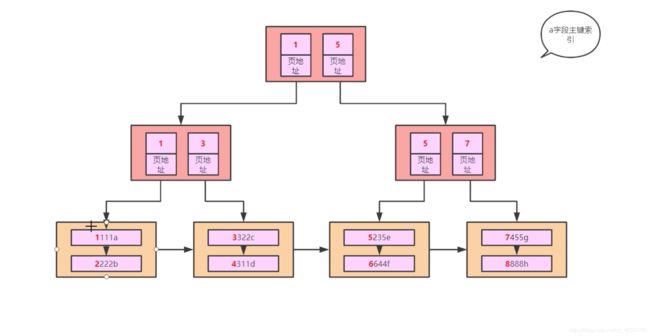


建一个索引,无论是何种索引,都会有一棵B+树出来,而且这个B+树的叶子节点还是根据这个索引用到的字段来进行排序的,所以说,建立一个索引,就会复制一张表出来
b,c,d 建立联合索引之后,就有一棵B+树出来了,这棵B+树的叶子节点是按照 b,c,d三个字段来进行排序的

上面那种建立B+树的方式是不可取的,原因有二:首先,如果叶子节点上面包含所以字段的值,那这样就相当于复制了整张表,如果整张表的数据量特别大,有几百万条,几千万条数据的话,那么复制整张表就会浪费大量的磁盘空间; 第二,如果你觉得叶子节点包含所有的字段太浪费磁盘空间,你就只保留建立索引的字段的话,这样select * from 表 where 的时候,你就只能查询到索引的字段了,其它的非索引字段就无法查询到了

注意注意:如果回表的次数太多,甚至接近于整张表的记录数,那么就还不如全表扫描呢,不走索引了
create index idx_t1_bcd on t1(b,c,d);
-- 这条sql语句是不走索引的,因为回表的次数太多了
explain select * from t1 where b>1;


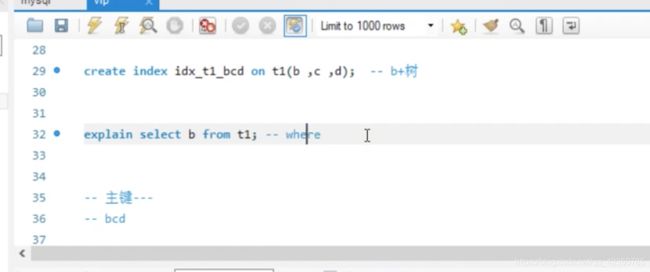
create index idx_t1_bcd on t1(b,c,d); -- 建立索引,就会建立一棵b+树
explain select * from t1 where c=1 and d=1;--这是不会走索引的

判断一下,下面四种情况会不会走索引?
-- a是int类型的主键 b,c,d是int类型的,
-- e是varchar类型的,e字段是索引
explain select * from t1 where a=1;
explain select * from t1 where a='1';
explain select * from t1 where e='1';
explain select * from t1 where e=1;
结论1:数字与字符串进行比较的时候,字符串是低人一等的,它需要转换为数字才能与真正的数字进行比较!!
结论2:所有对索引进行改变的操作,都不会走索引!!!索引时一个字段啊,你如果对索引进行了运算,或者其他的一些操作,那如果根据索引进行查询,就会对这个索引字段里面的所有数据都要进行运算,这个工程量实在是太大了,那还不如全表扫描呢!!走啥索引
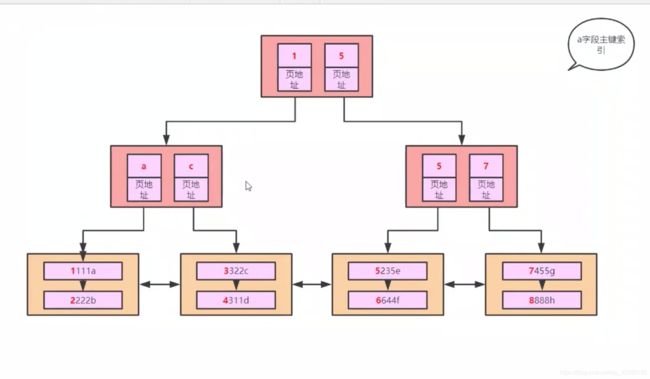
例如上图中,按照主键建立的B+树,如果对主键进行了运算,那么上图B+树中的所有节点,都要进行运算,这个工程量实在是吓人,那我就还不如全表扫描呢,不走索引,全表扫描还更快些!!!
根据上面两个结论,我们就知道,下面这条sql是必然走索引的
explain select * from t1 where a=1;
下面这条sql也是会走索引的,因为不需要索引去转换
explain select * from t1 where a='1';
下面这条sql 必然会走索引
explain select * from t1 where e='1';
下面这条sql 不会走索引,因为需要索引e的字段里面的数据全部进行转换,太麻烦了
explain select * from t1 where e=1;
同样如果是这样的sql语句,也是无法走索引的,因为对索引a进行了运算
explain select * from t1 where a + 1 = 2;