面向基于英特尔® 架构的平台的实时端到端 H.265/HEVC 解决方案
目录
1. 摘要
2. 简介
2.1 视频编解码器和 H.265/HEVC
2.2 HEVC 性能问题
2.3 当前 H.265/HEVC 解决方案调查
3. 基于 IA 的平台上的优化实时解决方案
3.1 基于英特尔® 至强™ 处理器的实时 HEVC 编码器解决方案
3.1.1 针对 HEVC 编码函数调优的英特尔 SIMD 矢量化
3.1.2 线程并发和核心可扩展性调优
3.1.3 使用 SMT/HT 进一步调优
3.2 基于英特尔® 酷睿™ 处理器的平台的高性能 H.265/HEVC 编码器
3.2.1 Strongene HEVC 编码器的优化和性能分析
3.2.2 英特尔 SSE 优化的视骏 HEVC 解码器与同类开源产品之比较以及未来优化机遇
3.3 在基于英特尔® 凌动™ 处理器的平台上优化 H.265/HEVC 编码器
3.3.1 使用 YASM 与英特尔 ® C++ 编译器进行优化
3.3.2 使用英特尔® 流式单指令多数据扩展(英特尔® SSE)指令进行优化
3.3.3 使用英特尔® 线程构建模块(英特尔® TBB)工具进行优化
3.3.4 H.265/HEVC 编码器性能比较
4. 总结
5. 其他相关文章
参考文献
作者简介
1. 摘要
国际电信联盟(ITU)发布了新的视频编解码标准: High Efficiency Video Coding (HEVC)/H.265,据声称新标准比目前的 H.264/MPEG-4 标准的效率高 50%。 但是,其算法的复杂程度和 H.265 的数据结构是 H.264 的 4 倍。 这便意味着,基于 H.265 的编解码器比上一代需要更多的计算资源/能力。 本文中,我们将调查 HEVC 编解码字符并优化基于 CPU 的软件转码技术,从而提供最佳的视频质量和最灵活的编程模式。 我们的端到端解决方案可在 HEVC 编解码器上最大化英特尔® 架构(IA)平台的功能,并实现实时性能。
2. 简介
视频编码标准主要通过大众熟悉的 ITU-T 和 ISO/IEC 标准的开发演进而来。 ITU-T 制定的 H.261 和 H.263,ISO/IEC 制定的 MPEG-1 和 MPEG-4 Visual,以及这两个组织联合制定的 H.262/MPEG-2 Video 和 H.264/MPEG-4 高级视频编码(AVC)标准[1]。
去年推出的 H.265/HEVC(高效视频编码)是 ISO / IEC 和 ITU-T 推出的最新视频编解码器标准,旨在最大程度地提高压缩能力和降低数据损失。 H.265/HEVC 的压缩率是上一个 H.264/AVC 标准的 2 倍,但是可以提供相同的主观质量。 HEVC 技术是下一代视频编解码器解决方案,可帮助在线视频提供商在占用更少带宽的情况下提供高质量的视频。
2.1 视频编解码器和 H.265/HEVC
HEVC 为获得高效率的编码标准提出多个新的视频编码语法架构和算法[1][2]:
a) 随机存取和位流剪接功能
全新设计支持随机存取和位流剪接的特殊功能。 在 H.264/MPEG-4 AVC 中,位流必须始终从 IDR 访问单元开始,但是在 HEVC 中,支持随机存取。
b) 树形编码单元结构
每个图像可划分为多个树形编码单元(CTU),每个单元包括亮度树形编码数据块(CTB)和色度 (CTB)。 L 的值可能等于 16、32 或 64,具体由序列参数集(SPS)中指定的编码语法元素决定。 CTU 包含四叉树算法,该算法支持根据 CTB 覆盖的区域的信号特征将编码块(CB)划分为指定的适当尺寸。 以前所有的视频编码标准仅使用固定阵列尺寸 16×16 亮度样本,但是 HEVC 支持根据编码器对内存和计算的需求指定尺寸可变的 CTB。
c) 按照树形结构划分为转换数据块和单元
CB 能够以递归的方式划分为转换数据块(TB)。 分区由一个剩余四叉树表示。 与以前的标准相比,HEVC 设计支持一个 TB 跨多个预测块(PB)处理图像间预测编码单元(CU),从而最大限度地提高四叉树结构 TB 划分的潜在编码效率优势。
d) 图像内预测
包含 33 种不同方向的方向预测适用于尺寸从 4×4 至 32×32 的(正方形)转换数据块(TB)。 预测方向可以是 360 度任意方向。 HEVC 支持多种图像内预测编码方法,如 Intra_Angular、Intra_Planar 和 Intra_DC。
这种高级的编码标准需要客户端设备和后端转码服务器具备非常高的处理能力。
2.2 HEVC 性能问题
当前的 HEVC 测试模型(HM)项目[6]仅可实施该标准的主要功能;实际性能尚未生产并在实际中部署。 该项目的两大主要缺点是:

图 1. HM 项目分析 – 线程并发

图 2. HM 项目分析 – 热代码
在服务器端上,该 HEVC 编码器消耗的 CPU 资源是 H.264 的 100 倍;在客户端上,是 10 多倍。
2.3 当前 H.265/HEVC 解决方案调查
H.265/HEVC 编解码器吸引了全球许多企业/代理优化性能并在实际中部署。 涉及的开源项目包括:
我们运行了一个 720p 24 FPS 视频,以评估基于英特尔® 至强™ 处理器的平台上 x.265 编码器的性能(速率为 2.70GHz 的 E5-2680,8*2 物理内核,代号: Sandy Bridge)。 该编解码器的实施者采取了大量措施来优化任务和数据并行度的初始标准;但是,在我们的基准测试中,它在采用 32 个逻辑内核的系统中只能使用 6 个内核(SMT ON)。 因此,它无法在当前的多核平台上最大限度地利用计算资源。

图 3. X.265 项目 CPU 使用

图 4. 采用英特尔® SIMD 调优的 X.265 项目
在 x.265 项目中,采用了英特尔® SSE 指令执行矢量调优,这可将性能加速 70% 以上。 随着英特尔® C 编译器进一步优化编译,我们在 IA 架构上的性能能够提高 2 倍1。 但是,此处的编码器性能仍然与实时编码器部署有一段差距,尤其对于 HD 1080p 视频。
在中国,超过 20 加多媒体 ISV 购买可用的 HEVC 解决方案和平台,以节约在线视频服务成本并确保提供高质量的视频。

图 5. 中国的在线视频市场
3. 基于 IA 的平台上的优化实时解决方案
视骏是一家以内核视频编码技术为主的中国企业。 它提供了高级 H.265/HEVC 编码器/解码器,该技术被用于迅雷在线视频服务。 其编码器/解码器解决方案集成了开源 FFMPEG,以便 ISV 使用。 我们与视骏联手利用全新的基于 IA 的平台技术来优化采用英特尔® 至强™ 处理器、英特尔® 酷睿™ 处理器和英特尔® 凌动™ 处理器的平台上的 H.265/HEVC 编码器和解码器,以实现实时、端到端的 HEVC 编解码器解决方案。
3.1 基于英特尔® 至强™ 处理器的实时 HEVC 编码器解决方案
我们的视频编码应用是一种标准的 CPU 和内存密集型工作负载,它需要较高的服务器平台能力,如内核计算效率、可靠性和稳定性。 H.265/HEVC 编解码器的计算复杂度是以前的 H.264/MPEG 的 4 倍。 它对后端服务器平台提出了前所未有的处理要求。 在本部分,我们将介绍能够帮助视骏 HEVC 编解码器达到 1080p 实时编码标准主要的基于 IA 的技术。
3.1.1 针对 HEVC 编码函数调优的英特尔 SIMD 矢量化
大部分耗时的视频和图像处理函数是基于数据块的数据密集型计算,它可使用英特尔® SIMD(单指令多数据)矢量化指令进行优化。 英特尔 SIMD 指令可处理一个 CPU 循环中的多个数据集的数据,这能够极大地提高数据吞吐率和执行效率。 英特尔 SIMD 适用的平台非常广泛,从 MMX、英特尔® SSE、英特尔® 高级矢量扩展指令集(英特尔® AVX),到可在多代 x86 平台上使用的英特尔® 高级矢量扩展指令集 2(英特尔® AVX2)。
根据对分析数据的观察,在视骏编码器中,所有的主要热函数均可使用英特尔 SSE 指令进行矢量化处理,如低复杂度的动作补偿帧插值、免转置的整数转化、蝶形 Hadamard 变换以及内存冗余最少的 SAD/SSD 计算。 我们支持在基于英特尔至强处理器的平台上使用英特尔 SSE 指令,如图 6 所示。
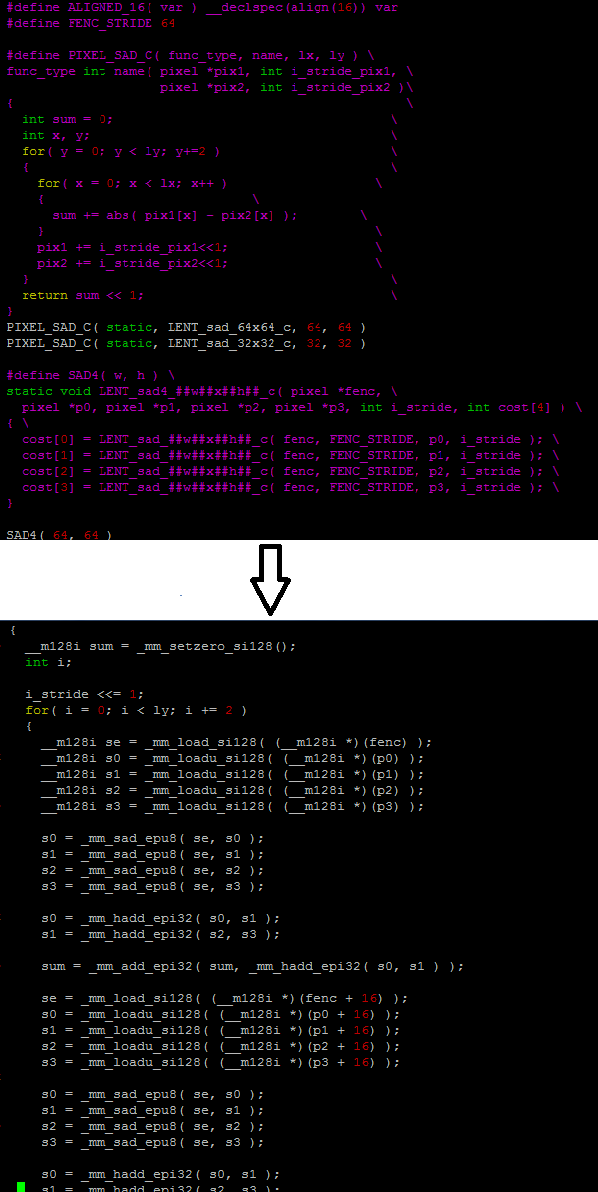
图 6. 在视骏编解码器上支持英特尔® SIMD/SSE 指令的样本
借助这些英特尔 SIMD 编程模型和算法,视骏重新编写了编码器中的所有热函数,以最大限度地提升性能。 图 7 是我们在标准 1080p HEVC 编码场景中的分析数据,它显示出,60% 的热函数使用英特尔 SIMD 指令运行。

图 7. 视骏编码函数的分析结果
采用 256b int 计算的英特尔 AVX2 指令的性能将达到以前的 128b 英特尔 SSE 代码的 2 倍。 2014 年推出后,英特尔 AVX2 将可在基于英特尔至强处理器的平台(代号:Haswell)上使用。 我们以常见的 64*64 模块 SAD 计算为例对英特尔 AVX2 的基本性能进行了测试:
表 1 英特尔® SSE 和英特尔® AVX2 实施结果
| CPU 周期 | 初始 | 英特尔® SSE | 英特尔® AVX2 |
|---|---|---|---|
| run 1 | 98877 | 977 | 679 |
| run 2 | 98463 | 1092 | 690 |
| run 3 | 98152 | 978 | 679 |
| run 4 | 98003 | 943 | 679 |
| run 5 | 98118 | 954 | 678 |
| avg. | 98322.6 | 988.8 | 681 |
| speedup | 1.00 | 99.44 | 144.38 |
如表 1 所示,在该函数中,英特尔 SSE 和英特尔 AVX2 指令能够将性能提升 100 倍,而且英特尔 AVX2 代码能够进一步改进性能,使其比英特尔 SSE 高 40%2。 当在将要发布的 Haswell 平台上将英特尔 SSE 代码升级至英特尔 AVX2 时,我们能够对性能做出进一步提升。
3.1.2 线程并发和核心可扩展性调优
如我们在第 2、3 部分看到的内容所示,大部分目前的实施并未利用多核平台上的全部内核。 根据最新的英特尔至强多核架构,以及基于 HEVC 和 CTB 的算法之间明确的并行度依赖性,视骏计划使用 Inter-Frame Wave-front (IFW) 并行框架替换最初的 OWF (Overlapped Wave-Front) 和 WPP (Wave-front Parallel Processing) 方法,然后开发一个包含三个等级的线程管理方案,以确保 IFW 能够充分利用所有的 CPU 内核加速 HEVC 加密流程。 借助这款新的并行度框架,基于一个 Ivy Bridge 平台(英特尔至强处理器 E5-2697 @2.70GHz,12*2 物理内核,SMT OFF),视骏编解码器能够利用 18-24 个物理内核的计算资源,实现出色的线程并发性能。

图 8. 视骏编码器中的线程并发和 CPU 利用
借助全新的 WHP 并行度框架以及分别在任务级别和数据级别完全实施的英特尔 SIMD 指令,视骏编码器能够针对 1080p 视频序列大幅提升 x86 处理器的性能,利用所有内核计算能力,如图 8 所示。
3.1.3 使用 SMT/HT 进一步调优
同步多线程(SMT),也成超线程(HT)技术,可广泛适用于所有基于 IA 的平台。 它支持操作系统从每个物理内核映射两个虚拟或逻辑内核,并在可能时在两个内核之间共享资源。 超线程的主要功能是减少流水线上依赖指令的数量。 它可在 CPU 内核从高级别完全运行时提供性能优势,但是,并非所有的应用都能够获得优势,如无法利用所有内核的应用便无法获得。 在这些情况下,SMT 技术将带来任务/线程切换开销。 因此,我们关闭了视骏编码器平台上的 SMT,并在 Ivy Bridge 平台(英特尔至强处理器 E5-2697 v2)上使用 HEVC 1080p 视频实时编码标准,如下表标黄内容。
表 2 基于英特尔® 至强™ 处理器的平台上的视骏 HEVC 编码性能3
大幅提升性能后,我们进一步对视骏 HEVC 编码器在 Ivy Bridge 平台上的能力进行了评估,主要关注带宽和质量方面的问题。
表 3 H.264 和 H.265 编解码器性能比较
| 文件: BQTerrance_1920x1080_60.yuv 分辨率: 1920x1080 大小: 1869Mbyte,622080 kbps 平台: E5-2697 v2 @2.70GHz,RAM 64GB DDR3-1867,QPI 8.0 GT /s OS/SW: Red Hat 6.4,kernel 2.6.32,gcc v4.4.7,ffmpeg v2.0.1,Lentoid HEVC Encoder r2096 linux |
编解码器 | 大小(字节) | 速率(kbps) | PSNR_Y/U/V (db) |
| H.264 | 12254696 | 4078.1 | 32.311/39.369/42.043 | |
| H.265 | 6215615 | 2064.28 | 34.016/39.822/42.141 |
从表 3 中,我们看到 H.265/HEVC 编解码器能够在保持相同视频质量的同时节省 50% 的带宽4。
3.2 基于英特尔® 酷睿™ 处理器的平台的高性能 H.265/HEVC 编码器
视骏 HEVC/H.265 解码器是一款优化的 H.265 解码器,可在所需计算能力相对较低的情况下提供较高的性能。 视骏 HEVC 解码器高效性的实现是通过完全并行的架构设计和 Wavefront Parallel Processing(WPP)的实施。 此外,它还采用了适用于基于英特尔酷睿处理器的平台(如英特尔 SSE2、英特尔 SSE3 和英特尔 SSE4)的英特尔 SIMD 指令来加速多种解码块和发掘底层英特尔架构的能力。 借助这些特性的优势,视骏 HEVC 解码器能够在主流 CPU 上实现实时 4K 解码性能,并为 1080p 视频流提供高达 200 FPS 的解码率。
3.2.1 视骏 HEVC 解码器的优化和性能分析
视骏 HEVC 解码器中的多线程优化通过 WPP 和帧层并行性来实现。 WPP 是 HEVC 中实现并行处理的一种功能,其实现方式是,将一部分划分为多行树形编码单元(CTU),然后将每一行分配至每个线程(每一行可在上一行的参考 CTU 解码后进行处理)。 视骏 HEVC 解码器中的帧级别并行度可利用 HEVC 标准中采用的层级结构,因为在构建层级参考架构时 B 帧之间能够相互参考。 例如,如果图像组(GOP)等于 8,则该序列可按照如下方式编码:
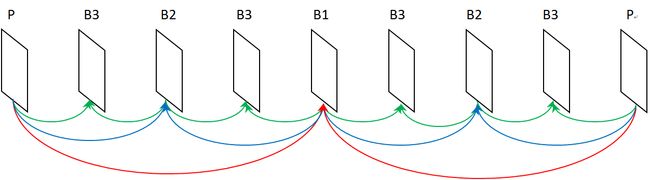
图 9. 当 GOP = 8 时,可利用帧层并行性的编码帧结构(显示顺序)
在本案例中,在第一阶段,B1 使用 2 P 帧作为参考。 在第二阶段中,两个 B2 帧使用一个 P 帧和一个 B1 帧作为参考。 因此,这两个 B2 帧可进行并行处理。 在第三阶段中,四个 B3 帧使用一个 P 帧和一个 B2 帧,或一个 B1 帧和一个 B2 帧作为参考。 因此,四个 B3 帧也可进行并行处理。 如果使用了更大的 GOP,帧层并行性可以进一步提升,因为 HEVC 解码器中的线程数量足以支持 B 帧同时解码。 视骏 HEVC 解码器的设计能够通过多线程解码和 WPP 提升解码速度,从而实现最高的并行性。
以下是英特尔 SSE 在 Sandy Bridge 平台5(运行于 1080p 和 4K 序列,启用了不同数量的线程)上优化前(表 4)后(表 5),视骏 HEVC 解码器的最大解码帧速率。
表 4 英特尔 SSE 在 1080p 和 4K 视频流上优化(Lentoid C)并启用不同数量的线程前,视骏 HEVC 解码器的解码速率
| 1080p 1.2Mbps | 4K 5.6Mbps | |||
| 不包含 渲染的解码速率(FPS) |
CPU 平均利用率 |
不包含 渲染的解码速率(FPS) |
CPU 平均利用率 |
|
| 1 条线程 | 25.33 | 25% | 6.85 | 25% |
| 2 条线程 | 43.03 | 49% | 11.8 | 47% |
| 4 条线程 | 51.79 | 93% | 14.13 | 86% |
| 8 条线程 | 53.1 | 98% | 15.03 | 99% |
表 5 英特尔 SSE 在 1080p 和 4K 视频流上优化(v2.0.1.14)并启用不同数量的线程后,视骏 HEVC 解码器的解码速率
| 1080p 1.2Mbps | 4K 5.6Mbps | |||
| 不包含 渲染的解码速率(FPS) |
CPU 平均利用率 |
不包含 渲染的解码速率(FPS) |
CPU 平均利用率 |
|
| 1 条线程 | 75 | 25% | 21 | 25% |
| 2 条线程 | 120 | 45% | 33 | 40% |
| 4 条线程 | 140 | 70% | 36 | 63% |
| 8 条线程 | 154 | 98% | 40 | 96% |
从上述数据中我们可以看到,英特尔 SSE 在 Sandy Bridge 平台上优化5后,1080p 流的性能可提升 3 倍,4K 流的性能约可提升 2.6 倍。 此外,相比单线程模式,视骏 HEVC 解码器中的多线程设计提升性能的能力明显更高: 如果同步解码线程的数量从 1 提高到 8,解码帧速率约可提升 2 倍。 它显示,在整体性能方面,即使在双核 Sandy Bridge 移动平台上,带有英特尔 SSE 优化的视骏 HEVC 解码器能够实时解码 4K 流,且 CPU 利用率低于 40%;毫无疑问,它绝对是业内最佳的 HEVC 软件解码器。 对于比特率范围在 1Mbps 至 3Mbps(通过互联网传输的 1080p 视频的一般比特率设置)之间的 1080p 流,可以达到实时解码,且 CPU 利用率低于 20%。
3.2.2 英特尔 SSE 优化的视骏 HEVC 解码器与同类开源产品之比较以及未来优化机遇
你可以通过对比一些知名的开源实施,如 HM 和 FFMPEG,对视骏 HEVC 解码器的性能进行进一步检验。 下表中,使用分辨率、帧和比特率各异的视频流对不同 HEVC 解码器的解码速率进行了比较。
HM10.0: HEVC 参考解码器 HM10.0
FFMPEG: 单线程上运行的 FFMPEG 2.1 HEVC 解码器
FFMPEG 4 线程: 四线程上运行的 FFMPEG 2.1 HEVC 解码器
Lentoid C: SSE 优化前基于单线程的视骏 HEVC 解码器
Lentoid SIMD: SSE 优化后基于单线程的视骏 HEVC 解码器(v2.0.1.16)
Lentoid SIMD 4 线程: SSE 优化后基于 4 线程的视骏 HEVC 解码器(v2.0.1.16)

图 10. 各种解码器和配置下 4K 视频的 H.265 解码帧速率

图 11. 各种解码器和配置下 A 类视频的 H.265 解码帧速率

图 12. 各种解码器和配置下 B 类视频的 H.265 解码帧速率
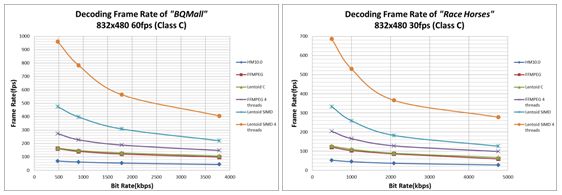
图 13. 各种解码器和配置下 C 类视频的 H.265 解码帧速率
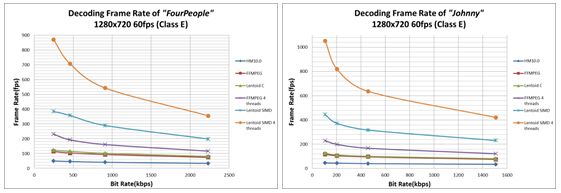
图 14. 各种解码器和配置下 E 类视频的 H.265 解码帧速率

图 15. 各种解码器和配置下 F 类视频的 H.265 解码帧速率
根据各类视频的性能数据,在英特尔 SSE 优化后,视骏 HEVC 解码器比 HM10 解码器的加速性能快 10 倍6。 其比特率流更低,但性能提升更高。 但是,当比特率上时,英特尔 SSE 优化(Lentoid SIMD 4 线程 / Lentoid C)的加速比率将会下降,因为英特尔 SIMD 指令在能够并行的模块(如运动补偿)上的作用更大,而在不能并行的模块(CABAC、IDCT 和解块(deblocking))上的作用更小。 如果我们观察一下英特尔 SSE 优化前后 VTune™ Amplifier XE 热点函数,便能够对该现象有更加具体的了解:

图 16. 从 VTune™ Amplifier 的角度来看,运行在 4K 5.6Mbps 工作负载上的视骏 HEVC 解码器在英特尔 SSE 优化前(Lentoid C 8 线程)的热点函数

图 17. 从 VTune™ Amplifier 的角度来看,运行在 4K 5.6Mbps 工作负载上的视骏 HEVC 解码器在 SSE 优化后(Lentoid SIMD 8 线程)的热点函数
在图 16 中,我们发现 Lentoid C 解码器中的大部分热点出现在运动补偿(MC)模块中,因为 MC 必须在每个 CTB 中完成,且需要大量的计算资源。 但是,MC 能够在 CTB 级别并行,因此,当英特尔 SSE 优化后,它能够实现最高的加速比率:
![]()
随着比特率增加,为解码和处理视频数据,需要在 CABAC、IDCT 和解块中使用更多的计算资源,从而使这些模块的英特尔 SSE 加速比率更低。 这就是英特尔 SSE 优化后,热点函数从 MC 迁移至 IDCT 和解块模块的原因,如图 17 所示。
除此之外,从 VTune 的 CPU 并发中我们可以看到,当在 4K 5.6Mbps 上在 8 线程流中运行英特尔 SSE 优化的解码器时,3 个以上的逻辑 CPU 需要 74% 的解码时间,仅 1 个或 2 个逻辑 CPU 需要 26% 的时间,因为 B 帧之间的工作负载不平衡。

图 18. CPU 使用率直方图
对于热点分析,前五个热点函数实际上均与计算而非内存绑定,这意味着,这些函数可通过英特尔 AVX 和英特尔 AVX2 指令进行进一步优化。

图 19. 重要热点
3.3 在基于英特尔® 凌动™ 处理器的平台上优化 H.265/HEVC 编码器
观看视频是移动设备的首要用途。 多媒体处理需要密集的计算,且对电池寿命和用户体验有重要影响。 移动设备上的 LCD 分辨率从 480p 提高到 720p,现已提高到 1080p。 最终用户希望看到高品质的视频,但是对于在线视频提供商(优酷、爱奇艺、乐视)而言,购买网络宽带的费用逐年攀升。
2013 年,英特尔推出全新的基于第 4 代英特尔凌动处理器的平台(代号 Bay Trail),该平台采用 22 纳米 Silvermont 架构。 该架构的详情如下所示:
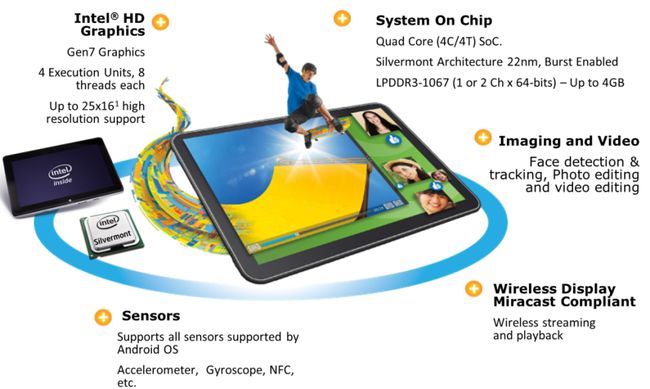
图 20. Bay Trail 平台简介
我们使用了英特尔 VTune 工具来调试视骏 H.265/HEVC 解码器。 然后,我们使用了工具集(详见以下三部分内容)对其进行了优化。 我们在基于英特尔凌动处理器的平台上获得了超高的解码速度和较低的 CPU 并发。
3.3.1 使用 YASM 与英特尔 ® C++ 编译器进行优化
我们没有使用默认的 Android* 编译器来编译开源 FFMPEG 中的优化的 ASM 汇编码,而使用了 YASM 和英特尔® C++ 编译器。
YASM 在“全新的” BSD 许可下对 NASM 汇编器进行了完全重写,它能够在 x86 平台上重复使用英特尔 SIMD 优化的 ASM 汇编码。 开发人员可通过以下链接下载并安装 YASM 编译器:http://yasm.tortall.net。 如要使用它,请在编译 FFMPEG 前修改 configure.sh 文件,以启用 YASM 和 ASM 选项,如下所示:

图 21. 修改 FFMPEG 配置文件
此外,我们还鼓励 ISV 使用英特尔 C++ 编译器来编译原生代码。
3.3.2 使用英特尔® 流式单指令多数据扩展(英特尔® SSE)指令进行优化
使用英特尔 VTune 工具进行调试,我们发现,视骏编解码器仅使用了 C 代码来实现 YUV2RGB,这并未达到最佳性能。
基于英特尔凌动处理器的平台支持英特尔 SSE 指令代码,包括 MMX、MMXEXT、英特尔 SSE、英特尔 SSE2、英特尔 SSE3、英特尔 SSSE3 和英特尔 SSE4。 在开源 FFMPEG 中启用英特尔 SSE 代码能够大幅提升 YUV2RGB 性能。
我们使用 MMX EXT 代码在 FFMPEG 中打开英特尔 SSSE3 编译器选项,详见以下代码片段。

图 22. 在 FFMPEG 中支持英特尔® SSE 代码
Bay Trail 平台可支持英特尔 SSE 4.1 指令,从而对 H.265/HEVC 解码器进行优化以实现更出色的性能。
3.3.3 使用英特尔® 线程构建模块(英特尔® TBB)工具进行优化
当我们运行 VTune 工具时,我们发现了视骏编解码器创建了四个线程。 但是,在创建理想内核时,最快的线程需要等待最慢的线程。
如果单独使用,英特尔 SSE 只能在单个内核上使用。 将英特尔 TBB 与英特尔 SSE 结合使用能够让代码在多核上运行,从而实现更高的性能。
为执行多任务,我们对多线程代码进行了修改,然后使用英特尔 TBB 将任务分配至闲置内核,以便充分利用多内核。
您可通过以下链接下载英特尔 TBB:http://threadingbuildingblocks.org/download。

图 23. YUV 转 RGB 之比较数据
使用英特尔 TBB 进行优化能够将性能提升 2.6 倍7。
3.3.4 H.265/HEVC 解码器性能比较
此外,我们还可启用 OpenGL* 进行渲染,因为通过测试我们发现,使用 YASM 和 英特尔 C++ 编译器进行优化能够将性能提升 1.5 倍, 使用英特尔 SSE 进行优化能够将性能提升 6 倍(相比 C 代码),使用英特尔® TBB 能够将性能提升 2.6 倍8。
我们使用了英特尔® 图形性能分析器(英特尔® GPA)来测试播放视频时的刷新率。 当使用优化的 H.265/HEVC 解码器在 Bay Trail 平板电脑上进行测试时,播放 HEVC 1080p 视频的刷新率可达到 90 FPS(帧每秒),而 Clover Trail+ 平板电脑可达到 40 FPS。
图 24. Clover Trail+/ Bay Trail 平板电脑的性能比较
如果我们在 Bay Trail 平板电脑上将刷新率设置为 24 FPS,当播放 1080p 视频时,CPU 工作负载将低于 25%。 因此,我们为中国的大众在线视频提供商隆重推荐视骏 HEVC 解码器解决方案,以推广其业务。
4. 总结
未来十年,H.265/HEVC 将有可能成为最普遍的视频标准。 目前,许多媒体应用和产品正在准备购买 HEVC 支持。 本文中,我们在采用全新 IA 平台技术的英特尔平台上实施了一款基于 CPU 、实时、端到端的 HEVC 解决方案。 基于英特尔处理器的高级解决方案已在迅雷[4] 在线视频和产品中进行部署,并将加速 H.265/HEVC 技术产品和部署。
5. 其他相关文章
参考资料
[1] 高效视频编码(HEVC)标准概述,IEEE 会报:视频技术电路和系统,卷 22,编号 12,2012 年 12 月。
[2] 高效率视频编码(HEVC)文本规格草案 10,JCTVC-L1003_v34
[3] http://www.strongene.com/en/homepage.jsp
[4] http://yasm.tortall.net
[5] http://threadingbuildingblocks.org
[6] http://hevc.hhi.fraunhofer.de/
作者简介
1 性能测试中使用的软件和工作负载可能仅在英特尔® 微处理器上针对性能进行了优化。 SYSmark* 和 MobileMark* 等性能测试均使用特定的计算机系统、组件、软件、操作和功能进行测量。 上述任何要素的变动都有可能导致测试结果的变化。 请参考其他信息及性能测试(包括结合其他产品使用时的运行性能)以对目标产品进行全面评估。
配置: 采用 32GB DDR3-1333 内存的英特尔® 至强™ 处理器 [email protected],基于 HEVC 编解码器的视频转码工作负载,作者:YANG LU。 如欲了解更多信息,请访问:http://www.intel.com/content/www/cn/zh/library/benchmarks.html
2 性能测试中使用的软件和工作负载可能仅在英特尔® 微处理器上针对性能进行了优化。 SYSmark* 和 MobileMark* 等性能测试均使用特定的计算机系统、组件、软件、操作和功能进行测量。 上述任何要素的变动都有可能导致测试结果的变化。 请参考其他信息及性能测试(包括结合其他产品使用时的运行性能)以对目标产品进行全面评估。
配置: 采用 64GB DDR3-1867 内存的英特尔® 至强™ 处理器 E5-2697 v2 @2.70GHz,基于视骏 HEVC 编解码器的视频转码工作负载,作者:YANG LU。 如欲了解更多信息,请访问:http://www.intel.com/content/www/cn/zh/library/benchmarks.html
3 性能测试中使用的软件和工作负载可能仅在英特尔® 微处理器上针对性能进行了优化。 SYSmark* 和 MobileMark* 等性能测试均使用特定的计算机系统、组件、软件、操作和功能进行测量。 上述任何要素的变动都有可能导致测试结果的变化。 请参考其他信息及性能测试(包括结合其他产品使用时的运行性能)以对目标产品进行全面评估。
配置: 采用 64GB DDR3-1867 内存的英特尔® 至强™ 处理器 E5-2697 v2 @2.70GHz,基于视骏 HEVC 编解码器的视频转码工作负载,作者:YANG LU。 如欲了解更多信息,请访问:http://www.intel.com/content/www/cn/zh/library/benchmarks.html
4 性能测试中使用的软件和工作负载可能仅在英特尔® 微处理器上针对性能进行了优化。 SYSmark* 和 MobileMark* 等性能测试均使用特定的计算机系统、组件、软件、操作和功能进行测量。 上述任何要素的变动都有可能导致测试结果的变化。 请参考其他信息及性能测试(包括结合其他产品使用时的运行性能)以对目标产品进行全面评估。
配置: 采用 64GB DDR3-1867 内存的英特尔® 至强™ 处理器 E5-2697 v2 @2.70GHz,基于视骏 HEVC 编解码器的视频转码工作负载,作者:YANG LU。 如欲了解更多信息,请访问:http://www.intel.com/content/www/cn/zh/library/benchmarks.html
5 性能测试中使用的软件和工作负载可能仅在英特尔® 微处理器上针对性能进行了优化。 SYSmark* 和 MobileMark* 等性能测试均使用特定的计算机系统、组件、软件、操作和功能进行测量。 上述任何要素的变动都有可能导致测试结果的变化。 请参考其他信息及性能测试(包括结合其他产品使用时的运行性能)以对目标产品进行全面评估。
配置: 采用 4GB 内存和 Windows* 7 操作系统的基于英特尔® 酷睿™ 处理器 i5-2520M 的 PC,解码帧速率和 CPU 利用率,Finn Wong]。 如欲了解更多信息,请访问:http://www.intel.com/content/www/cn/zh/library/benchmarks.html
6 性能测试中使用的软件和工作负载可能仅在英特尔® 微处理器上针对性能进行了优化。 SYSmark* 和 MobileMark* 等性能测试均使用特定的计算机系统、组件、软件、操作和功能进行测量。 上述任何要素的变动都有可能导致测试结果的变化。 请参考其他信息及性能测试(包括结合其他产品使用时的运行性能)以对目标产品进行全面评估。
配置: 采用 8GB 内存和 Windows* 7 操作系统的基于英特尔® 酷睿™ 处理器 i7-2600 的 PC,各种解码器和配置的解码帧速率,Finn Wong]。 如欲了解更多信息,请访问:http://www.intel.com/content/www/cn/zh/library/benchmarks.html
7 性能测试中使用的软件和工作负载可能仅在英特尔® 微处理器上针对性能进行了优化。 SYSmark* 和 MobileMark* 等性能测试均使用特定的计算机系统、组件、软件、操作和功能进行测量。 上述任何要素的变动都有可能导致测试结果的变化。 请参考其他信息及性能测试(包括结合其他产品使用时的运行性能)以对目标产品进行全面评估。
配置: 采用 2GB 内存和 Android 4.2 的英特尔® 凌动™ Bay Trail 平板电脑 FFRD8,解码帧速率,Songyue Wang]。 如欲了解更多信息,请访问:http://www.intel.com/content/www/cn/zh/library/benchmarks.html
8 性能测试中使用的软件和工作负载可能仅在英特尔® 微处理器上针对性能进行了优化。 SYSmark* 和 MobileMark* 等性能测试均使用特定的计算机系统、组件、软件、操作和功能进行测量。 上述任何要素的变动都有可能导致测试结果的变化。 请参考其他信息及性能测试(包括结合其他产品使用时的运行性能)以对目标产品进行全面评估。
配置: 采用 2GB 内存和 Android 4.2 的英特尔® 凌动™ Bay Trail 平板电脑 FFRD8,解码帧速率,Songyue Wang]。 如欲了解更多信息,请访问:http://www.intel.com/content/www/cn/zh/library/benchmarks.html