JAVA & 自建工具类 & xml文件解析工具
一、什么是xml文件?
1.百度定义:
可扩展标记语言,标准通用标记语言的子集,简称XML。是一种用于标记电子文件使其具有结构性的标记语言。
(Extensible Markup language 翻译 即为 可扩张标记语言)
1必须有声明语句。
XML声明是XML文档的第一句,其格式如下
<?xml version="1.0" encoding="UTF-8"?>
2.具体介绍
百度百科–xml文件介绍
3.示例
第一种格式:
<?xml version="1.0" encoding="UTF-8"?>
<students>
<student>
<id>001</id>
<name>李白</name>
<sex>男</sex>
<hobbies>
<hobby>吃酒</hobby>
<hobby>作诗</hobby>
<hobby>喜欢孟浩然</hobby>
</hobbies>
<introduce>仰天大笑出门去,我辈岂是蓬蒿人</introduce>
</student>
<student>
<id>002</id>
<name>杜甫</name>
<sex>男</sex>
<hobbies>
<hobby>春日忆李白</hobby>
<hobby>冬日有怀李白</hobby>
<hobby>梦李白</hobby>
</hobbies>
<introduce>白也诗无敌,飘然思不群</introduce>
</student>
</students>
基本格式是
<标签名> 内容<\标签名> 。且id,name,sex等其父标签是student.
第二种形式
<?xml version="1.0" encoding="UTF-8"?>
<students>
<student id = "001" name = "李白" sex = "男">
<hobbies>
<hobby>吃酒</hobby>
<hobby>作诗</hobby>
<hobby>喜欢孟浩然</hobby>
</hobbies>
<introduce>仰天大笑出门去,我辈岂是蓬蒿人</introduce>
</student>
...
</students>
这里id , name sex类似键值对存在,可以看成是studen标签的属性。
二、如何处理xml文件?
目前沙漏知道4种xml文件的解析方法。当然目前只熟悉一个,还对一些步骤无法解释清楚(惭愧)。当然,沙漏目前也只是写一写运用。有所长进时,再来修改。
沙漏习惯于使用第二种格式的xml文件。简单些,不啰嗦。
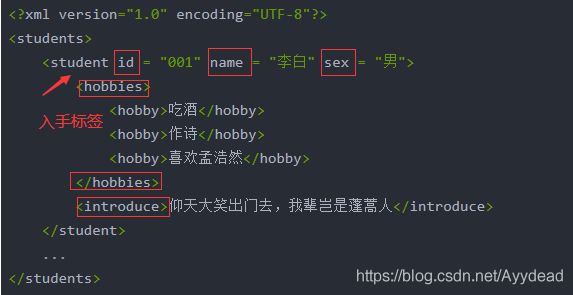
student是入手的标签,然后将 id, name, sex 等归为同一类型,属性的解析。使用getAttribute
将hobbies, introduce 当成同一类文本类解析,使用getTextContent()。
public class Demo {
public static void main(String[] args) {
try {
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
InputStream is = Class.class.getResourceAsStream("/students.xml");
Document document = db.parse(is);
NodeList studList = document.getElementsByTagName("student");
for (int index = 0; index < studList.getLength(); index++) {
Element student = (Element) studList.item(index);
String id = student.getAttribute("id");
String name = student.getAttribute("name");
String sex = student.getAttribute("sex");
System.out.println("编号:" + id);
System.out.println("姓名:" + name);
System.out.println("性别:" + sex);
System.out.print("爱好:");
NodeList hobbyList = student.getElementsByTagName("hobby");
for (int i = 0; i < hobbyList.getLength(); i++) {
Element hobbyTag = (Element) hobbyList.item(i);
String hobby = hobbyTag.getTextContent();
System.out.println( "\t" + hobby);
}
NodeList introducelList = student.getElementsByTagName("introduce");
String introduce = introducelList.item(0).getTextContent().trim();
System.out.println("简介:"+introduce);
System.out.println("");
}
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
结果如下:
 具体讲解看下面。
具体讲解看下面。
三、工具之制作
如何制作该工具的?就需要明确解析文件设计了哪些步骤。这些步骤,哪些是制式的?可以提前准备,装进工具里。
哪些是需要工具使用者加入后来的元素?
这样看来,那么如何制造工具,似乎有些眉目了。
1.一些准备
 文件地址是后来使用者提供的。我们无法定死。但似乎这个"db"很重要,且无关具体文件内容。
文件地址是后来使用者提供的。我们无法定死。但似乎这个"db"很重要,且无关具体文件内容。
private static DocumentBuilder db;
//步骤一
//这里使用静态块,是因为静态块在第一次实例化该对象时被执行,以后不再执行。而本地块每次实例化时都执行。
static {
try {
db = DocumentBuilderFactory.newInstance().newDocumentBuilder();
} catch (ParserConfigurationException e) {
e.printStackTrace();
}
}
2.调用未来的值–值传递
虽然我们不知道文件路径和需要解析的标签名是啥,作为制作工具,我们可以假设自己知道。然后借助这个“已知条件”来实现解析
给予文件地址加解析文件
//步骤二,使用者调用该函数,给予路径,解析文件
public static Document openXmlPath(String xmlPath) {
InputStream is = Class.class.getResourceAsStream(xmlPath);
try {
return db.parse(is);
} catch (SAXException e) {
e.printStackTrace();
return null;
} catch (IOException e) {
e.printStackTrace();
return null;
}
}
public void parserTag(Document document, String tagName) {
NodeList nodeList = document.getElementsByTagName(tagName);
for (int index = 0; index < nodeList.getLength(); index++) {
Element node = (Element)nodeList.item(index);
parserElement(node, index);//具体解析未完成
}
}
public void parserTag(Element parent, String tagName) {
NodeList nodeList = parent.getElementsByTagName(tagName);
for (int index = 0; index < nodeList.getLength(); index++) {
Element node = (Element)nodeList.item(index);
parserElement(node, index);//具体解析未完成
}
}
}
3.调用未来的方法 – 抽象类
没错,我们将文件解析了。但是我们无法知道用户需要如何显示标签内容。这就是未来使用者的操作。在C语言里,需要使用就是指向函数的指针。但是在JAVA中,抽象类就可以解决。
public abstract void parserElement(Element element, int index);
这里是实现这里的功能(如图)

 index 是为了处理同一名字的标签。
index 是为了处理同一名字的标签。
完整代码:
public abstract class XMLParser {
private static DocumentBuilder db;
//步骤一
static {
try {
db = DocumentBuilderFactory.newInstance().newDocumentBuilder();
} catch (ParserConfigurationException e) {
e.printStackTrace();
}
}
public XMLParser() {
}
//步骤二,使用者调用该函数,给予路径,解析文件
public static Document openXmlPath(String xmlPath) {
InputStream is = Class.class.getResourceAsStream(xmlPath);
try {
return db.parse(is);
} catch (SAXException e) {
e.printStackTrace();
return null;
} catch (IOException e) {
e.printStackTrace();
return null;
}
}
//步骤三,根据便签名具体解析(待实现的方法)
public abstract void parserElement(Element element, int index);
public void parserTag(Document document, String tagName) {
NodeList nodeList = document.getElementsByTagName(tagName);
for (int index = 0; index < nodeList.getLength(); index++) {
Element node = (Element)nodeList.item(index);
parserElement(node, index);
}
}
public void parserTag(Element parent, String tagName) {
NodeList nodeList = parent.getElementsByTagName(tagName);
for (int index = 0; index < nodeList.getLength(); index++) {
Element node = (Element)nodeList.item(index);
parserElement(node, index);
}
}
}
使用工具:
public static void main(String[] args) {
new XMLParser() {
@Override
public void parserElement(Element element, int index) {
String id = element.getAttribute("id");
String name = element.getAttribute("name");
String sex = element.getAttribute("sex");
System.out.println("编号:" + id);
System.out.println("姓名:" + name);
System.out.println("性别:" + sex);
System.out.print("爱好:");
new XMLParser() {
@Override
public void parserElement(Element element, int index) {
String hobby = element.getTextContent();
System.out.println("\t" +(index+1) +"."+ hobby);
}
}.parserTag(element, "hobby");
new XMLParser() {
@Override
public void parserElement(Element element, int index) {
String introduce = element.getTextContent().trim();
System.out.println("简介:"+ introduce);
}
}.parserTag(element, "introduce");;
System.out.println("");
}
}.parserTag(XMLParser.openXmlPath("/students.xml"),"student");;
}
这只是xml解析的一种格式。还有其他3种解析方式。所以文章未完待续。