Understanding Linux Network Internals
一、 简介
- 1 基本术语
- 1.1 本书常用的缩写
- 2 引用计数
- 2.1 引用计数函数
- 3 垃圾回收
- 3.1 异步
- 3.2 同步
- 4 函数指针
- 4.1 缺点
- 5 goto语句
- 5.1 使用环境
- 6 捕捉bug
基本术语
- 八个位的量通常称为八位组(octet), 本书使用最常见的术语字节(byte).
- 术语向量(vector)和数组(array)是交互替换使用的。
- 在上下文中, 术语“入口数据(ingress)"和”输入数据(input)“会交互使用,
“出口数据(egress)"和”输出数据(output)“也一样。
本书常用的缩写
| 缩写 | 意义 |
|---|---|
| L2 | 链路层(如ethernet) |
| L3 | 网络层(如ip) |
| L4 | 传输层(如tcp/udp/icmp) |
| BH | 下半部(Bottom Half) |
| IRQ | 中断(事件) |
| RX | 接收 |
| TX | 发送 |
引用计数
引用计数函数
- 递增函数: xxx_hold()
- 递减函数: xxx_release()
有时候,释放函数被称为xxx_put(),例如net_device结构的释放函数为dev_put().
垃圾回收
内核不用虚拟内存,直接使用物理内存。
异步
定时扫描,把那些可以释放的数据结构释放掉。
常见的准则:释放引用计数为0或null的数据结构。
同步
当内存不足的情况下,直接触发垃圾回收,不用等待同步机制。
函数指针
- 执行一个函数指针之前,必须先检查其值。避免使用为null的函数指针。
if (dev->init && dev->init(dev) != 0 ) { ... }
缺点
缺点:使阅读代码稍显困难。
goto语句
使用环境
- 用于处理函数内的不同返回代码。
- 用于跳出一层以上的循环嵌套。
捕捉bug
- BUG_ON(): 参数为真时,打印错误消息,然后内核panic.
- BUG_TRAP(): 参数为真时, 内核会打印出警告消息。
二、 关键数据结构
- 1 套接字缓冲区: sk_buff结构
- 1.1 网络选项及内核结构
- 1.2 结构说明及操作函数
- 2 net_device结构
- 2.1 MTU
- 2.2 结构说明及操作函数
套接字缓冲区: sk_buff结构
网络选项及内核结构
一般而言,任何引起内核数据结构改变的选项(如把tc_index字段添加到sk_buff结构),都不适合编译成一个模块。
结构说明及操作函数
sk_buff的成员解释及操作函数可查看linux kernel sk_buff。
net_device结构
MTU
Ethernet帧规范把最大有效载荷尺寸定为1500个字节,有时候,你会发现Ethernet MTU定义为1518或1514:第一个Ethernet帧的最大尺寸包括报头在内,而第二个包括报头但不包括帧检查序列(4个字节的校验和).
结构说明及操作函数
net_device的成员解释及操作函数详见: 网络驱动移植之net_device结构体及其相关的操作函数
三、 用户空间和内核接口
- 1 概论
- 1.1 procfs (/proc 文件系统)
- 1.1.1 编程接口
- 1.2 sysctl (/proc/sys目录)
- 1.2.1 编程接口
- 1.3 sysfs (/sys 文件系统)
- 1.4 ioctl 系统调用
- 1.5 netlink 套接字
- 1.1 procfs (/proc 文件系统)
概论
procfs (/proc 文件系统)
- 允许内核以文件的形式向用户空间输出内部信息。
- 可以通过cat, more和> shell重定向进行查看与写入。
编程接口
- 内核proc文件系统与seq接口(1)—内核proc文件系统简介
- 内核proc文件系统与seq接口(2)—内核proc文件系统编程接口
- 内核proc文件系统与seq接口(3)—内核proc文件底层结构浅析
- 内核proc文件系统与seq接口(4)—seq_file接口编程浅析
- 内核proc文件系统与seq接口(5)—通用proc接口与seq_file接口实验
sysctl (/proc/sys目录)
此接口允许用户空间读取或修改内核变量的值。
两种方式访问sysctl的输出变量:
- sysctl 系统调用
- procfs
编程接口
/proc/sys/中的文件和目录都是依ctl_table结构定义的。ctl_table结构的注册和除名是通过在kernel/sysctl.c中定义的register_sysctl_table和unregister_sysctl_table函数完成。
- ctl_table结构
1: struct ctl_table 2: { 3: const char *procname; /* proc/sys中所用的文件名 */ 4: void *data; 5: int maxlen; /* 输出的内核变量的尺寸大小 */ 6: mode_t mode; 7: struct ctl_table *child; /* 用于建立目录与文件之间的父子关系 */ 8: struct ctl_table *parent; /* Automatically set */ 9: proc_handler *proc_handler; /* 完成读取或者写入操作的函数 */ 10: void *extra1; 11: void *extra2; /* 两个可选参数,通常用于定义变量的最小值和最大值ֵ */ 12: };
一般来讲,/proc/sys下定义了以下几个主目录(kernel, vm, fs, debug, dev),其以及它的子目录定义如下:
1: static struct ctl_table root_table[] = { 2: { 3: .procname = "kernel", 4: .mode = 0555, 5: .child = kern_table, 6: }, 7: { 8: .procname = "vm", 9: .mode = 0555, 10: .child = vm_table, 11: }, 12: { 13: .procname = "fs", 14: .mode = 0555, 15: .child = fs_table, 16: }, 17: { 18: .procname = "debug", 19: .mode = 0555, 20: .child = debug_table, 21: }, 22: { 23: .procname = "dev", 24: .mode = 0555, 25: .child = dev_table, 26: }, 27: /* 28: * NOTE: do not add new entries to this table unless you have read 29: * Documentation/sysctl/ctl_unnumbered.txt 30: */ 31: { } 32: };
sysfs (/sys 文件系统)
sysfs主要解决了procfs与sysctl滥用的问题而出现的。
ioctl 系统调用
一切均从系统调用开始,当用户调用ioctl函数时,会调用内核中的 SYSCALL_DEFINE3 函数,它是一个宏定义,如下:
1: #define SYSCALL_DEFINE3(name, ...) SYSCALL_DEFINEx(3, _##name, __VA_ARGS__)【注意】宏定义中的第一个#代表替换, 则代表使用’-’强制连接。
SYSCALL_DEFINEx之后调用__SYSCALL_DEFINEx函数,而__SYSCALL_DEFINEx同样是一个宏定义,如下:
1: #define __SYSCALL_DEFINEx(x, name, ...) \ 2: asmlinkage long sys##name(__SC_DECL##x(__VA_ARGS__)); \ 3: static inline long SYSC##name(__SC_DECL##x(__VA_ARGS__)); \ 4: asmlinkage long SyS##name(__SC_LONG##x(__VA_ARGS__)) \ 5: { \ 6: __SC_TEST##x(__VA_ARGS__); \ 7: return (long) SYSC##name(__SC_CAST##x(__VA_ARGS__)); \ 8: } \ 9: SYSCALL_ALIAS(sys##name, SyS##name); \ 10: static inline long SYSC##name(__SC_DECL##x(__VA_ARGS__))中间会调用红色部分的宏定义, asmlinkage 会通知编译器仅从 栈 中提取该函数的参数,
上面只是阐述了系统调用的一般过程,值得注意的是,上面这种系统调用过程的应用于最新的内核代码中,老版本中的这些过程是在syscall函数中完成的。
我们就以在网络编程中ioctl系统调用为例介绍整个调用过程。当用户调用ioctl试图去从内核中获取某些值时,会触发调用:
1: SYSCALL_DEFINE3(ioctl, unsigned int, fd, unsigned int, cmd, unsigned long, arg) 2: { 3: struct file *filp; 4: int error = -EBADF; 5: int fput_needed; 6: 7: filp = fget_light(fd, &fput_needed); //根据进程描述符获取对应的文件对象 8: if (!filp) 9: goto out; 10: 11: error = security_file_ioctl(filp, cmd, arg); 12: if (error) 13: goto out_fput; 14: 15: error = do_vfs_ioctl(filp, fd, cmd, arg); 16: out_fput: 17: fput_light(filp, fput_needed); 18: out: 19: return error; 20: }之后依次经过 file_ioctl-—>vfs_ioctl 找到对应的与socket相对应的ioctl,即sock_ioctl.
1: static long vfs_ioctl(struct file *filp, unsigned int cmd, 2: unsigned long arg) 3: { 4: ........ 5: if (filp->f_op->unlocked_ioctl) { 6: error = filp->f_op->unlocked_ioctl(filp, cmd, arg); 7: if (error == -ENOIOCTLCMD) 8: error = -EINVAL; 9: goto out; 10: } else if (filp->f_op->ioctl) { 11: lock_kernel(); 12: error = filp->f_op->ioctl(filp->f_path.dentry->d_inode, 13: filp, cmd, arg); 14: unlock_kernel(); 15: } 16: ....... 17: }从上面代码片段中可以看出,根据对应的文件指针调用对应的ioctl,那么socket对应的文件指针的初始化是在哪完成的呢?可以参考socket.c文件下sock_alloc_file函数:
1: static int sock_alloc_file(struct socket *sock, struct file **f, int flags) 2: { 3: struct qstr name = { .name = "" }; 4: struct path path; 5: struct file *file; 6: int fd; 7: .............. 8: file = alloc_file(&path, FMODE_READ | FMODE_WRITE, 9: &socket_file_ops); 10: if (unlikely(!file)) { 11: /* drop dentry, keep inode */ 12: atomic_inc(&path.dentry->d_inode->i_count); 13: path_put(&path); 14: put_unused_fd(fd); 15: return -ENFILE; 16: } 17: ............. 18: }alloc_file函数将socket_file_ops指针赋值给socket中的f_op.同时注意 file->private_data = sock 这条语句。
1: struct file *alloc_file(struct path *path, fmode_t mode,const struct file_operations *fop) 2: { 3: ......... 4: 5: file->f_path = *path; 6: file->f_mapping = path->dentry->d_inode->i_mapping; 7: file->f_mode = mode; 8: file->f_op = fop; 9: 10: file->private_data = sock; 11: ........ 12: }而socket_file_ops是在socket.c文件中定义的一个静态结构体变量,它的定义如下:
1: static const struct file_operations socket_file_ops = { 2: .owner = THIS_MODULE, 3: .llseek = no_llseek, 4: .aio_read = sock_aio_read, 5: .aio_write = sock_aio_write, 6: .poll = sock_poll, 7: .unlocked_ioctl = sock_ioctl, 8: #ifdef CONFIG_COMPAT 9: .compat_ioctl = compat_sock_ioctl, 10: #endif 11: .mmap = sock_mmap, 12: .open = sock_no_open, /* special open code to disallow open via /proc */ 13: .release = sock_close, 14: .fasync = sock_fasync, 15: .sendpage = sock_sendpage, 16: .splice_write = generic_splice_sendpage, 17: .splice_read = sock_splice_read, 18: };从上面分析可以看出, filp-> f_op->unlocked_ioctl 实质调用的是sock_ioctl。
OK,再从sock_ioctl代码开始,如下:
1: static long sock_ioctl(struct file *file, unsigned cmd, unsigned long arg) 2: { 3: ....... 4: sock = file->private_data; 5: sk = sock->sk; 6: net = sock_net(sk); 7: if (cmd >= SIOCDEVPRIVATE && cmd <= (SIOCDEVPRIVATE + 15)) { 8: err = dev_ioctl(net, cmd, argp); 9: } else 10: #ifdef CONFIG_WEXT_CORE 11: if (cmd >= SIOCIWFIRST && cmd <= SIOCIWLAST) { 12: err = dev_ioctl(net, cmd, argp); 13: } else 14: #endif 15: ....... 16: default: 17: err = sock_do_ioctl(net, sock, cmd, arg); 18: break; 19: } 20: return err; 21: }首先通过file变量的private_date成员将socket从sys_ioctl传递过来,最后通过执行sock_do_ioctl函数完成相应操作。
1: static long sock_do_ioctl(struct net *net, struct socket *sock, 2: unsigned int cmd, unsigned long arg) 3: { 4: ........ 5: err = sock->ops->ioctl(sock, cmd, arg); 6: ......... 7: } 8: 9: 那么此时的socket中的ops成员又是从哪来的呢?我们以IPV4为例,都知道在创建socket时,都会需要设置相应的协议类型,此处的ops也是socket在创建inet_create函数中遍历inetsw列表得到的。 10: 11: static int inet_create(struct net *net, struct socket *sock, int protocol, 12: int kern) 13: { 14: struct inet_protosw *answer; 15: ........ 16: sock->ops = answer->ops; 17: answer_prot = answer->prot; 18: answer_no_check = answer->no_check; 19: answer_flags = answer->flags; 20: rcu_read_unlock(); 21: ......... 22: }那么inetsw列表又是在何处生成的呢?那是在协议初始化函数inet_init中调用inet_register_protosw(将全局结构体数组inetsw_array数组初始化)来实现的,
1: static struct inet_protosw inetsw_array[] = 2: { 3: { 4: .type = SOCK_STREAM, 5: .protocol = IPPROTO_TCP, 6: .prot = &tcp_prot, 7: .ops = &inet_stream_ops, 8: .no_check = 0, 9: .flags = INET_PROTOSW_PERMANENT | 10: INET_PROTOSW_ICSK, 11: }, 12: { 13: .type = SOCK_DGRAM, 14: .protocol = IPPROTO_UDP, 15: .prot = &udp_prot, 16: .ops = &inet_dgram_ops, 17: .no_check = UDP_CSUM_DEFAULT, 18: .flags = INET_PROTOSW_PERMANENT, 19: }, 20: { 21: .type = SOCK_RAW, 22: .protocol = IPPROTO_IP, /* wild card */ 23: .prot = &raw_prot, 24: .ops = &inet_sockraw_ops, 25: .no_check = UDP_CSUM_DEFAULT, 26: .flags = INET_PROTOSW_REUSE, 27: } 28: };很明显可以看到, sock-> ops->ioctl 需要根据具体的协议找到需要调用的ioctl函数。我们就以TCP协议为例,就需要调用 inet_stream_ops 中的ioctl函数——inet_ioctl,结构如下:
1: int inet_ioctl(struct socket *sock, unsigned int cmd, unsigned long arg) 2: { 3: struct sock *sk = sock->sk; 4: int err = 0; 5: struct net *net = sock_net(sk); 6: 7: switch (cmd) { 8: case SIOCGSTAMP: 9: err = sock_get_timestamp(sk, (struct timeval __user *)arg); 10: break; 11: case SIOCGSTAMPNS: 12: err = sock_get_timestampns(sk, (struct timespec __user *)arg); 13: break; 14: case SIOCADDRT: //增加路由 15: case SIOCDELRT: //删除路由 16: case SIOCRTMSG: 17: err = ip_rt_ioctl(net, cmd, (void __user *)arg); //IP路由配置 18: break; 19: case SIOCDARP: //删除ARP项 20: case SIOCGARP: //获取ARP项 21: case SIOCSARP: //创建或者修改ARP项 22: err = arp_ioctl(net, cmd, (void __user *)arg); //ARP配置 23: break; 24: case SIOCGIFADDR: //获取接口地址 25: case SIOCSIFADDR: //设置接口地址 26: case SIOCGIFBRDADDR: //获取广播地址 27: case SIOCSIFBRDADDR: //设置广播地址 28: case SIOCGIFNETMASK: //获取网络掩码 29: case SIOCSIFNETMASK: //设置网络掩码 30: case SIOCGIFDSTADDR: //获取某个接口的点对点地址 31: case SIOCSIFDSTADDR: //设置每个接口的点对点地址 32: case SIOCSIFPFLAGS: 33: case SIOCGIFPFLAGS: 34: case SIOCSIFFLAGS: //设置接口标志 35: err = devinet_ioctl(net, cmd, (void __user *)arg); //网络接口配置相关 36: break; 37: default: 38: if (sk->sk_prot->ioctl) 39: err = sk->sk_prot->ioctl(sk, cmd, arg); 40: else 41: err = -ENOIOCTLCMD; 42: break; 43: } 44: return err; 45: }
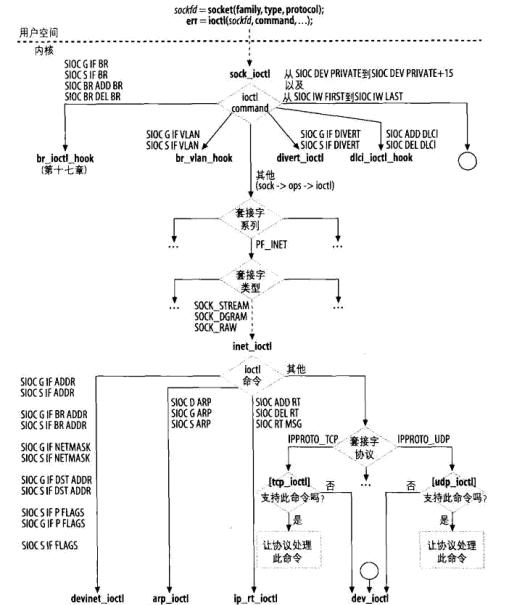
图:ioctl命令的分派
netlink 套接字
netlink已经成为用户空间与内核的IP网络配置之间的首选接口,同时它也可以作为内核内部与多个用户空间进程之间的消息传输系统.
在实现netlink用于内核空间与用户空间之间的通信时,用户空间的创建方法和一般的套接字的创建使用类似,但内核的创建方法则有所不同,
下图是netlink实现此类通信时的创建过程:

下面分别详细介绍内核空间与用户空间在实现此类通信时的创建方法:
● 用户空间:
创建流程大体如下:
① 创建socket套接字
② 调用bind函数完成地址的绑定,不过同通常意义下server端的绑定还是存在一定的差别的,server端通常绑定某个端口或者地址,而此处的绑定则是 将 socket 套接口与本进程的 pid 进行绑定 ;
③ 通过sendto或者sendmsg函数发送消息;
④ 通过recvfrom或者rcvmsg函数接受消息。
【说明】
◆ netlink对应的协议簇是AF_NETLINK,协议类型可以是自定义的类型,也可以是内核预定义的类型;
1: #define NETLINK_ROUTE 0 /* Routing/device hook */ 2: #define NETLINK_UNUSED 1 /* Unused number */ 3: #define NETLINK_USERSOCK 2 /* Reserved for user mode socket protocols */ 4: #define NETLINK_FIREWALL 3 /* Firewalling hook */ 5: #define NETLINK_INET_DIAG 4 /* INET socket monitoring */ 6: #define NETLINK_NFLOG 5 /* netfilter/iptables ULOG */ 7: #define NETLINK_XFRM 6 /* ipsec */ 8: #define NETLINK_SELINUX 7 /* SELinux event notifications */ 9: #define NETLINK_ISCSI 8 /* Open-iSCSI */ 10: #define NETLINK_AUDIT 9 /* auditing */ 11: #define NETLINK_FIB_LOOKUP 10 12: #define NETLINK_CONNECTOR 11 13: #define NETLINK_NETFILTER 12 /* netfilter subsystem */ 14: #define NETLINK_IP6_FW 13 15: #define NETLINK_DNRTMSG 14 /* DECnet routing messages */ 16: #define NETLINK_KOBJECT_UEVENT 15 /* Kernel messages to userspace */ 17: #define NETLINK_GENERIC 16 18: /* leave room for NETLINK_DM (DM Events) */ 19: #define NETLINK_SCSITRANSPORT 18 /* SCSI Transports */ 20: #define NETLINK_ECRYPTFS 19 21: 22: /* 如下这个类型是UTM组新增使用 */ 23: #define NETLINK_UTM_BLOCK 20 /* UTM block ip to userspace */ 24: #define NETLINK_AV_PROXY 21 /* av proxy */ 25: #define NETLINK_KURL 22 /*for commtouch*/ 26: 27: #define MAX_LINKS 32上面是内核预定义的20种类型,当然也可以自定义一些。
◆ 前面说过,netlink处的绑定有着自己的特殊性,其需要绑定的协议地址可用以下结构来描述:
1: struct sockaddr_nl { 2: sa_family_t nl_family; /* AF_NETLINK */ 3: unsigned short nl_pad; /* zero */ 4: __u32 nl_pid; /* port ID */ 5: __u32 nl_groups; /* multicast groups mask */ 6: };其中成员nl_family为AF_NETLINK,nl_pad当前未使用,需设置为0,成员nl_pid为 接收或发送消息的进程的 ID ,如果希望内核处理消息或多播消息,
就把该字段设置为 0,否则设置为处理消息的进程 ID.,不过在此特别需要说明的是,此处是以进程为单位,倘若进程存在多个线程,那在与netlink通信的过程中如何准确找到对方线程呢?
此时nl_pid可以这样表示:
1: pthread_self() << 16 | getpid()pthread_self函数是用来获取线程ID,总之能够区分各自线程目的即可。 成员 nl_groups 用于指定多播组 ,bind 函数用于把调用进程加入到该字段指定的多播组, 如果设置为 0 ,表示调用者不加入任何多播组 。
◆ 通过netlink发送的消息结构:
1: struct nlmsghdr { 2: __u32 nlmsg_len; /* Length of message including header */ 3: __u16 nlmsg_type; /* Message content */ 4: __u16 nlmsg_flags; /* Additional flags */ 5: __u32 nlmsg_seq; /* Sequence number */ 6: __u32 nlmsg_pid; /* Sending process port ID */ 7: };其中nlmsg_len指的是消息长度,nlmsg_type指的是消息类型,用户可以自己定义。字段nlmsg_flags 用于设置消息标志,对于一般的使用,用户把它设置为0 就可以,
只是一些高级应用(如netfilter 和路由daemon 需要它进行一些复杂的操作), 字段 nlmsg_seq 和 nlmsg_pid 用于应用追踪消息,前者表示顺序号,后者为消息来源进程 ID 。
● 内核空间:
内核空间主要完成以下三方面的工作:
① 创建netlinksocket,并注册回调函数,注册函数将会在有消息到达netlinksocket时会执行;
② 根据用户请求类型,处理用户空间的数据;
③ 将数据发送回用户。
【说明】
◆ netlink中利用netlink_kernel_create函数创建一个netlink socket.
1: extern struct sock *netlink_kernel_create(struct net *net, 2: int unit,unsigned int groups, 3: void (*input)(struct sk_buff *skb), 4: struct mutex *cb_mutex, 5: struct module *module);net字段指的是网络的命名空间,一般用&init_net替代; unit 字段实质是 netlink 协议类型,值得注意的是,此值一定要与用户空间创建 socket 时的第三个参数值保持一致 ;
groups字段指的是socket的组名,一般置为0即可;input字段是回调函数,当netlink收到消息时会被触发;cb_mutex一般置为NULL;module一般置为THIS_MODULE宏。
◆ netlink是通过调用API函数netlink_unicast或者netlink_broadcast将数据返回给用户的.
1: int netlink_unicast(struct sock *ssk, struct sk_buff *skb,u32 pid, int nonblock)ssk字段正是由netlink_kernel_create函数所返回的socket;参数skb指向的是socket缓存, 它的 data 字段用来指向要发送的 netlink 消息结构 ; 参数 pid 为接收消息进程的 pid ,
参数 nonblock 表示该函数是否为非阻塞,如果为 1 ,该函数将在没有接收缓存可利用时立即返回,而如果为 0 ,该函数在没有接收缓存可利用时睡眠 。
【引申】内核发送的netlink消息是通过struct sk_buffer结构来管理的,即socket缓存,linux/netlink.h中定义了
1: #define NETLINK_CB(skb) (*(struct netlink_skb_parms*)&((skb)->cb))来方便消息的地址设置。
1: struct netlink_skb_parms { 2: struct ucred creds; /* Skb credentials */ 3: __u32 pid; 4: __u32 dst_group; 5: kernel_cap_t eff_cap; 6: __u32 loginuid; /* Login (audit) uid */ 7: __u32 sessionid; /* Session id (audit) */ 8: __u32 sid; /* SELinux security id */ 9: };其中pid指的是发送者的进程ID,如:
1: NETLINK_CB(skb).pid = 0; /*from kernel */
四、 通知链
- 1 概述
- 2 定义链
- 3 链注册
- 4 链上的通知事件
- 5 网络子系统的通知链
- 5.1 包裹函数
- 5.2 范例
- 6 测试实例
概述
[注意] 通知链只在内核子系统之间使用。
大多数内核子系统都是相互独立的,因此某个子系统可能对其它子系统产生的事件感兴趣。为了满足这个需求,也即是让某个子系统在发生某个事件时通知其它的子系统,
Linux内核提供了通知链的机制。通知链表只能够在内核的子系统之间使用,而不能够在内核与用户空间之间进行事件的通知。
通知链表是一个函数链表,链表上的每一个节点都注册了一个函数。当某个事情发生时,链表上所有节点对应的函数就会被执行。所以对于通知链表来说有一个通知方与一个接收方。
在通知这个事件时所运行的函数由被通知方决定,实际上也即是被通知方注册了某个函数,在发生某个事件时这些函数就得到执行。其实和系统调用signal的思想差不多。
定义链
通知链表的节点类型为notifier_block,其定义如下:
1: struct notifier_block { 2: int (*notifier_call)(struct notifier_block *, unsigned long, void *); 3: struct notifier_block *next; 4: int priority; 5: };其中最重要的就是notifier_call这个函数指针,表示了这个节点所对应的要运行的那个函数。next指向下一个节点,即当前事件发生时还要继续执行的那些节点。
[注] include/linux/notifier.h
链注册
在通知链注册时,需要有一个链表头,它指向这个通知链表的第一个元素。这样,之后的事件对该链表通知时就会根据这个链表头而找到这个链表中所有的元素。
注册的函数是:
1: int notifier_chain_register(struct notifier_block **nl, struct notifier_block *n)也即是将新的节点n加入到nl所指向的链表中去。
1: int notifier_chain_unregister(strut notifier_block **nl, struct notifier_block *n)也即是将节点n从nl所指向的链表中删除。
链上的通知事件
当有事件发生时,就使用notifier_call_chain向某个通知链表发送消息。
1: int notifier_call_chain(struct notifier_block **nl, unsigned long val, void *v)这个函数是按顺序运行nl指向的链表上的所有节点上注册的函数。简单地说,如下所示:
1: struct notifier_block *nb = *n; 2: 3: while (nb) 4: { 5: ret = nb->notifier_call(nb, val, v); 6: if (ret & NOTIFY_STOP_MASK) 7: { 8: return ret; 9: } 10: nb = nb->next; 11: }
网络子系统的通知链
- inetaddr_chain
发送有关本地接口上的ipv4地址的插入,删除以及变更的通知信息。
- netdev_chain
发送有关网络设备注册状态的通知信息。
包裹函数
大多数通知链都有一组包裹函数,可以用于注册与删除。例如,下列包裹函数可用于向netdev_chain注册:
1: /* 2: * Device change register/unregister. These are not inline or static 3: * as we export them to the world. 4: */ 5: 6: /** 7: * register_netdevice_notifier - register a network notifier block 8: * @nb: notifier 9: * 10: * Register a notifier to be called when network device events occur. 11: * The notifier passed is linked into the kernel structures and must 12: * not be reused until it has been unregistered. A negative errno code 13: * is returned on a failure. 14: * 15: * When registered all registration and up events are replayed 16: * to the new notifier to allow device to have a race free 17: * view of the network device list. 18: */ 19: 20: int register_netdevice_notifier(struct notifier_block *nb) 21: { 22: struct net_device *dev; 23: struct net_device *last; 24: struct net *net; 25: int err; 26: 27: rtnl_lock(); 28: err = raw_notifier_chain_register(&netdev_chain, nb); 29: if (err) 30: goto unlock; 31: if (dev_boot_phase) 32: goto unlock; 33: for_each_net(net) { 34: for_each_netdev(net, dev) { 35: err = nb->notifier_call(nb, NETDEV_REGISTER, dev); 36: err = notifier_to_errno(err); 37: if (err) 38: goto rollback; 39: 40: if (!(dev->flags & IFF_UP)) 41: continue; 42: 43: nb->notifier_call(nb, NETDEV_UP, dev); 44: } 45: } 46: 47: unlock: 48: rtnl_unlock(); 49: return err; 50: 51: rollback: 52: last = dev; 53: for_each_net(net) { 54: for_each_netdev(net, dev) { 55: if (dev == last) 56: break; 57: 58: if (dev->flags & IFF_UP) { 59: nb->notifier_call(nb, NETDEV_GOING_DOWN, dev); 60: nb->notifier_call(nb, NETDEV_DOWN, dev); 61: } 62: nb->notifier_call(nb, NETDEV_UNREGISTER, dev); 63: nb->notifier_call(nb, NETDEV_UNREGISTER_BATCH, dev); 64: } 65: } 66: 67: raw_notifier_chain_unregister(&netdev_chain, nb); 68: goto unlock; 69: } 70: EXPORT_SYMBOL(register_netdevice_notifier);
范例
通知链注册通常发送在感兴趣的内核初始化时。
1: static struct notifier_block fib_inetaddr_notifier = { 2: .notifier_call = fib_inetaddr_event, 3: }; 4: 5: static struct notifier_block fib_netdev_notifier = { 6: .notifier_call = fib_netdev_event, 7: }; 8: 9: void __init ip_fib_init(void) 10: { 11: rtnl_register(PF_INET, RTM_NEWROUTE, inet_rtm_newroute, NULL); 12: rtnl_register(PF_INET, RTM_DELROUTE, inet_rtm_delroute, NULL); 13: rtnl_register(PF_INET, RTM_GETROUTE, NULL, inet_dump_fib); 14: 15: register_pernet_subsys(&fib_net_ops); 16: register_netdevice_notifier(&fib_netdev_notifier); 17: register_inetaddr_notifier(&fib_inetaddr_notifier); 18: 19: fib_hash_init(); 20: }[注] net/ipv4/fib_frontend.c
测试实例
在这里,写了一个简单的通知链表的代码。
实际上,整个通知链的编写也就两个过程:
首先是定义自己的通知链的头节点,并将要执行的函数注册到自己的通知链中。
其次则是由另外的子系统来通知这个链,让其上面注册的函数运行。
我这里将第一个过程分成了两步来写,第一步是定义了头节点和一些自定义的注册函数(针对该头节点的),第二步则是使用自定义的注册函数注册了一些通知链节点。分别在代码buildchain.c与regchain.c中。
发送通知信息的代码为notify.c。
代码1 buildchain.c
它的作用是自定义一个通知链表test_chain,然后再自定义两个函数分别向这个通知链中加入或删除节点,最后再定义一个函数通知这个test_chain链。
1: #include2: #include 3: #include 4: #include 5: #include 6: #include 7: #include 8: #include 9: MODULE_LICENSE("GPL"); 10: 11: /* 12: * 定义自己的通知链头结点以及注册和卸载通知链的外包函数 13: */ 14: 15: /* 16: * RAW_NOTIFIER_HEAD是定义一个通知链的头部结点, 17: * 通过这个头部结点可以找到这个链中的其它所有的notifier_block 18: */ 19: 20: static RAW_NOTIFIER_HEAD(test_chain); 21: 22: /* 23: * 自定义的注册函数,将notifier_block节点加到刚刚定义的test_chain这个链表中来 24: * raw_notifier_chain_register会调用notifier_chain_register 25: */ 26: 27: int register_test_notifier(struct notifier_block *nb) 28: { 29: return raw_notifier_chain_register(&test_chain, nb); 30: } 31: EXPORT_SYMBOL(register_test_notifier); 32: 33: int unregister_test_notifier(struct notifier_block *nb) 34: { 35: return raw_notifier_chain_unregister(&test_chain, nb); 36: } 37: EXPORT_SYMBOL(unregister_test_notifier); 38: 39: /* 40: * 自定义的通知链表的函数,即通知test_chain指向的链表中的所有节点执行相应的函数 41: */ 42: 43: int test_notifier_call_chain(unsigned long val, void *v) 44: { 45: return raw_notifier_call_chain(&test_chain, val, v); 46: } 47: EXPORT_SYMBOL(test_notifier_call_chain); 48: 49: /* 50: * init and exit 51: */ 52: 53: static int __init init_notifier(void) 54: { 55: printk("init_notifier\n"); 56: return 0; 57: } 58: 59: static void __exit exit_notifier(void) 60: { 61: printk("exit_notifier\n"); 62: } 63: module_init(init_notifier); 64: module_exit(exit_notifier);
该代码的作用是将test_notifier1 test_notifier2 test_notifier3这三个节点加到之前定义的test_chain这个通知链表上,同时每个节点都注册了一个函数。
1: #include2: #include 3: #include 4: #include 5: #include 6: #include 7: #include 8: #include 9: MODULE_LICENSE("GPL"); 10: 11: /* 12: * 注册通知链 13: */ 14: 15: extern int register_test_notifier(struct notifier_block*); 16: 17: extern int unregister_test_notifier(struct notifier_block*); 18: 19: static int test_event1(struct notifier_block *this, unsigned long event, void *ptr) 20: { 21: printk("In Event 1: Event Number is %d\n", event); 22: return 0; 23: } 24: 25: static int test_event2(struct notifier_block *this, unsigned long event, void *ptr) 26: { 27: printk("In Event 2: Event Number is %d\n", event); 28: return 0; 29: } 30: 31: static int test_event3(struct notifier_block *this, unsigned long event, void *ptr) 32: { 33: printk("In Event 3: Event Number is %d\n", event); 34: return 0; 35: } 36: 37: /* 38: * 事件1,该节点执行的函数为test_event1 39: */ 40: 41: static struct notifier_block test_notifier1 = 42: { 43: .notifier_call = test_event1, 44: }; 45: 46: /* 47: * 事件2,该节点执行的函数为test_event1 48: */ 49: 50: static struct notifier_block test_notifier2 = 51: { 52: .notifier_call = test_event2, 53: }; 54: 55: /* 56: * 事件3,该节点执行的函数为test_event1 57: */ 58: 59: static struct notifier_block test_notifier3 = 60: { 61: .notifier_call = test_event3, 62: }; 63: 64: /* 65: * 对这些事件进行注册 66: */ 67: 68: static int __init reg_notifier(void) 69: { 70: int err; 71: printk("Begin to register:\n"); 72: 73: err = register_test_notifier(&test_notifier1); 74: if (err) 75: { 76: printk("register test_notifier1 error\n"); 77: return -1; 78: } 79: printk("register test_notifier1 completed\n"); 80: 81: err = register_test_notifier(&test_notifier2); 82: if (err) 83: { 84: printk("register test_notifier2 error\n"); 85: return -1; 86: } 87: printk("register test_notifier2 completed\n"); 88: 89: err = register_test_notifier(&test_notifier3); 90: if (err) 91: { 92: printk("register test_notifier3 error\n"); 93: return -1; 94: } 95: printk("register test_notifier3 completed\n"); 96: return err; 97: } 98: 99: /* 100: * 卸载刚刚注册了的通知链 101: */ 102: 103: static void __exit unreg_notifier(void) 104: { 105: printk("Begin to unregister\n"); 106: unregister_test_notifier(&test_notifier1); 107: unregister_test_notifier(&test_notifier2); 108: unregister_test_notifier(&test_notifier3); 109: printk("Unregister finished\n"); 110: } 111: module_init(reg_notifier); 112: module_exit(unreg_notifier);
该代码的作用就是向test_chain通知链中发送消息,让链中的函数运行。
1: #include2: #include 3: #include 4: #include 5: #include 6: #include 7: #include 8: #include 9: MODULE_LICENSE("GPL"); 10: 11: extern int test_notifier_call_chain(unsigned long val, void *v); 12: 13: /* 14: * 向通知链发送消息以触发注册了的函数 15: */ 16: 17: static int __init call_notifier(void) 18: { 19: int err; 20: printk("Begin to notify:\n"); 21: 22: /* 23: * 调用自定义的函数,向test_chain链发送消息 24: */ 25: 26: printk("==============================\n"); 27: err = test_notifier_call_chain(1, NULL); 28: printk("==============================\n"); 29: if (err) 30: printk("notifier_call_chain error\n"); 31: return err; 32: } 33: 34: 35: static void __exit uncall_notifier(void) 36: { 37: printk("End notify\n"); 38: } 39: module_init(call_notifier); 40: module_exit(uncall_notifier);
1: obj-m:=buildchain.o regchain.o notify.o 2: 3: KERNELDIR:=/lib/modules/$(shell uname -r)/build 4: 5: default: 6: make -C $(KERNELDIR) M=$(shell pwd) modules运行:
1: make 2: 3: insmod buildchain.ko 4: insmod regchain.ko 5: insmod notify.ko这样就可以看到通知链运行的效果了
下面是我在自己的机器上面运行得到的结果:
1: init_notifier 2: Begin to register: 3: register test_notifier1 completed 4: register test_notifier2 completed 5: register test_notifier3 completed 6: Begin to notify: 7: ============================== 8: In Event 1: Event Number is 1 9: In Event 2: Event Number is 1 10: In Event 3: Event Number is 1 11: ==============================
五、 网络设备初始化
- 1 简介
- 2 系统初始化概论
- 2.1 引导期间选项
- 2.2 中断和定时器
- 2.3 初始化函数
- 3 设备注册和初始化
- 3.1 硬件初始化
- 3.2 软件初始化
- 3.3 功能初始化
- 4 NIC初始化的基本目标
- 5 IRQ线
- 6 I/O端口和内存注册
- 7 硬件中断
- 7.1 注册中断
- 7.2 解除中断
- 8 模块选项
- 9 设备处理层初始化
- 10 动态加载设备/设备驱动
简介
如果要使一个网络设备可用,它就必须能被内核正确识别并且与正确的设备驱动关联起来。首先,设备驱动既可以做为内核模块动态加载,也可以是内核的一个静态组件。其次,设备可以在启动时识别,也可以在运行时加载识别(热插拔设备 USB PCI IEEE…)。
系统初始化概论
下图为系统初始化流程
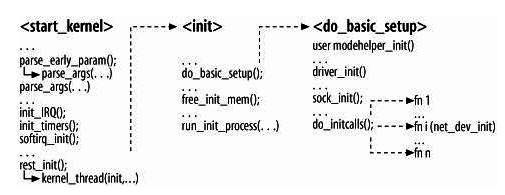
图5-1:内核初始化
引导期间选项
调用两次parse_args(一次是直接调用, 而另外一次是通过parse_early_param间接调用)以处理引导加载程序(bootloader, 如LILO或GRUB)
在引导期间传给内核的配置参数。
中断和定时器
硬中断和软中断分别由init_IRQ和softirq_init做初始化。
初始化函数
内核子系统及内建的设备驱动程序由do_initcall初始化。
设备注册和初始化
注册和初始化的任务的一部分的内核负责,而其他部分由设备驱动程序负责。
硬件初始化
由设备驱动在总线(pci,usb)的协调下完成,主要分配中断号和i/o地址。
软件初始化
在设备可用前需要配置一些参数,如ip地址
功能初始化
与设备相关,如流量控制
NIC初始化的基本目标
IRQ线
NIC必须被分派一个IRQ。
I/O端口和内存注册
I/O端口和内存f分别使用request_region和release_region注册及释放。
硬件中断
注册中断
1: static inline int __must_check 2: request_irq(unsigned int irq, irq_handler_t handler, unsigned long flags, 3: const char *name, void *dev) 4: { 5: return request_threaded_irq(irq, handler, NULL, flags, name, dev); 6: }
解除中断
1: extern void free_irq(unsigned int, void *);
模块选项
每个模块都在/sys/modules中分派一个目录。子目录/sys/modules/module/parameters中的每个文件就是
改模块所输出的每个参数。
设备处理层初始化
[注] net/core/dev.c
1: /* 2: * Initialize the DEV module. At boot time this walks the device list and 3: * unhooks any devices that fail to initialise (normally hardware not 4: * present) and leaves us with a valid list of present and active devices. 5: * 6: */ 7: 8: /* 9: * This is called single threaded during boot, so no need 10: * to take the rtnl semaphore. 11: */ 12: static int __init net_dev_init(void) 13: { 14: int i, rc = -ENOMEM; 15: 16: BUG_ON(!dev_boot_phase); 17: 18: if (dev_proc_init()) 19: goto out; 20: 21: if (netdev_kobject_init()) 22: goto out; 23: 24: INIT_LIST_HEAD(&ptype_all); 25: for (i = 0; i < PTYPE_HASH_SIZE; i++) 26: INIT_LIST_HEAD(&ptype_base[i]); 27: 28: if (register_pernet_subsys(&netdev_net_ops)) 29: goto out; 30: 31: /* 32: * Initialise the packet receive queues. 33: */ 34: 35: for_each_possible_cpu(i) { 36: struct softnet_data *sd = &per_cpu(softnet_data, i); 37: 38: memset(sd, 0, sizeof(*sd)); 39: skb_queue_head_init(&sd->input_pkt_queue); 40: skb_queue_head_init(&sd->process_queue); 41: sd->completion_queue = NULL; 42: INIT_LIST_HEAD(&sd->poll_list); 43: sd->output_queue = NULL; 44: sd->output_queue_tailp = &sd->output_queue; 45: #ifdef CONFIG_RPS 46: sd->csd.func = rps_trigger_softirq; 47: sd->csd.info = sd; 48: sd->csd.flags = 0; 49: sd->cpu = i; 50: #endif 51: 52: sd->backlog.poll = process_backlog; 53: sd->backlog.weight = weight_p; 54: sd->backlog.gro_list = NULL; 55: sd->backlog.gro_count = 0; 56: } 57: 58: dev_boot_phase = 0; 59: 60: /* The loopback device is special if any other network devices 61: * is present in a network namespace the loopback device must 62: * be present. Since we now dynamically allocate and free the 63: * loopback device ensure this invariant is maintained by 64: * keeping the loopback device as the first device on the 65: * list of network devices. Ensuring the loopback devices 66: * is the first device that appears and the last network device 67: * that disappears. 68: */ 69: if (register_pernet_device(&loopback_net_ops)) 70: goto out; 71: 72: if (register_pernet_device(&default_device_ops)) 73: goto out; 74: 75: open_softirq(NET_TX_SOFTIRQ, net_tx_action); 76: open_softirq(NET_RX_SOFTIRQ, net_rx_action); 77: 78: hotcpu_notifier(dev_cpu_callback, 0); 79: dst_init(); 80: dev_mcast_init(); 81: rc = 0; 82: out: 83: return rc; 84: } 85: 86: subsys_initcall(net_dev_init);
- 初始化cpu相关数据结构,用于网络软中断
- 调用dev_proc_init,dev_mcast_init在/proc下增加相应的文件
- 调用netdev_sysfs在/sys下增加相应配置文件
- 调用net_random_init初始化cpu种子数组,这些数组用于在net_random中生成随机数
- 调用dst_init初始化dst
- 初始化网络处理函数数组ptype_base,这些函数用来多路分解接收到的包
- 在通知链表上注册回调函数用于接收cpu热插拔事件
除了上述初始化,对于网络设备来说更重要的是 初始化它的net_device结构,这个会在第8章详细讲
动态加载设备/设备驱动
讲动态加载之前先介绍2个用户空间程序和1个内核函数
- /sbin/modprobe 在内核需要加载某个模块时调用,判断内核传递的模块是不是/etc/modprobe.conf文件中定义的别名
- /sbin/hotplug 在内核检测到一个新设备插入或拔出系统时调用,它的任务是根据设备标识加载正确的驱动
内核函数call_usermodehelper 上面两个用户进程统一由这个函数调用,其中参数arg1指示call_usermodehelper调用哪个用户进程,arg2指示call..使用哪个配
置脚本,流程详见下图;
实际上看懂了上面所说的,动态加载的概念应该很清楚了,最后再说说使用场景
- 以模块方式加载
kmod模块加载器允许内核组件通过调用request_module请求加载某个模块
举个例子;如果系统管理员使用ifconfig配置某个网卡,但这个网卡驱动还没有加载,如eth0,内核就会给/sbin/modprobe发送一个请求,让它加载名称为
eth0的模块。如果/etc/modprobe.conf中包含“alias eth0 xxx”的字符,/sbin/modprobe就会尝试加载xxx.ko模块。
module_param 宏定义在引入sysfs后可以通过文件来访问得到模块参数
模块选项有三项 , 第一项参数名称,第二项参数类型,第三项表示参数作为文件在sys文件系统中所有的权限。
每个模块都会在sys/modules下生成对应的目录,通过目录下的文件可以获取模块参数。
- pnp热插拔
hotplug允许内核检测热插拔设备的插入和拔出并通知用户进程(/sbin/hotplug),用户进程根据这些通知来加载相应的驱动
在编译内核时,会在kernel目录下生成modules.pcimap和modules.usbmap两个文件,这两个文件分别包含了内核所支持设备的pci id和usb id,文件中还包
含于每个设备的id相对应的内核模块名称,当用户进程收到内核关于pnp的通知后,会使用这个文件来查找正确的设备驱动
Footnotes:
1 DEFINITION NOT FOUND: 0
2 DEFINITION NOT FOUND: 1
六、 PCI层和网络接口卡
- 1 本章涉及的数据结构
- 1.1 pci_device_id结构
- 1.2 pci_dev结构
- 1.3 pci_driver结构
- 2 PCI NIC设备驱动程序的注册
- 2.1 注册
- 2.2 解除
- 3 电源管理与网络唤醒
本章涉及的数据结构
pci_device_id结构
1: struct pci_device_id { 2: __u32 vendor, device; /* Vendor and device ID or PCI_ANY_ID*/ 3: __u32 subvendor, subdevice; /* Subsystem ID's or PCI_ANY_ID */ 4: __u32 class, class_mask; /* (class,subclass,prog-if) triplet */ 5: kernel_ulong_t driver_data; /* Data private to the driver */ 6: };pci_device_id唯一标识一个PCI设备。它的几个成员依次分别表示:厂商号,设备号,子厂商号,子设备号,类别,类别掩码(类可分为基类,子类),私有数据。
每一个PCI设备的驱动程序都有一个pci_device_id的数组,用于告诉PCI核心自己能够驱动哪些设备。
[注] include/linux/mod_devicetable.h
pci_dev结构
1: /* 2: * The pci_dev structure is used to describe PCI devices. 3: */ 4: struct pci_dev { 5: /* 总线设备链表元素bus_list:每一个pci_dev结构除了链接到全局设备链表中外,还会通过这个成员连接到其所属PCI总线的设备链表中。 6: 每一条PCI总线都维护一条它自己的设备链表视图,以便描述所有连接在该PCI总线上的设备,其表头由PCI总线的pci_bus结构中的 devices成员所描述t*/ 7: struct list_head bus_list; /* node in per-bus list */ 8: /* 总线指针bus:指向这个PCI设备所在的PCI总线的pci_bus结构。因此,对于桥设备而言,bus指针将指向桥设备的主总线(primary bus),也即指向桥设备所在的PCI总线*/ 9: struct pci_bus *bus; /* bus this device is on */ 10: /* 指针subordinate:指向这个PCI设备所桥接的下级总线。这个指针成员仅对桥设备才有意义,而对于一般的非桥PCI设备而言,该指针成员总是为NULL*/ 11: struct pci_bus *subordinate; /* bus this device bridges to */ 12: 13: /* 无类型指针sysdata:指向一片特定于系统的扩展数据*/ 14: void *sysdata; /* hook for sys-specific extension */ 15: /* 指针procent:指向该PCI设备在/proc文件系统中对应的目录项*/ 16: struct proc_dir_entry *procent; /* device entry in /proc/bus/pci */ 17: struct pci_slot *slot; /* Physical slot this device is in */ 18: 19: /* devfn:这个PCI设备的设备功能号,也成为PCI逻辑设备号(0-255)。其中bit[7:3]是物理设备号(取值范围0-31),bit[2:0]是功能号(取值范围0-7)。 */ 20: unsigned int devfn; /* encoded device & function index */ 21: /* vendor:这是一个16无符号整数,表示PCI设备的厂商ID*/ 22: unsigned short vendor; 23: /*device:这是一个16无符号整数,表示PCI设备的设备ID */ 24: unsigned short device; 25: /* subsystem_vendor:这是一个16无符号整数,表示PCI设备的子系统厂商ID*/ 26: unsigned short subsystem_vendor; 27: /* subsystem_device:这是一个16无符号整数,表示PCI设备的子系统设备ID。*/ 28: unsigned short subsystem_device; 29: /* class:32位的无符号整数,表示该PCI设备的类别,其中,bit[7:0]为编程接口,bit[15:8]为子类别代码,bit [23:16]为基类别代码,bit[31:24]无意义。 30: 显然,class成员的低3字节刚好对应与PCI配置空间中的类代码*/ 31: unsigned int class; /* 3 bytes: (base,sub,prog-if) */ 32: u8 revision; /* PCI revision, low byte of class word */ 33: /* hdr_type:8位符号整数,表示PCI配置空间头部的类型。其中,bit[7]=1表示这是一个多功能设备,bit[7]=0表示这是一个单功能设备。 34: Bit[6:0]则表示PCI配置空间头部的布局类型,值00h表示这是一个一般PCI设备的配置空间头部,值01h表示这是一个PCI-to-PCI桥的配置空间头部, 35: 值02h表示CardBus桥的配置空间头部*/ 36: u8 hdr_type; /* PCI header type (`multi' flag masked out) */ 37: u8 pcie_cap; /* PCI-E capability offset */ 38: u8 pcie_type; /* PCI-E device/port type */ 39: u8 rom_base_reg; /* which config register controls the ROM */ 40: /* rom_base_reg:8位无符号整数,表示PCI配置空间中的ROM基地址寄存器在PCI配置空间中的位置。ROM基地址寄存器在不同类型的PCI配置空间头部的位置是不一样的, 41: 对于type 0的配置空间布局,ROM基地址寄存器的起始位置是30h,而对于PCI-to-PCI桥所用的type 1配置空间布局,ROM基地址寄存器的起始位置是38h*/ 42: u8 pin; /* which interrupt pin this device uses */ 43: 44: /* 指针driver:指向这个PCI设备所对应的驱动程序定义的pci_driver结构。每一个pci设备驱动程序都必须定义它自己的pci_driver结构来描述它自己。*/ 45: struct pci_driver *driver; /* which driver has allocated this device */ 46: /*dma_mask:用于DMA的总线地址掩码,一般来说,这个成员的值是0xffffffff。数据类型dma_addr_t定义在include/asm/types.h中,在x86平台上, 47: dma_addr_t类型就是u32类型*/ 48: u64 dma_mask; /* Mask of the bits of bus address this 49: device implements. Normally this is 50: 0xffffffff. You only need to change 51: this if your device has broken DMA 52: or supports 64-bit transfers. */ 53: 54: struct device_dma_parameters dma_parms; 55: 56: /* 当前操作状态 */ 57: pci_power_t current_state; /* Current operating state. In ACPI-speak, 58: this is D0-D3, D0 being fully functional, 59: and D3 being off. */ 60: int pm_cap; /* PM capability offset in the 61: configuration space */ 62: unsigned int pme_support:5; /* Bitmask of states from which PME# 63: can be generated */ 64: unsigned int pme_interrupt:1; 65: unsigned int d1_support:1; /* Low power state D1 is supported */ 66: unsigned int d2_support:1; /* Low power state D2 is supported */ 67: unsigned int no_d1d2:1; /* Only allow D0 and D3 */ 68: unsigned int wakeup_prepared:1; 69: unsigned int d3_delay; /* D3->D0 transition time in ms */ 70: 71: #ifdef CONFIG_PCIEASPM 72: struct pcie_link_state *link_state; /* ASPM link state. */ 73: #endif 74: 75: pci_channel_state_t error_state; /* current connectivity state */ 76: /* 通用的设备接口*/ 77: struct device dev; /* Generic device interface */ 78: 79: /* 配置空间的大小 */ 80: int cfg_size; /* Size of configuration space */ 81: 82: /* 83: * Instead of touching interrupt line and base address registers 84: * directly, use the values stored here. They might be different! 85: */ 86: /* 无符号的整数irq:表示这个PCI设备通过哪根IRQ输入线产生中断,一般为0-15之间的某个值 */ 87: unsigned int irq; 88: /*表示该设备可能用到的资源,包括:I/O断口区域、设备内存地址区域以及扩展ROM地址区域。*/ 89: struct resource resource[DEVICE_COUNT_RESOURCE]; /* I/O and memory regions + expansion ROMs */ 90: resource_size_t fw_addr[DEVICE_COUNT_RESOURCE]; /* FW-assigned addr */ 91: 92: /* These fields are used by common fixups */ 93: /* 透明 PCI 桥 */ 94: unsigned int transparent:1; /* Transparent PCI bridge */ 95: /* 多功能设备*/ 96: unsigned int multifunction:1;/* Part of multi-function device */ 97: /* keep track of device state */ 98: unsigned int is_added:1; 99: /* 设备是主设备*/ 100: unsigned int is_busmaster:1; /* device is busmaster */ 101: /* 设备不使用msi*/ 102: unsigned int no_msi:1; /* device may not use msi */ 103: /* 配置空间访问形式用块的形式 */ 104: unsigned int block_ucfg_access:1; /* userspace config space access is blocked */ 105: unsigned int broken_parity_status:1; /* Device generates false positive parity */ 106: unsigned int irq_reroute_variant:2; /* device needs IRQ rerouting variant */ 107: unsigned int msi_enabled:1; 108: unsigned int msix_enabled:1; 109: unsigned int ari_enabled:1; /* ARI forwarding */ 110: unsigned int is_managed:1; 111: unsigned int is_pcie:1; /* Obsolete. Will be removed. 112: Use pci_is_pcie() instead */ 113: unsigned int needs_freset:1; /* Dev requires fundamental reset */ 114: unsigned int state_saved:1; 115: unsigned int is_physfn:1; 116: unsigned int is_virtfn:1; 117: unsigned int reset_fn:1; 118: unsigned int is_hotplug_bridge:1; 119: unsigned int __aer_firmware_first_valid:1; 120: unsigned int __aer_firmware_first:1; 121: pci_dev_flags_t dev_flags; 122: atomic_t enable_cnt; /* pci_enable_device has been called */ 123: 124: /* 在挂起时保存配置空间*/ 125: u32 saved_config_space[16]; /* config space saved at suspend time */ 126: struct hlist_head saved_cap_space; 127: /* sysfs ROM入口的属性描述*/ 128: struct bin_attribute *rom_attr; /* attribute descriptor for sysfs ROM entry */ 129: int rom_attr_enabled; /* has display of the rom attribute been enabled? */ 130: struct bin_attribute *res_attr[DEVICE_COUNT_RESOURCE]; /* sysfs file for resources */ 131: struct bin_attribute *res_attr_wc[DEVICE_COUNT_RESOURCE]; /* sysfs file for WC mapping of resources */ 132: #ifdef CONFIG_PCI_MSI 133: struct list_head msi_list; 134: #endif 135: struct pci_vpd *vpd; 136: #ifdef CONFIG_PCI_IOV 137: union { 138: struct pci_sriov *sriov; /* SR-IOV capability related */ 139: struct pci_dev *physfn; /* the PF this VF is associated with */ 140: }; 141: struct pci_ats *ats; /* Address Translation Service */ 142: #endif 143: };
每一个PCI设备都会被分派一个pci_dev实例,如同网络设备都会被分派net_device实例一样。这个结构由内核使用,以引用一个PCI设备。
[注] include/linux/pci.h
pci_driver结构
1: struct pci_driver { 2: struct list_head node; 3: char *name; 4: const struct pci_device_id *id_table; /* must be non-NULL for probe to be called */ 5: int (*probe) (struct pci_dev *dev, const struct pci_device_id *id); /* New device inserted */ 6: void (*remove) (struct pci_dev *dev); /* Device removed (NULL if not a hot-plug capable driver) */ 7: int (*suspend) (struct pci_dev *dev, pm_message_t state); /* Device suspended */ 8: int (*suspend_late) (struct pci_dev *dev, pm_message_t state); 9: int (*resume_early) (struct pci_dev *dev); 10: int (*resume) (struct pci_dev *dev); /* Device woken up */ 11: void (*shutdown) (struct pci_dev *dev); 12: struct pci_error_handlers *err_handler; 13: struct device_driver driver; 14: struct pci_dynids dynids; 15: };定义PCI层与设备驱动程序之间的接口。
[注] include/linux/pci.h
PCI NIC设备驱动程序的注册
注册
1: /** 2: * __pci_register_driver - register a new pci driver 3: * @drv: the driver structure to register 4: * @owner: owner module of drv 5: * @mod_name: module name string 6: * 7: * Adds the driver structure to the list of registered drivers. 8: * Returns a negative value on error, otherwise 0. 9: * If no error occurred, the driver remains registered even if 10: * no device was claimed during registration. 11: */ 12: int __pci_register_driver(struct pci_driver *drv, struct module *owner, 13: const char *mod_name) 14: { 15: int error; 16: 17: /* initialize common driver fields */ 18: drv->driver.name = drv->name; 19: drv->driver.bus = &pci_bus_type; 20: drv->driver.owner = owner; 21: drv->driver.mod_name = mod_name; 22: 23: spin_lock_init(&drv->dynids.lock); 24: INIT_LIST_HEAD(&drv->dynids.list); 25: 26: /* register with core */ 27: error = driver_register(&drv->driver); 28: if (error) 29: goto out; 30: 31: error = pci_create_newid_file(drv); 32: if (error) 33: goto out_newid; 34: 35: error = pci_create_removeid_file(drv); 36: if (error) 37: goto out_removeid; 38: out: 39: return error; 40: 41: out_removeid: 42: pci_remove_newid_file(drv); 43: out_newid: 44: driver_unregister(&drv->driver); 45: goto out; 46: }
[注] net/core/dev.c
解除
1: /** 2: * pci_unregister_driver - unregister a pci driver 3: * @drv: the driver structure to unregister 4: * 5: * Deletes the driver structure from the list of registered PCI drivers, 6: * gives it a chance to clean up by calling its remove() function for 7: * each device it was responsible for, and marks those devices as 8: * driverless. 9: */ 10: 11: void 12: pci_unregister_driver(struct pci_driver *drv) 13: { 14: pci_remove_removeid_file(drv); 15: pci_remove_newid_file(drv); 16: driver_unregister(&drv->driver); 17: pci_free_dynids(drv); 18: }[注] driver/pci/pci-driver.c
电源管理与网络唤醒
PCI电源管理事件由pci_driver数据结构的suspend和resume函数处理。除了分别负责PCIa状态的保存与恢复之外,这些函数遇到NIC的情况时还需采取特殊步骤:
- suspend主要停止设备的出口队列,使得该设备无法再传输。
- resume重启出口i队列,使得该设备得以再次传输。
网络唤醒(Wake-on-Lan, WOL)允许NIC在接收到一种特殊类型的帧时候唤醒处于待命状态的系统,WOL默认是关闭的。 此功能可以用pci_enable_wake打开或关上。
唤醒系统的魔术封包特性:
- 目的MAC地址属于正在接收的NIC(无论单播/多播/广播)。
- 帧中的某处(任何地方)会设置一段48位序列(也就是FF:FF:FF:FF:FF:FF),后面再接NIC MAC地址,在一行中至少连续重复16次。
七、 组件初始化的内核基础架构
- 1 引导期间的内核选项
- 2 注册关键字
- 3 模块初始化代码
引导期间的内核选项
linux运行用户把内核配置选项传给引导记录,然后引导记录再把选项传给内核。
在引导阶段,对parse_args调用两次,负责引导期间配置输入数据。
注册关键字
内核组件可以利用定义在include/linux/init.h中的__setup宏, 注册关键字和相关联的处理函数。以下是其语法:
1: __setup(string, function_handler)string是关键字,而function_handler是相关联的处理函数。
当一段代码编译成模块时,__setup宏会被忽略(即定义为空操作)。
start_kernel两次调用parse_args以解析引导配置字符串的原因在于, 引导期间选项实际上分成两类, 而每一次调用都是针对其中一类:
- 默认选项
多数选项都属于这一类。这些选项都是用__setup宏定义,而是由parse_args第二次被调用时处理。
- 初期选项
内核引导期间,有些选项必须比其他选项更早处理。内核提供了early_param宏以声明这些替代__setup。然后,这些选项会由parse_early_params负责。
early_param和__setup的唯一区别是early_param会设置一个特殊标识,使内核能区分这两种情况。
模块初始化代码
每个模块都必须提供两个特殊函数,称为init_module和cleanup_module。
内核提供两个宏module_init和module_exit,允许开发人员为这两个函数任意命名。
八、 设备注册与初始化
- 1 设备注册之时
- 2 设备除名之时
- 3 分配net_device结构
- 4 NIC注册和除名架构
- 4.1 注册
- 4.2 除名
- 5 设备初始化
- 6 设备类型初始化: xxx_setup函数
- 7 net_device结构的组织
- 8 查询
- 9 设备状态
- 10 注册状态
- 11 设备的注册和除名
- 12 设备注册状态通知
- 13 netdev_chain通知链
- 14 RTnetlink链接通知
- 15 设备注册
- 16 register_netdevice函数
- 17 设备除名
- 18 unregister_netdevice函数
- 19 引用计数
- 20 netdev_wait_allrefs函数
- 21 开启和关闭网络设备
- 22 与电源管理之间的交互
- 23 链路状态变更侦测
- 24 从用户空间配置设备相关信息
- 25 通过/proc文件系统调整
设备注册之时
网络设备的注册发生在下列几种情况之下:
- 加载NIC设备驱动程序
- 如果NIC设备驱动程序内核至内核中,则在引导期间初始化。
- 以模块加载,就会在运行期间初始化。
- 如果NIC设备驱动程序内核至内核中,则在引导期间初始化。
- 插入可热插拔网络设备
当用户把可热插拔NIC设备插入进来时,内核会通知其驱动程序,而驱动程序再注册该设备。
加载PCI驱动程序将调用pci_driver->probe函数的执行,此函数由驱动程序提供,其负责设备的注册。
设备除名之时
- 卸载NIC设备驱动程序
卸载PCI设备驱动程序将导致pci_driver->remove函数的执行,通常命名为xxx_remove_one,此函数负责设备的除名。
- 删除可热插拔设备
分配net_device结构
1: /** 2: * alloc_netdev_mq - allocate network device 3: * @sizeof_priv: size of private data to allocate space for 4: * @name: device name format string 5: * @setup: callback to initialize device 6: * @queue_count: the number of subqueues to allocate 7: * 8: * Allocates a struct net_device with private data area for driver use 9: * and performs basic initialization. Also allocates subquue structs 10: * for each queue on the device at the end of the netdevice. 11: */ 12: struct net_device *alloc_netdev_mq(int sizeof_priv, const char *name, 13: void (*setup)(struct net_device *), unsigned int queue_count) 14: { 15: struct netdev_queue *tx; 16: struct net_device *dev; 17: size_t alloc_size; 18: struct net_device *p; 19: #ifdef CONFIG_RPS 20: struct netdev_rx_queue *rx; 21: int i; 22: #endif 23: 24: BUG_ON(strlen(name) >= sizeof(dev->name)); 25: 26: alloc_size = sizeof(struct net_device); 27: if (sizeof_priv) { 28: /* ensure 32-byte alignment of private area */ 29: alloc_size = ALIGN(alloc_size, NETDEV_ALIGN); 30: alloc_size += sizeof_priv; 31: } 32: /* ensure 32-byte alignment of whole construct */ 33: alloc_size += NETDEV_ALIGN - 1; 34: 35: p = kzalloc(alloc_size, GFP_KERNEL); 36: if (!p) { 37: printk(KERN_ERR "alloc_netdev: Unable to allocate device.\n"); 38: return NULL; 39: } 40: 41: tx = kcalloc(queue_count, sizeof(struct netdev_queue), GFP_KERNEL); 42: if (!tx) { 43: printk(KERN_ERR "alloc_netdev: Unable to allocate " 44: "tx qdiscs.\n"); 45: goto free_p; 46: } 47: #ifdef CONFIG_RPS 48: rx = kcalloc(queue_count, sizeof(struct netdev_rx_queue), GFP_KERNEL); 49: if (!rx) { 50: printk(KERN_ERR "alloc_netdev: Unable to allocate " 51: "rx queues.\n"); 52: goto free_tx; 53: } 54: 55: atomic_set(&rx->count, queue_count); 56: 57: /* 58: * Set a pointer to first element in the array which holds the 59: * reference count. 60: */ 61: for (i = 0; i < queue_count; i++) 62: rx[i].first = rx; 63: #endif 64: 65: dev = PTR_ALIGN(p, NETDEV_ALIGN); 66: dev->padded = (char *)dev - (char *)p; 67: 68: if (dev_addr_init(dev)) 69: goto free_rx; 70: 71: dev_mc_init(dev); 72: dev_uc_init(dev); 73: 74: dev_net_set(dev, &init_net); 75: 76: dev->_tx = tx; 77: dev->num_tx_queues = queue_count; 78: dev->real_num_tx_queues = queue_count; 79: 80: #ifdef CONFIG_RPS 81: dev->_rx = rx; 82: dev->num_rx_queues = queue_count; 83: #endif 84: 85: dev->gso_max_size = GSO_MAX_SIZE; 86: 87: netdev_init_queues(dev); 88: 89: INIT_LIST_HEAD(&dev->ethtool_ntuple_list.list); 90: dev->ethtool_ntuple_list.count = 0; 91: INIT_LIST_HEAD(&dev->napi_list); 92: INIT_LIST_HEAD(&dev->unreg_list); 93: INIT_LIST_HEAD(&dev->link_watch_list); 94: dev->priv_flags = IFF_XMIT_DST_RELEASE; 95: setup(dev); 96: strcpy(dev->name, name); 97: return dev; 98: 99: free_rx: 100: #ifdef CONFIG_RPS 101: kfree(rx); 102: free_tx: 103: #endif 104: kfree(tx); 105: free_p: 106: kfree(p); 107: return NULL; 108: } 109: EXPORT_SYMBOL(alloc_netdev_mq);
[注] net/core/dev.c
NIC注册和除名架构
注册
1: xxx_probe/module_init 2: dev=alloc_ethdev(sizeof(driver_private_structure)) 3: alloc_netdev(sizeof(private), "eth%d", ether_setup) 4: dev=kmalloc(sizeof(net_device)+sizeof(private)+padding) 5: ether_setup(dev) 6: strcpy(dev->name, "eth%d") 7: return (dev) 8: ...... 9: netdev_boot_setup_check(dev) 10: ...... 11: register_netdev(dev) 12: register_netdevice(dev)
除名
1: xxx_remove_one/module_exit 2: unregister_netdev(dev) 3: unregister_netdevice(dev) 4: ...... 5: free_netdev(dev)
设备初始化
| 初始化程序 | 函数指针名称 |
|---|---|
| xxx_setup | change_mtu |
| set_mac_address | |
| rebuild_header | |
| hard_headser_cache | |
| header_cache_update | |
| hard_header_parse | |
| 设备驱动程序的探测函数 | open |
| stop | |
| hard_start_xmit | |
| tx_timeout | |
| watchdog_timeo | |
| get_stats | |
| get_wireless_stats | |
| set_multicast_list | |
| do_ioctl | |
| init | |
| uninit | |
| poll | |
| ethtool_ops |
| 初始化程序 | 变量名称 |
|---|---|
| xxx_setup | type |
| hard_header_len | |
| mtu | |
| addr_len | |
| tx_queue_len | |
| broadcast | |
| flags | |
| 设备驱动程序的探测函数 | base_addr |
| irq | |
| if_port | |
| priv | |
| features |
设备类型初始化: xxx_setup函数
1: const struct header_ops eth_header_ops ____cacheline_aligned = { 2: .create = eth_header, 3: .parse = eth_header_parse, 4: .rebuild = eth_rebuild_header, 5: .cache = eth_header_cache, 6: .cache_update = eth_header_cache_update, 7: }; 8: 9: /** 10: * ether_setup - setup Ethernet network device 11: * @dev: network device 12: * Fill in the fields of the device structure with Ethernet-generic values. 13: */ 14: void ether_setup(struct net_device *dev) 15: { 16: dev->header_ops = ð_header_ops; 17: dev->type = ARPHRD_ETHER; 18: dev->hard_header_len = ETH_HLEN; 19: dev->mtu = ETH_DATA_LEN; 20: dev->addr_len = ETH_ALEN; 21: dev->tx_queue_len = 1000; /* Ethernet wants good queues */ 22: dev->flags = IFF_BROADCAST|IFF_MULTICAST; 23: 24: memset(dev->broadcast, 0xFF, ETH_ALEN); 25: 26: } 27: EXPORT_SYMBOL(ether_setup);
net_device结构的组织
net_device数据结构插入一个全局列表和两张hash表中。这些不同的结构可让内核按需浏览或查询net_device数据库。
- dev_base
- dev_name_head
这是一种hash表,以设备名称为索引。
- dev_index_head
这是一张hash表,以设备ID dev->ifindex为索引。
查询
- 通过名称查询: dev_get_by_name()
1: /** 2: * dev_get_by_name - find a device by its name 3: * @net: the applicable net namespace 4: * @name: name to find 5: * 6: * Find an interface by name. This can be called from any 7: * context and does its own locking. The returned handle has 8: * the usage count incremented and the caller must use dev_put() to 9: * release it when it is no longer needed. %NULL is returned if no 10: * matching device is found. 11: */ 12: 13: struct net_device *dev_get_by_name(struct net *net, const char *name) 14: { 15: struct net_device *dev; 16: 17: rcu_read_lock(); 18: dev = dev_get_by_name_rcu(net, name); 19: if (dev) 20: dev_hold(dev); 21: rcu_read_unlock(); 22: return dev; 23: } 24: EXPORT_SYMBOL(dev_get_by_name);
- 通过索引查询:dev_get_by_index()
1: /** 2: * dev_get_by_index - find a device by its ifindex 3: * @net: the applicable net namespace 4: * @ifindex: index of device 5: * 6: * Search for an interface by index. Returns NULL if the device 7: * is not found or a pointer to the device. The device returned has 8: * had a reference added and the pointer is safe until the user calls 9: * dev_put to indicate they have finished with it. 10: */ 11: struct net_device *dev_get_by_index(struct net *net, int ifindex) 12: { 13: struct net_device *dev; 14: 15: rcu_read_lock(); 16: dev = dev_get_by_index_rcu(net, ifindex); 17: if (dev) 18: dev_hold(dev); 19: rcu_read_unlock(); 20: return dev; 21: } 22: EXPORT_SYMBOL(dev_get_by_index);
- 通过MAC查询: dev_getbyhwaddr()
1: /** 2: * dev_getbyhwaddr - find a device by its hardware address 3: * @net: the applicable net namespace 4: * @type: media type of device 5: * @ha: hardware address 6: * 7: * Search for an interface by MAC address. Returns NULL if the device 8: * is not found or a pointer to the device. The caller must hold the 9: * rtnl semaphore. The returned device has not had its ref count increased 10: * and the caller must therefore be careful about locking 11: * 12: * BUGS: 13: * If the API was consistent this would be __dev_get_by_hwaddr 14: */ 15: 16: struct net_device *dev_getbyhwaddr(struct net *net, unsigned short type, char *ha) 17: { 18: struct net_device *dev; 19: 20: ASSERT_RTNL(); 21: 22: for_each_netdev(net, dev) 23: if (dev->type == type && 24: !memcmp(dev->dev_addr, ha, dev->addr_len)) 25: return dev; 26: 27: return NULL; 28: } 29: EXPORT_SYMBOL(dev_getbyhwaddr);
- 通过设备标志查询:dev_get_by_flags()
1: /** 2: * dev_get_by_flags - find any device with given flags 3: * @net: the applicable net namespace 4: * @if_flags: IFF_* values 5: * @mask: bitmask of bits in if_flags to check 6: * 7: * Search for any interface with the given flags. Returns NULL if a device 8: * is not found or a pointer to the device. The device returned has 9: * had a reference added and the pointer is safe until the user calls 10: * dev_put to indicate they have finished with it. 11: */ 12: struct net_device *dev_get_by_flags(struct net *net, unsigned short if_flags, 13: unsigned short mask) 14: { 15: struct net_device *dev, *ret; 16: 17: ret = NULL; 18: rcu_read_lock(); 19: for_each_netdev_rcu(net, dev) { 20: if (((dev->flags ^ if_flags) & mask) == 0) { 21: dev_hold(dev); 22: ret = dev; 23: break; 24: } 25: } 26: rcu_read_unlock(); 27: return ret; 28: } 29: EXPORT_SYMBOL(dev_get_by_flags);
设备状态
- flags
用于存储各种的位域, 多数标识都代表设备的能力。
- reg_state
设备的注册状态
- state
和其队列规则有关的设备状态。
- __LINK_STATE_START
设备开启。此标识可以由netif_running检查。
- __LINK_STATE_PRESENT
设备存在。此标识可以由netif_device_present检查。
- __LINK_STATE_NOCARRIER
没有载波,此标识可以由netif_carrier_ok检查。
- __LINK_STATE_LINKWATCH_EVENT
设备的链路状态已变更
- __LINK_STATE_XOFF
- __LINK_STATE_SHED
- __LINK_STATE_RX_SHED
这三个标识由负责管理设备的入口和出口流量代码所使用。
- __LINK_STATE_START
注册状态
- NETREG_UNINITIALIZED
定义成0, 当net_device数据结构已分配且其内容都清成零时,此值代表的就是dev->reg_state中的0.
- NETREG_REGISTERING
net_device结构已经添加到所需的结构,但内核依然要在/sys文件系统中添加一个项目。
- NETREG_REGISTERED
设备已完成注册。
- NETREG_UNREGISTERING
已过时,已被删除。
- NETREG_UNREGISTERED
设备已完全被除名(包括善策/sys中的项目),但是net_device结构还没有被释放掉。
- NETREG_RELEASED
所有对net_device结构的引用都已释放。
设备的注册和除名
网络设备通过register_netdev和unregister_netdev在内核注册和除名。
设备注册状态通知
- netdev_chain 内核组件可以注册此通知链。
- netlink的RTMGRP_LINK多播群组 用户空间应用程序可以netlink的RTMGRP_LINK多播群组。
netdev_chain通知链
可以通过register_netdev_notifier和unregister_netdev_notifier分别对该链注册或除名。
所有由netdev_chain报告的NETDEV_XXX事件都在include/linux/notifier.h中。以下是我们在本章看过的
几种事件以及触发这些事件的条件:
- NETDEV_UP
- NETDEV_GOING_DOWN
- NETDEV_DOWN
送出NETDEV_UP以报告设备开启, 而且此事件是有dev_open产生。
当设备要关闭时,就会送出NETDEV_GOING_DOWN。当设备已关闭时,就会送出
NETDEV_DOWN。这些事件都是由dev_close产生的。
- NETDEV_REGISTER
设备已注册,此事件是由register_netdevice产生的。
- NETDEV_UNREGISTER
设备已经除名。此事件是由unregister_netdevice产生的。
- NETDEV_REBOOT
因为硬件失败,设备已重启。目前没有用
- NETDEV_CHANGEADDR
设备的硬件地址(或相关联的广播地址)已改变。
- NETDEV_CHANGENAME
设备已改变其名称。
- NETDEV_CHANGE
设备的状态或配置改变。此事件会用在NETDEV_CHANGEADDR和NETDEV_CHANGENAME没包括在内的所有情况下。
[注意] 向链注册时,register_netdevice_notifier也会(仅对新注册者)重新当前已注册设备所有过去的NETDEV_REGISTER和
NETDEV_UP通知信息。这样就能给新注册者有关已注册设备的状态的清晰图像。
有不少内核组件都在netdev_chain注册。其中一些如下所述:
- 路由
路由子系统使用此通知信息新增或删除和此设备相关联的所有路由项目。
- 防火墙
例如, 如果防火墙之间把来自某设备的包暂存在缓冲区内,则必须根据其策略把包丢掉,获取采取另一种动作。
- 协议代码(也就是ARP,IP等等)
例如,当你改变一个本地设备的MAC地址时,ARP表也必须据此更新。
- 虚拟设备
RTnetlink链接通知
当设备的状态或配置变更时,就会用到rtmsg_ifinfo把通知信息传递给link多播群组RTMRGP_LINK。
设备注册
设备注册不是简单的把net_device结构插入到全局列表和hash表就行了,还涉及到一些参数的初始化,产生广播通知信息已通知其他内核组件有关此次注册。
register_netdev()调用register_netdevice()。
register_netdevice函数
1: /** 2: * register_netdevice - register a network device 3: * @dev: device to register 4: * 5: * Take a completed network device structure and add it to the kernel 6: * interfaces. A %NETDEV_REGISTER message is sent to the netdev notifier 7: * chain. 0 is returned on success. A negative errno code is returned 8: * on a failure to set up the device, or if the name is a duplicate. 9: * 10: * Callers must hold the rtnl semaphore. You may want 11: * register_netdev() instead of this. 12: * 13: * BUGS: 14: * The locking appears insufficient to guarantee two parallel registers 15: * will not get the same name. 16: */ 17: 18: int register_netdevice(struct net_device *dev) 19: { 20: int ret; 21: struct net *net = dev_net(dev); 22: 23: BUG_ON(dev_boot_phase); 24: ASSERT_RTNL(); 25: 26: might_sleep(); 27: 28: /* When net_device's are persistent, this will be fatal. */ 29: BUG_ON(dev->reg_state != NETREG_UNINITIALIZED); 30: BUG_ON(!net); 31: 32: spin_lock_init(&dev->addr_list_lock); 33: netdev_set_addr_lockdep_class(dev); 34: netdev_init_queue_locks(dev); 35: 36: dev->iflink = -1; 37: 38: #ifdef CONFIG_RPS 39: if (!dev->num_rx_queues) { 40: /* 41: * Allocate a single RX queue if driver never called 42: * alloc_netdev_mq 43: */ 44: 45: dev->_rx = kzalloc(sizeof(struct netdev_rx_queue), GFP_KERNEL); 46: if (!dev->_rx) { 47: ret = -ENOMEM; 48: goto out; 49: } 50: 51: dev->_rx->first = dev->_rx; 52: atomic_set(&dev->_rx->count, 1); 53: dev->num_rx_queues = 1; 54: } 55: #endif 56: /* Init, if this function is available */ 57: if (dev->netdev_ops->ndo_init) { 58: ret = dev->netdev_ops->ndo_init(dev); 59: if (ret) { 60: if (ret > 0) 61: ret = -EIO; 62: goto out; 63: } 64: } 65: 66: ret = dev_get_valid_name(dev, dev->name, 0); 67: if (ret) 68: goto err_uninit; 69: 70: dev->ifindex = dev_new_index(net); 71: if (dev->iflink == -1) 72: dev->iflink = dev->ifindex; 73: 74: /* Fix illegal checksum combinations */ 75: if ((dev->features & NETIF_F_HW_CSUM) && 76: (dev->features & (NETIF_F_IP_CSUM|NETIF_F_IPV6_CSUM))) { 77: printk(KERN_NOTICE "%s: mixed HW and IP checksum settings.\n", 78: dev->name); 79: dev->features &= ~(NETIF_F_IP_CSUM|NETIF_F_IPV6_CSUM); 80: } 81: 82: if ((dev->features & NETIF_F_NO_CSUM) && 83: (dev->features & (NETIF_F_HW_CSUM|NETIF_F_IP_CSUM|NETIF_F_IPV6_CSUM))) { 84: printk(KERN_NOTICE "%s: mixed no checksumming and other settings.\n", 85: dev->name); 86: dev->features &= ~(NETIF_F_IP_CSUM|NETIF_F_IPV6_CSUM|NETIF_F_HW_CSUM); 87: } 88: 89: dev->features = netdev_fix_features(dev->features, dev->name); 90: 91: /* Enable software GSO if SG is supported. */ 92: if (dev->features & NETIF_F_SG) 93: dev->features |= NETIF_F_GSO; 94: 95: ret = call_netdevice_notifiers(NETDEV_POST_INIT, dev); 96: ret = notifier_to_errno(ret); 97: if (ret) 98: goto err_uninit; 99: 100: ret = netdev_register_kobject(dev); 101: if (ret) 102: goto err_uninit; 103: dev->reg_state = NETREG_REGISTERED; 104: 105: /* 106: * Default initial state at registry is that the 107: * device is present. 108: */ 109: 110: set_bit(__LINK_STATE_PRESENT, &dev->state); 111: 112: dev_init_scheduler(dev); 113: dev_hold(dev); 114: list_netdevice(dev); 115: 116: /* Notify protocols, that a new device appeared. */ 117: ret = call_netdevice_notifiers(NETDEV_REGISTER, dev); 118: ret = notifier_to_errno(ret); 119: if (ret) { 120: rollback_registered(dev); 121: dev->reg_state = NETREG_UNREGISTERED; 122: } 123: /* 124: * Prevent userspace races by waiting until the network 125: * device is fully setup before sending notifications. 126: */ 127: if (!dev->rtnl_link_ops || 128: dev->rtnl_link_state == RTNL_LINK_INITIALIZED) 129: rtmsg_ifinfo(RTM_NEWLINK, dev, ~0U); 130: 131: out: 132: return ret; 133: 134: err_uninit: 135: if (dev->netdev_ops->ndo_uninit) 136: dev->netdev_ops->ndo_uninit(dev); 137: goto out; 138: } 139: EXPORT_SYMBOL(register_netdevice);
设备除名
[注意] 每当设备之间存在依赖性而把其中一个设备除名时,就会强调其他所有(或部分)设备除名。例如虚拟设备。
unregister_netdevice函数
1: static inline void unregister_netdevice(struct net_device *dev) 2: { 3: unregister_netdevice_queue(dev, NULL); 4: } 5: 6: /** 7: * unregister_netdev - remove device from the kernel 8: * @dev: device 9: * 10: * This function shuts down a device interface and removes it 11: * from the kernel tables. 12: * 13: * This is just a wrapper for unregister_netdevice that takes 14: * the rtnl semaphore. In general you want to use this and not 15: * unregister_netdevice. 16: */ 17: void unregister_netdev(struct net_device *dev) 18: { 19: rtnl_lock(); 20: unregister_netdevice(dev); 21: rtnl_unlock(); 22: } 23: EXPORT_SYMBOL(unregister_netdev);
引用计数
net_device结构无法释放,除非对该结构的所有引用都已释放。该结构的引用计数放在dev->refcnt中,每次以dev_hold或dev_put新增或删除引用时,其值就会更新一次。
netdev_wait_allrefs函数
netdev_wait_allrefs函数由一个循环组成,只有当dev->refcnt减至零时才会结束。此函数每秒都会送出一个NETDEV_UNREGISTER通知信息,而每10秒钟都会在控制台上打印
一套警告。剩余时间都在休眠,此函数不会放弃,直到对输入net_device结构的所有引用都已释放为止。
有两种常见情况需要传递一个以上通知信息:
- bug
例如,有段代码持有net_device结构的引用,但是因为没有在netdev_chain通知链注册,或者因为没有正确处理通知信息,使其无法释放引用。
- 未决的定时器
例如, 假设当定时器到期时要执行的那个函数必须访问的数据中,包含了对net_device结构的引用。在这种情况下你必须等待直到该定时器到期,而且其处理函数有望会释放其引用。
开启和关闭网络设备
设备一旦注册就可用了,但是需要用户或用户应用程序明确开启,否则还是无法传输和接收数据流。开启设备请求有dev_open负责。
- 开启时需要做如下任务:
- 如果有定义的话,调用dev->open,并非所有设备驱动程序都有初始化函数。
- 设置dev->state总的__LINK_STATE_START标识,把设备标识为开启和运行中。
- 设置dev->flags中的IFF_UP标识,把设备标识为开启。
- 调用dev_activate初始化流量控制使用的出口规则队列,然后启用看门狗定时器。如果没有配置流量控制,就指默认的FIFO先进先出队列。
- 如果有定义的话,调用dev->open,并非所有设备驱动程序都有初始化函数。
- 关闭设备时,有如下任务要做:
- 传送NETDEV_GOING_DOWN通知信息给netdev_chain通知链,以通知感兴趣的内核组件该设备即将关闭。
- 调用dev_deactive以关闭出口规则队列,使得该设备再也无法用于传输,然后因为不再需要,停止看门狗定时器。
- 设置dev->state标识为关闭
- 如果有轮询读包动作未决,需等待。
- 如果有定义,调用dev->stop()。
- 设置dev->flags中的IFF_UP标识,把设备标识为关闭。
- 传送NETDEV_DOWN通知给netdev_chain通知链,以通知感兴趣的内核组件改设备现在已经关闭。
- 传送NETDEV_GOING_DOWN通知信息给netdev_chain通知链,以通知感兴趣的内核组件该设备即将关闭。
与电源管理之间的交互
当内核支持电源管理时,只要系统进入挂入模式或者重新继续,NIC设备驱动程序就可以接到通知。
当系统进入挂起模式时,就会执行设备驱动程序所提供的suspend函数,让驱动程序据此采取动作。
电源管理状态变更不会影响注册状态dev->reg_state,但是设备状态dev->state必须变更。
链路状态变更侦测
当NIC设备驱动程序侦测载波或信号是否存在,也许是有NIC通知,或者NIC读取配置寄存器以明确检查,
可以分别利用netif_carrier_on和netif_carrier_off通知内核。
导致链路状态变更的常见情况:
- 电缆先插入NIC,或者从NIC中拔除。
- 电缆线另一端设备电源关掉或关闭了。
从用户空间配置设备相关信息
- ifconfig和mii-tool,来自于net-tools套件。
- ethtool, 来自于ethtool套件。
- ip link, 来自于IPROUTE2套件。
通过/proc文件系统调整
/proc里没有可用于调整设备注册和除名任务的文件。
九、 中断与网络驱动程序
- 1 接收到帧时通知驱动程序
- 1.1 轮询
- 1.2 中断
- 2 中断处理程序
- 3 抢占功能
- 4 下半部函数
- 4.1 内核2.4版本以后的下半部函数: 引入软IRQ
- 5 网络代码如何使用软IRQ
- 6 softnet_data结构
接收到帧时通知驱动程序
轮询
例如,内核可以持续读取设备上的一个内存寄存器,或者当一个定时器到期时就回头检查哪个寄存器。
中断
此时,当特定事件发生时,设备驱动程序会代表内核指示设备产生硬件中断。内核将中断其他活动,然后调用一个驱动程序
所注册的处理函数,以满足设备的需要。当事件是接收到一个帧时,处理函数就会把该帧排入队列某处,然后通知内核。
中断处理程序
| 函数/宏 | 描述 |
|---|---|
| in_interrupt | 处于软硬件中断中,且抢占功能是关闭的 |
| in_softirq | 处于软件中断中 |
| in_irq | 处于硬件中断中 |
| softirq_pending | 软件中断未决 |
| local_softirq_pending | 本地软件中断未决 |
| __raise_softirq_irqoff | 设置与输入的软IRQ类型相关联的标识,将该软IRQ标记为未决 |
| raise_softirq_irqoff | 先关闭硬件中断,再调用__raise_softirq_irqoff,再恢复其原有状态 |
| raise_softirq | |
| __local_bh_enable | |
| local_bh_enable | |
| local_bh_disable | |
| local_irq_disable | |
| local_irq_enable | |
| local_irq_save | |
| local_irq_restore | |
| spin_lock_bh | |
| spin_unlock_bh |
抢占功能
- preempt_disable()
为当前任务关闭抢占功能。可以重复调用,递增一个引用计数器。
- preempt_enable()
- preempt_enable_no_resched()
开启抢占功能。preempt_enable_no_reched()只是递减一个引用计数器,使得其值为0时,可以让抢占再度开启。
下半部函数
内核2.4版本以后的下半部函数: 引入软IRQ
对并发的唯一限制就是何时,在一个CPU上每个软IRQ都只能有一个实例运行。
新式的软IRQ模型只有10种模型(include/linux/interrupt.h):
1: /* PLEASE, avoid to allocate new softirqs, if you need not _really_ high 2: frequency threaded job scheduling. For almost all the purposes 3: tasklets are more than enough. F.e. all serial device BHs et 4: al. should be converted to tasklets, not to softirqs. 5: */ 6: 7: enum 8: { 9: HI_SOFTIRQ=0, 10: TIMER_SOFTIRQ, 11: NET_TX_SOFTIRQ, 12: NET_RX_SOFTIRQ, 13: BLOCK_SOFTIRQ, 14: BLOCK_IOPOLL_SOFTIRQ, 15: TASKLET_SOFTIRQ, 16: SCHED_SOFTIRQ, 17: HRTIMER_SOFTIRQ, 18: RCU_SOFTIRQ, /* Preferable RCU should always be the last softirq */ 19: 20: NR_SOFTIRQS 21: };
网络代码如何使用软IRQ
网络子系统在net/core/dev.c中注册接收发送软中断:
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
1: /* 2: * Initialize the DEV module. At boot time this walks the device list and 3: * unhooks any devices that fail to initialise (normally hardware not 4: * present) and leaves us with a valid list of present and active devices. 5: * 6: */ 7: 8: /* 9: * This is called single threaded during boot, so no need 10: * to take the rtnl semaphore. 11: */ 12: static int __init net_dev_init(void) 13: { 14: int i, rc = -ENOMEM; 15: 16: BUG_ON(!dev_boot_phase); 17: 18: if (dev_proc_init()) 19: goto out; 20: 21: if (netdev_kobject_init()) 22: goto out; 23: 24: INIT_LIST_HEAD(&ptype_all); 25: for (i = 0; i < PTYPE_HASH_SIZE; i++) 26: INIT_LIST_HEAD(&ptype_base[i]); 27: 28: if (register_pernet_subsys(&netdev_net_ops)) 29: goto out; 30: 31: /* 32: * Initialise the packet receive queues. 33: */ 34: 35: for_each_possible_cpu(i) { 36: struct softnet_data *sd = &per_cpu(softnet_data, i); 37: 38: memset(sd, 0, sizeof(*sd)); 39: skb_queue_head_init(&sd->input_pkt_queue); 40: skb_queue_head_init(&sd->process_queue); 41: sd->completion_queue = NULL; 42: INIT_LIST_HEAD(&sd->poll_list); 43: sd->output_queue = NULL; 44: sd->output_queue_tailp = &sd->output_queue; 45: #ifdef CONFIG_RPS 46: sd->csd.func = rps_trigger_softirq; 47: sd->csd.info = sd; 48: sd->csd.flags = 0; 49: sd->cpu = i; 50: #endif 51: 52: sd->backlog.poll = process_backlog; 53: sd->backlog.weight = weight_p; 54: sd->backlog.gro_list = NULL; 55: sd->backlog.gro_count = 0; 56: } 57: 58: dev_boot_phase = 0; 59: 60: /* The loopback device is special if any other network devices 61: * is present in a network namespace the loopback device must 62: * be present. Since we now dynamically allocate and free the 63: * loopback device ensure this invariant is maintained by 64: * keeping the loopback device as the first device on the 65: * list of network devices. Ensuring the loopback devices 66: * is the first device that appears and the last network device 67: * that disappears. 68: */ 69: if (register_pernet_device(&loopback_net_ops)) 70: goto out; 71: 72: if (register_pernet_device(&default_device_ops)) 73: goto out; 74: 75: open_softirq(NET_TX_SOFTIRQ, net_tx_action); 76: open_softirq(NET_RX_SOFTIRQ, net_rx_action); 77: 78: hotcpu_notifier(dev_cpu_callback, 0); 79: dst_init(); 80: dev_mcast_init(); 81: rc = 0; 82: out: 83: return rc; 84: } 85: 86: subsys_initcall(net_dev_init);
softnet_data结构
每个CPU都有其队列,用来接收进来的帧。数据结构为:
1: /* 2: * Incoming packets are placed on per-cpu queues 3: */ 4: struct softnet_data { 5: struct Qdisc *output_queue; 6: struct Qdisc **output_queue_tailp; 7: struct list_head poll_list; 8: struct sk_buff *completion_queue; 9: struct sk_buff_head process_queue; 10: 11: /* stats */ 12: unsigned int processed; 13: unsigned int time_squeeze; 14: unsigned int cpu_collision; 15: unsigned int received_rps; 16: 17: #ifdef CONFIG_RPS 18: struct softnet_data *rps_ipi_list; 19: 20: /* Elements below can be accessed between CPUs for RPS */ 21: struct call_single_data csd ____cacheline_aligned_in_smp; 22: struct softnet_data *rps_ipi_next; 23: unsigned int cpu; 24: unsigned int input_queue_head; 25: unsigned int input_queue_tail; 26: #endif 27: unsigned dropped; 28: struct sk_buff_head input_pkt_queue; 29: struct napi_struct backlog; 30: };
十、 帧的接收
- 1 概述
- 1.1 帧接收的中断处理
- 2 设备的开启与关闭
- 3 队列
- 4 通知内核帧已接收:NAPI和netif_rx
- 4.1 NAPI简介
- 4.1.1 NAPI优点
- 4.2 NAPI所用之net_device字段
- 4.3 net_rx_action软中断处理函数和NAPI
- 4.4 新旧驱动程序接口
- 4.1 NAPI简介
概述
帧接收的中断处理
- 把帧拷贝到sk_buff数据结构。
- 对一些sk_buff参数做初始化,以便稍后由上面的网络层使用。
- 更新其他一些该设备私用函数。
设备的开启与关闭
设备的开启与关闭是由net_device->state成员进行标识的。
- 当设备打开(dev_open()),该标识置为__LINK_STATE_START.
1: set_bit(__LINK_STATE_START, &dev->state);
- 当设备关闭(dev_close()),该标识清位__LINK_STATE_START.
1: clear_bit(__LINK_STATE_START, &dev->state);
[注] net/core/dev.c
队列
帧接收时有入口队列,帧传输时有出口队列。
每个队列都有一个指针指向其相关的设备,以及一个指针指向存储输入/输出缓冲区的sk_buff数据接口。
只有少数专用设备不需要队列,例如回环设备。
通知内核帧已接收:NAPI和netif_rx
NAPI: New API(新型API)
- 通过旧函数netif_rx
多数设备依然使用。
- 通过NAPI机制
NAPI简介
NAPI优点
- 异步事件 —如帧的接收—是由中断事件指出,如果设备的入口队列为空,内核就不用去查了。
- 如果内核知道设备的入口队列中有数据存在,就没必要去处理中断事件的通知信息。用简单轮询就够了。
- 减轻了CPU负载(因为中断事件变少了)
- 设备的处理更为公平
一些设备的入口队列中若有数据,就会以相当公平的循环方式予以访问。
NAPI所用之net_device字段
为了处理驱动程序使用NAPI接口的设备,有四个新字段添加到此结构中,以供NET_RX_SOFTIRQ软IRQ使用。其它设备(非NAPI的设备)不会用到这些字段,
但是它们可共享嵌入在softnet_data结构中作为backlog_dev字段的net_device结构的字段。(backlog_dev是积压设备,主要是为了处理非NAPI的驱动程序来满足NAPI的架构的一个对象)
poll
这个虚拟函数可用于把缓冲区从设备的输入队列中退出。此队列是使用NAPI设备的私有队列,而softnet_data->input_pkt_queu供其它设备使用
poll_list
这是设备列表,其中的设备就是在入口队列中有新帧等待被处理的设备。这些设备就是所谓的处于轮询状态。此列表的头为softnet_data->poll_list。
此列表中的设备都处于中断功能关闭状态,而内核当前正在予以轮询。
由于Linux现在已经将NAPI的架构整合进了内核,并取代了老式的架构,所以当不支持NAPI的设备接受到来的新帧时,这个设备列表中的当前设备就是刚才说的积压设备——backlog_dev。
积压设备有自己的方法来模拟NAPI的机制。这个之后会说明。
quota
weight
quota(配额)是一个整数,代表的是poll虚拟函数一次可以从队列退出的缓冲区的最大数目。其值的增加以weight为单位,用于在不同设备间施加某种公平性。
配额越低, 表示潜在的延时愈低,因此让其他设备饿死的风险就愈低,另方面,低配额会增加设备间的切换量,因此整体的耗费会增加。
对配有非NAPI驱动程序的设备而言,weight的默认值为64。存储在net/core/dev.c顶端的weight_p变量。weight_p之值可通过/proc修改。
对配有NAPI程序的设备而言,默认值是由驱动程序所选。最常见的值是64,但是也有使用16和32的,其值可能过sysfs调整。
net_rx_action软中断处理函数和NAPI
如下图所示,是每次内核轮询进来的网络流量时所发生的事,在此图中可以看到poll_list列表,其内的设备处于轮询状态,也可以看到poll虚拟函数以及软中断函数net_rx_action之间的关系。

图10-1:net_rx_action函数与NAPI概述
新旧驱动程序接口
我们已经知道net_rx_action是与NET_RX_SOFTIRQ标识相关联的函数。
假设在一段低活动量期间之后有些设备开始接收帧,并在硬件中断中触发了对应于NIC的中断服务例程,并且为NET_RX_SOFTIRQ软IRQ调度以准备执行,最终这些行为触发了net_rx_action的软中断。
net_rx_action会浏览列表中处于轮询状态的设备,然后为每个设备都调用相关联的poll虚拟函数,以处理入口队列中的帧。
之前说过,该列表中的设备会按照循环方式被查阅,而且每次其poll方法启用时,能处理的帧数目都有最大值存在。如果在其时间片内无法使队列清空,就得等到下一个时间片继续下去。也就是说,
net_rx_action软中断处理函数会持续为入口队列中有数据的设备调用其设备驱动程序所提供的poll方法,真到入口队列为空。到那时就不再轮询了,而设备驱动程序就可重新开启该设备的中断事件通知功能。
值得强调的是,中断功能关闭只针对那些在poll_list中的设备,也就是只用于那些使用NAPI而不共享backlog_dev的设备。
net_rx_action会限制其执行时间,当其用完限制的执行时间或处理过一定数量的帧后,就会自行重新调度准备执行,这样是为了强制net_rx_action能与其他内核任务彼此公平运行。同是,
每个设备也公限制其poll方法每次启用时所能处理的帧数目,才能与其它设备之间彼此公平运行。当设备无法清空其入口队列时,就得等到下一次调用其poll方法的时候。
从设备驱动程序的角度看,NAPI和非NAPI之间只有两点差异。首先,NAPI驱动程序必须提供一个poll方法。其次,为帧调度所调用的函数有别:非NAPI调用netif_rx,而NAPI驱动程序调用__netif_rx_schedule。
内核提供一个名为netif_rx_schedule的包裹函数,检查以确保该设备正在运行,而且该IRQ还调度,然后才调用__netif_rx_schedule。这些检查由以netif_rx_schedule_prep进行的。

图10-2:NAPI驱动程序与非NAPI的设备
如上图所未,这两种驱动程序都会把输入设备排入轮询列表,为NET_RX_SOFTIRQ软中断调度以及准备执行,最后再由net_rx_action予以处理。即使这两种驱动程序最后都会调用__netif_rx_schedule。
NAPI设备所给予的性能会好很多。(因为NAPI中的poll函数是直接从设备中取数据,而非NAPI的是用积压设备来替代真实设备,实际上的数据依然是从内核中取走的)。