Centos8.2部署Hadoop高性能集群
目录
- 1.Hadoop概述
- 2.部署Hadoop3.3高性能集群
- 3.通过Hadoop执行计算任务
1.Hadoop概述
Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop 的框架最核心的设计就是:HDFS 和 MapReduce。HDFS 分布式文件系统为海量的数据提供了存储,则 MapReduce 为海量的数据提供了计算。
官方网站:http://hadoop.apache.org/
Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构。

官方下载:https://hadoop.apache.org/releases.html
hadoop基于java开发
Hadoop包括两大核心,分部是存储系统和分布式计算系统。
1、分布式存储
为什么数据需要存储在分布式的系统中,难道单一的计算机存储不了吗?难道现在的几个TB的硬盘装不下这些数据吗?
事实上,确实装不下。比如,很多的电信通话记录就存储在很多台服务器的很多硬盘中。那么,要处理这么多数据,必须从一台一台服务器分别读取数据和写入数据,太麻烦了!
我们希望有一种文件系统,可以管辖很多服务器用于存储数据。通过这个文件系统存储数据时,感觉不到是存储到不同的服务器上的。当读取数据时,也不会感觉到是从不同的服务器上读取。
分布式文件系统管理的是一个服务器集群。在这个集群中,数据存储在集群的节点(即集群中的服务器)中,但是该文件系统把服务器的差异屏蔽了。那么,我们就可以像使用普通的文件系统一样使用,但
是数据却分散在不同的服务器中。
命名空间(namespace):在分布式存储系统中,分散在不同节点中的数据可能属于同一个文件,为了组织众多的文件,把文件可以放到不同的文件夹中,文件夹可以一级一级的包含。我们把这种组织形式
称为命名空间(namespace)。命名空间管理着整个服务器集群中的所有文件。命名空间的职责与存储真实数据的职责是不一样的。
负责命名空间职责的节点称为主节点(master node 或 name node),负责存储真实数据职责的节点称为从节点(slave node 或 data node)。
主/从节点:主节点负责管理文件系统的文件结构,从节点负责存储真实的数据,称为主从式结构(master-slaves)。用户操作时,也应该先和主节点打交道,查询数据在哪些从节点上存储,然后再从从节点读取。在主节点,为了加快用户访问的速度,会把整个命名空间信息都放在内存中,当存储的文件越多时,那么主节点就需要越多的内存空间。
block:在从节点存储数据时,有的原始数据文件可能很大,有的可能很小,大小不一的文件不容易管理,那么可以抽象出一个独立的存储文件单位,称为块(block)。
容灾: 数据存放在集群中,可能因为网络原因或者服务器硬件原因造成访问失败,最好采用副本(replication [ˌ ˌreplɪ ɪ’ke ɪʃn])机制,把数据同时备份到多台服务器中,这样数据就安全了,数据丢失或者访问失败的概率就小了。
名词解释
(1)Hadoop:Apache 开源的分布式框架。
(2)HDSF:Hadoop 的分布式文件系统。
(3)NameNode:Hadoop HDFS 元数据主节点服务器,负责保存 DataNode 文件存储元数据
信息,这个服务器是单点的。 Namenode 记录着每个文件中各个块所在的数据节点的位置信息
(4)DataNode:Hadoop 数据节点,负责存储数据。
(5)JobTracker:Hadoop 的 Map/Reduce 调度器,负责与 TaskTracker 通信分配计算任务并
跟踪任务进度,这个服务器也是单点的。 Tracker [ˈ ˈtrækə ə®] 跟踪器
(6)TaskTracker:Hadoop 调度程序,负责 Map,Reduce 任务的启动和执行。 [tɑ:sk] 作业
任务
HDFS:分布式文件系统,负责数据的存储。
Yarn:存储之后要进行相关处理,因此需要一个资源管理和调度,(YARN),在Hadoop2.0,MapReduce作为离线处理。
计算分析工具:MapReduce、Spark、TeZ
TeZ(DAG计算)、Spark(内存计算)。
MapReduce是基于磁盘的,而Spark的计算过程是基于内存的,因此速度效率快很多。
MapReduce:做离线的批处理
Hive:数据仓库,用来做决策分析,历史记录都存在数据仓库当中,数据是多维的,可以用来做数据分析。属于Hadoop平台上的数据仓库,可以用SQL语句操作。Hive会把SqL语句转换成MapReduce作业。
Pig:流数据处理,提供了类似sql语句的查询,轻量级的编程语言。
Oozie:作业流调度系统
Zookeeper:集群管理、分布式锁
HBase:列族数据库,Hadoop上的非关系型数据库
Flume:日志相关收集,(美团)
Sqoop:完成数据导入导出(数据库ELT工具)。关系型数据库到HDFS、HBase、Hive互导
最上层:Ambari部署工具,Hadoop快速部署工具
hadoop依赖关系图
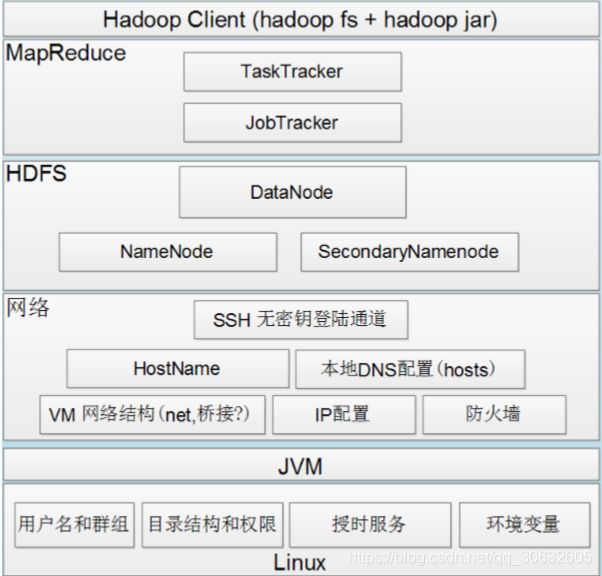
SecondaryNameNode 就是来帮助解决上述问题的,它的职责是合并 NameNode 的 edit logs 到fsimage 文件中。SecondaryNameNode 为 HDFS 中提供一个检查点。它只是 NameNode 的一个助手节点。它不是要取代掉 NameNode 也不是 NameNode 的备份。
在以上的主从式结构中,由于主节点含有整个文件系统的目录结构信息,因为非常重要。另外,由于主节点运行时会把命名空间信息都放到内存中,因此存储的文件越多,主节点的内存就需要的越多。
2、分布式计算:
对数据进行处理时,我们会把数据读取到内存中进行处理。如果我们对海量数据进行处理,比如数据大小是 100GB,我们要统计文件中一共有多少个单词。要想把数据都加载到内存中几乎是不可能的,称
为移动数据。
那么是否可以把程序代码放到存放数据的服务器上呢?因为程序代码与原始数据相比,一般很小,几乎可以忽略的,所以省下了原始数据传输的时间了。现在,数据是存放在分布式文件系统中,100GB 的
数据可能存放在很多的服务器上,那么就可以把程序代码分发到这些服务器上,在这些服务器上同时执行,也就是并行计算,也是分布式计算。这就大大缩短了程序的执行时间。我们把程序代码移动到数据节
点的机器上执行的计算方式称为移动计算。
分布式计算需要的是最终的结果,程序代码在很多机器上并行执行后会产生很多的结果,因此需要有一段代码对这些中间结果进行汇总。Hadoop 中的分布式计算一般是由两阶段完成的**。第一阶段负责读
取各数据节点中的原始数据,进行初步处理,对各个节点中的数据求单词数。然后把处理结果传输到第二个阶段,对中间结果进行汇总,产生最终结果**,求出 100GB 文件总共有多少个单词
分布式计算运行过程
在 hadoop 中,分布式计算部分称为 MapReduce。
MapReduce 是一种编程模型,用于大规模数据集(大于 1TB)的并行运算。概念"Map(映射)“和"Reduce(归约)”,和它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个 Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的 Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
主节点称为作业节点(jobtracker),
从节点称为任务节点(tasktracker)。
在任务节点中,运行第一阶段的代码称为 map 任务(map task),运行第二阶段的代码称为reduce 任务(reduce task)。
task [tɑ:sk] 任务
tracker [ˈ ˈtrækə ə®] 跟踪器
下载jdk1.8 for linux压缩包,hadoop3.3压缩包
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
https://hadoop.apache.org/releases.html
2.部署Hadoop3.3高性能集群
环境:centos8.2
主机名 IP 角色
hadoop1 192.168.3.10 NameNode
hadoop2 192.168.3.20 DataNode1
hadoop3 192.168.3.30 DataNode2
hostnamectl set-hostname hadoop1
hostnamectl set-hostname hadoop2
hostnamectl set-hostname hadoop3
vim /etc/hosts
添加
192.168.3.10 hadoop1
192.168.3.20 hadoop2
192.168.3.30 hadoop3
scp复制到另外两台机器
分别在三台主机上创建hadoop用户
useradd -u 6668 hadoop;echo hadoop:123456 |chpasswd
为了保障在其它服务器上创建的hadoop用户ID保持一致,尽量把UID调大
注:创建hadoop用户时不能使用-s /sbin/nologin,因为后续需要切换到hadoop用户
配置无密钥登录方便后期复制文件和启动服务,因为namenode启动时,会连接到datanode上启动对应的服务
生成root用户的公钥和私钥
ssh-copy-id
导入公钥到其它datanode节点认证文件
ssh-copy-id root@hadoop2
ssh-copy-id root@hadoop3
配置Hadoop环境,安装java环境JDK,三台都需要
rpm -ivh jdk-8u251-linux-x64.rpm
java -version
如果出现安装的对应版本,说明java运行环境以及安装成功
注:这里只是升级了jdk版本,因为在安装的系统中已经安装了jdk
三台机器关掉防火墙
在hadoop1上安装hadoop并配置为namenode主节点:
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.0/hadoop-3.3.0-src.tar.gz
mv hadoop-3.3.0-src.tar.gz /home/hadoop/
初始化hadoop安装环境
注:以下步骤使用hadoop用户操作
su - hadoop
tar xf hadoop-3.3.0-src.tar.gz
创建hadoop相关的工作目录
mkdir -p /home/hadoop/dfs/{name,data} /home/hadoop/tmp
配置hadoop:需要修改7个配置文件
文件位置:/home/hadoop/hadoop-3.3.0/etc/hadoop/
文件名称:hadoop-env.sh、yarn-evn.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、workers
1、配置文件hadoop-env.sh,指定hadoop的java运行环境
该文件是hadoop运行基本环境的配置,需要修改的为java虚拟机的位置
vim /home/hadoop/hadoop-3.3.0/etc/hadoop/hadoop-env.sh
54行
改 # export JAVA_HOME=
为 export JAVA_HOME=/usr/java/jdk1.8.0_251-amd64/
注:指定java运行环境变量
2.配置文件yarn框架运行环境的配置,同样需要修改java虚拟机的位置
vim /home/hadoop/hadoop-3.3.0/etc/hadoop/yarn-env.sh
不需要修改
3.配置文件core-site.xml,指定访问hadoop web界面访问路径
这个是 hadoop 的核心配置文件,这里需要配置的就这两个属性,fs.default.name 配置了
hadoop 的 HDFS 系统的命名,位置为主机的 9000 端口;
vim /home/hadoop/hadoop-3.3.0/etc/hadoop/core-site.xml
23行
fs.defaultFS</name>
hdfs://hadoop1:9000</value>
</property>
io.file.buffer.size</name>
15000</value>
</property>
hadoop.tmp.dir</name>
file:/home/hadoop/tmp</value>
Abase for other temporary directories.</description>
</property>

注:
io.file.buffer.size 的默认值 4096 。这是读写 sequence file 的 buffer size, 可减少 I/O 次数。在大型的 Hadoop cluster,建议可设定为 65536
4.配置文件hdfs-site.xml
这个是 hdfs 的配置文件,dfs.http.address 配置了 hdfs 的 http 的访问位置;
dfs.replication 配置了文件块的副本数,一般不大于从机的个数。
vim /home/hadoop/hadoop-3.3.0/etc/hadoop/hdfs-site.xml
dfs.namenode.secondary.http-address</name>
hadoop1:9001</value>
</property>
dfs.namenode.name.dir</name>
file:/home/hadoop/dfs/name</value>
</property>
dfs.datanode.data.dir</name>
file:/home/hadoop/dfs/data</value>
</property>
dfs.replication</name>
2</value>
</property>
dfs.webhdfs.enabled</name>
true</value>
</property>
</configuration>

注:
dfs.namenode.secondary.http-address
hadoop1:9001 # 通过 web 界面来查看 HDFS 状态
dfs.replication
2 #每个 Block 有 2 个备份。
5.配置文件mapred-site.xml
这个是mapreduce任务的配置
hadoop3.0
/home/hadoop/hadoop-3.3.0/sbin/mr-jobhistory-daemon.sh start historyserver
hadoop3.3
/home/hadoop/hadoop-3.3.0/bin/mapred --daemon start historyserver
修改mapred-site.xml
vim /home/hadoop/hadoop-3.3.0/etc/hadoop/mapred-site.xml
mapreduce.framework.name</name>
yarn</value>
</property>
mapreduce.jobhistory.address</name>
0.0.0.0:10020</value>
</property>
mapreduce.jobhistory.webapp.address</name>
0.0.0.0:19888</value>
</property>
</configuration>

注:由于 hadoop2.x 使用了 yarn 框架,所以要实现分布式部署,必须在
mapreduce.framework.name 属性下配置为 yarn。
同时指定:Hadoop 的历史服务器 historyserver
Hadoop 自带了一个历史服务器,可以通过历史服务器查看已经运行完的 Mapreduce 作业记录,比如用了多少个 Map、用了多少个 Reduce、作业提交时间、作业启动时间、作业完成时间等信息。默认情况下,Hadoop 历史服务器是没有启动的,我们可以通过下面的命令来启动 Hadoop 历史服务器
6.配置节点yarn-site.xml
该文件为yarn框架的配置,主要是一些任务的启动位置
vim /home/hadoop/hadoop-3.3.0/etc/hadoop/yarn-site.xml

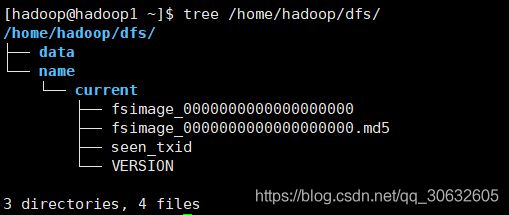
2.启动hdfs ,即启动HDFS分布式存储

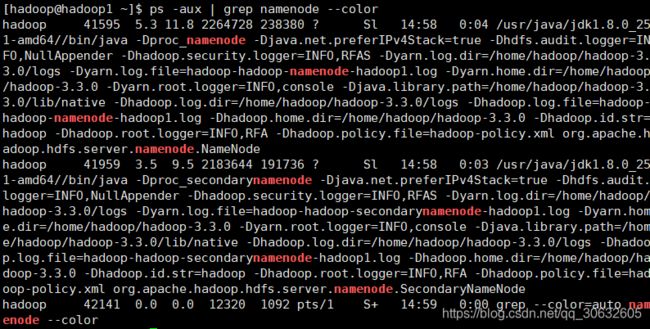
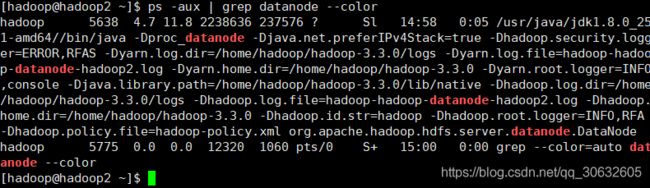
启动分布式计算

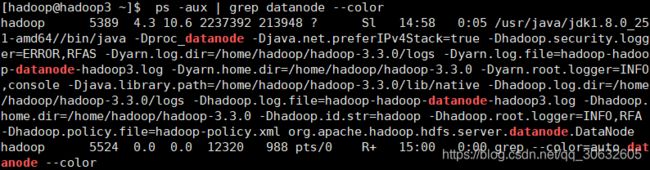
查看hadoop1上的 进程 该进程仅在hadoop1
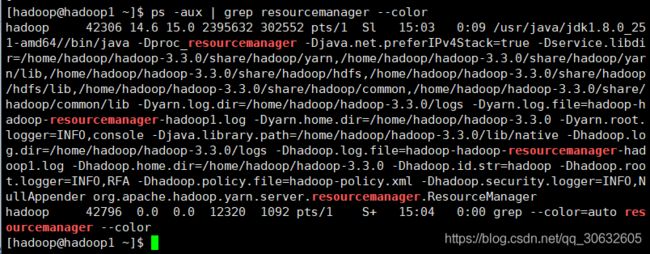
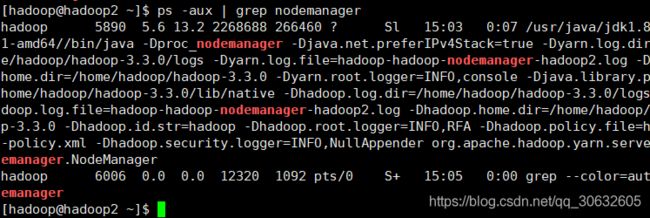
注:start-dfs.sh 和 start-yarn.sh 这两个脚本可用 start-all.sh 代替
5.启动 jobhistory 服务,查看 mapreduce 运行状态
/home/hadoop/hadoop-3.3.0/bin/hdfs --daemon start datanode
/home/hadoop/hadoop-3.3.0/bin/yarn --daemon start nodemanager
2.5集群状态监控
1 .查看HDFS分布式文件系统状态
/home/hadoop/hadoop-3.3.0/bin/hdfs dfsadmin -report
2.通过web界面来查看HDFS状态和查看文件块组成部分
命令行查看
/home/hadoop/hadoop-3.3.0/bin/hdfs fsck / -files -blocks
web界面查看
http://192.168.3.10:9870/dfshealth.html#tab-overview
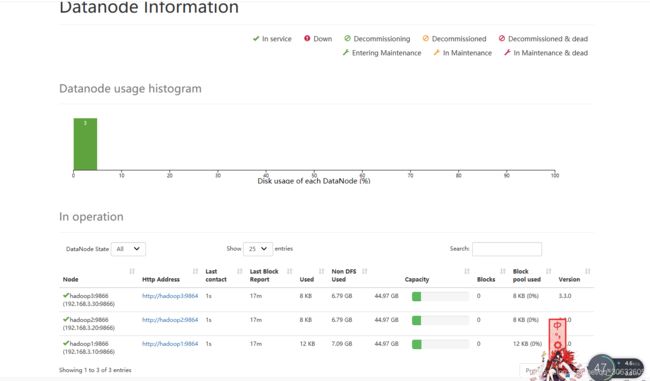
通过web查看hadoop集群状态
http://192.168.3.10:8088/
查看 JobHistory 的内容
http://192.168.3.10:19888/jobhistory
3.通过Hadoop执行计算任务
设置hadoop环境变量,方便后期调用命令
切换到root用户下:
export HADOOP_HOME=/home/hadoop/hadoop-3.3.0
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
遇到问题多看$HADOOP_HOME/logs 下面的日志
有空再补