ELK架构原理分析
一、日志简介
1.1 什么是日志
日志是带时间戳的基于时间序列的机器数据,包括IT系统信息(服务器、网络设备、操作系统、应用软件)、物联网各种传感器信息。日志反映用户行为,是事实数据,也是系统运维、故障诊断、性能分析的重要来源。对于任何系统,日志都是极其重要的组成部分。
1.2 日志处理的背景
随着大数据时代的来临,系统日志量也呈指数级增加。伴随着日志格式复杂度的增加、规模的扩大以及应用节点的增多,传统的日志分析手段耗时耗力、效率低下、无法胜任复杂事件处理等缺点逐渐暴露出来。而且传统的日志分析方法已经不能满足实时化的需求,实时化已经成为当今大数据技术的发展趋势之一。
1.3 日志处理方案的演进
业界对日志的处理方案的演进如下:
(1)日志处理v1.0
日志没有集中式处理,一般是手动到服务器上用Linux命令排查日志;
日志只做事后追查,黑客入侵后删除日志无法察觉;
使用数据库存储日志,无法胜任复杂事件处理。
(2)日志处理v2.0
使用Hadoop平台实现日志离线批处理,缺点是实时性差;
使用Storm流处理框架、Spark内存计算框架处理日志,Hadoop/Storm/Spark都是编程框架,并不是拿来即用的平台。
(3)日志处理v3.0
使用日志实时搜索引擎分析日志,作为代表的解决方案有Splunk、ELK、SILK。
主要优点有以下3个:
- 快,日志从产生到搜索分析出结果只有数秒延时;
- 大,每天处理TB日志量;
- 灵活,可搜索分析任何日志。
其中,ELK在业界最受欢迎。ELK 是 Elastic 公司出品的开源实时日志处理与分析解决方案(目前称为ELK Stack,它是 在 5.0 版本加入 Beats 套件后的新称呼),ELK 分别代表分布式搜索引擎 Elasticsearch、日志采集与解析工具 Logstash、日志可视化分析工具Kibana,具有配置方式灵活、集群可线性扩展、日志实时导入、检索性能高效、可视化分析方便等优点,已经成为业界日志处理方案的不二选择。新增的Beats是一系列采集器的总称,Beats占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,对于不同的日志源和日志格式可以使用不同的Beats。

官方地址:https://www.elastic.co/guide/cn/index.html
中文文档地址:https://elkguide.elasticsearch.cn/
二、ELK的相关组件及架构
2.1 ELK相关组件
2.1.1 Elasticsearch
Elasticsearch是实时全文搜索和分析引擎,提供搜集、分析、存储数据三大功能;是一套开放REST和JAVA API等结构提供高效搜索功能,可扩展的分布式系统。它构建于Apache Lucene搜索引擎库之上,特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等功能。
Elasticsearch之所以搜索速度快,其中核心技术就是用到倒排索引,通过对正向索引和倒排索引的对比进行说明:
正向索引:
索引的应用领域很广,包括但不限于:doc、pdf、excel、html等。
以搜索引擎对网页(html)的索引为例,正向索引是网页与关键词一一对应的数据结构。
为简单起见,我们假设有网页1和网页2:
网页1中仅包含一句话:厦门SEO顾问潇湘驭文为您提供厦门SEO培训服务。
网页2中也仅包含一句话:SEO是一门艺术。
经过搜索引擎初步分词之后,网页1和2的正向索引如下图所示:

假设使用正向索引,那么当你搜索SEO的时候,搜索引擎必须检索网页中的每一个关键词,假设一个网页中包含成千上百个关键词,可想而知,会造成大量的资源浪费。
倒排索引:
倒排索引是相对正向索引而言的,你也可以将其理解为逆向索引。它是一种关键词与网页一一对应的数据结构。如下图所示:

倒排索引可以直接参与排名。比如你搜索“SEO”,搜索引擎可以快速检索出包含“SEO”搜索词的网页1和网页2,为后续的相关度和权重计算奠定基础,从而大大加快了返回搜索结果的速度。
2.1.2 Logstash
Logstash主要是用来日志的搜集、分析、过滤日志的工具,负责采集日志,支持大量的数据获取方式。它可以从许多来源接收日志,这些来源包括 syslog、消息传递(例如 RabbitMQ)和JMX,它能够以多种方式输出数据,包括电子邮件、websockets和Elasticsearch(常用)。一般工作方式为C/S架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往Elasticsearch上去。
Logstash工作原理:
Logstash事件处理有三个阶段:inputs → filters → outputs。是一个接收,处理,转发日志的工具。支持系统日志,webserver日志,错误日志,应用日志,总之包括所有可以抛出来的日志类型。
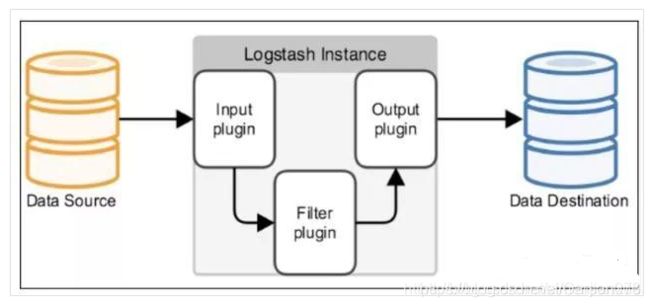
2.1.3 Kibana
Kibana是一个基于Web的图形界面,用于搜索、分析和可视化存储在 Elasticsearch指标中的日志数据。它利用Elasticsearch的REST接口来检索数据,不仅允许用户创建他们自己的数据的定制仪表板视图,还允许他们以特殊的方式查询和过滤数据。
2.1.4 Beats
Beats是一系列采集器的总称,对于不同的日志源和日志格式可以使用不同的Beats,目前Beats家族包括以下五个成员:
- Filebeat:Go语言开发的轻量级的日志采集器,可用于收集文件数据。
- Metricbeat:5.0版本之前名为Topbeat,收集系统、进程和文件系统级别的 CPU 和内存使用情况等数据。
- Packetbeat:收集网络流数据,可以实时监控系统应用和服务,可以将延迟时间、错误、响应时间、SLA性能等信息发送到Logstash或Elasticsearch。
- Winlogbeat:收集Windows事件日志数据。
- Heartbeat:监控服务器运行状态。
相比Logstash,Beats所占系统的CPU和内存几乎可以忽略不计。另外,Beats和 Logstash之间支持SSL/TLS加密传输,客户端和服务器双向认证,保证了通信安全。
Filebeat工作原理:
Filebeat由两个主要组件组成:prospectors 和 harvesters。这两个组件协同工作将文件变动发送到指定的输出中。
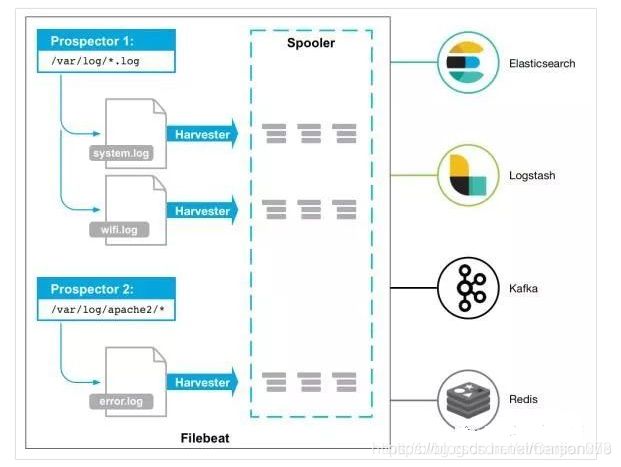
**Prospector(勘测者): **负责管理Harvester并找到所有读取源。Prospector会找到/apps/logs/*目录下的所有info.log文件,并为每个文件启动一个Harvester。Prospector会检查每个文件,看Harvester是否已经启动,是否需要启动,或者文件是否可以忽略。若Harvester关闭,只有在文件大小发生变化的时候Prospector才会执行检查。只能检测本地的文件。
Harvester(收割机): 负责读取单个文件内容。每个文件会启动一个Harvester,每个Harvester会逐行读取各个文件,并将文件内容发送到制定输出中。Harvester负责打开和关闭文件,意味在Harvester运行的时候,文件描述符处于打开状态,如果文件在收集中被重命名或者被删除,Filebeat会继续读取此文件。所以在Harvester关闭之前,磁盘不会被释放。默认情况filebeat会保持文件打开的状态,直到达到close_inactive(如果此选项开启,filebeat会在指定时间内将不再更新的文件句柄关闭,时间从harvester读取最后一行的时间开始计时。若文件句柄被关闭后,文件发生变化,则会启动一个新的harvester。关闭文件句柄的时间不取决于文件的修改时间,若此参数配置不当,则可能发生日志不实时的情况,由scan_frequency参数决定,默认10s。Harvester使用内部时间戳来记录文件最后被收集的时间。例如:设置5m,则在Harvester读取文件的最后一行之后,开始倒计时5分钟,若5分钟内文件无变化,则关闭文件句柄。默认5m)。
Filebeat如何记录文件状态:
将文件状态记录在文件中(默认在/var/lib/filebeat/registry)。此状态可以记住Harvester收集文件的偏移量。若连接不上输出设备,如ES等,filebeat会记录发送前的最后一行,并再可以连接的时候继续发送。Filebeat在运行的时候,Prospector状态会被记录在内存中。Filebeat重启的时候,利用registry记录的状态来进行重建,用来还原到重启之前的状态。每个Prospector会为每个找到的文件记录一个状态,对于每个文件,Filebeat存储唯一标识符以检测文件是否先前被收集。
Filebeat如何保证事件至少被输出一次:
Filebeat之所以能保证事件至少被传递到配置的输出一次,没有数据丢失,是因为filebeat将每个事件的传递状态保存在文件中。在未得到输出方确认时,filebeat会尝试一直发送,直到得到回应。若filebeat在传输过程中被关闭,则不会再关闭之前确认所有时事件。任何在filebeat关闭之前为确认的时间,都会在filebeat重启之后重新发送。这可确保至少发送一次,但有可能会重复。可通过设置shutdown_timeout 参数来设置关闭之前的等待事件回应的时间(默认禁用)。
2.2 ELK架构
一个完整的日志分析系统主要包括日志采集系统、日志解析系统、日志存储系统和可视化分析系统四部分。
2.2.1 典型的ELK架构
在这种架构中,只有一个 Logstash、Elasticsearch 和 Kibana 实例。Logstash 通过输入插件从多种数据源(比如日志文件、标准输入 Stdin 等)获取数据,再经过滤插件加工数据,然后经 Elasticsearch 输出插件输出到 Elasticsearch,通过 Kibana 展示。
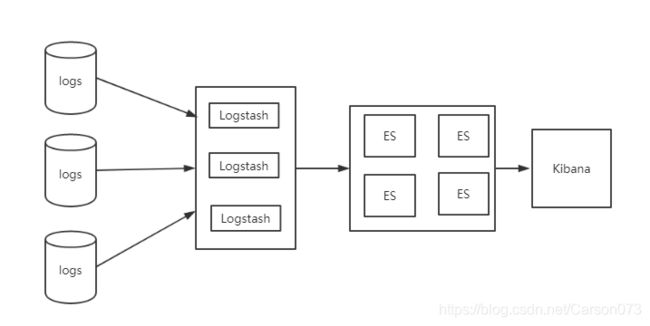
如上图所示,Logstash实例与Elasticsearch实例直接相连,本架构实现容易较简单。我们的服务器将日志写入Log,然后Logstash将Log读出,进行过滤,写入Elasticsearch。最后浏览器访问Kibana,提供一个可视化输出。
本架构主要弊端有2个:
- 在大并发情况下,日志传输峰值比较大。如果直接写入ES,ES的HTTP API处理能力有限,在日志写入频繁的情况下可能会超时、丢失,所以需要一个缓冲中间件。
- Logstash将Log读出、过滤、输出都是在应用服务器上进行的,这势必会造成服务器上占用系统资源较高,性能不佳,需要进行拆分。
2.2.2 ELK+消息队列架构
这种架构使用 Logstash 从各个数据源搜集数据,然后经消息队列输出插件输出到消息队列中。目前 Logstash 支持 Kafka、Redis、RabbitMQ 等常见消息队列。然后 Logstash 通过消息队列输入插件从队列中获取数据,分析过滤后经输出插件发送到 Elasticsearch,最后通过 Kibana 展示。如下图所示:

这种架构适合于日志规模比较庞大的情况。但由于 Logstash 日志解析节点和 Elasticsearch 的负荷比较重,可将他们配置为集群模式,以分担负荷。引入消息队列,均衡了网络传输,从而降低了网络闭塞,尤其是丢失数据的可能性,但依然存在 Logstash 占用系统资源过多的问题。
2.2.3 ELK+Beats架构
ELK架构中,由于Logstash既作为日志搜集器又作为解析器,会消耗较多的CPU和内存资源,如果服务器计算资源不够丰富,容易造成服务器性能下降甚至无法工作。为了解决了Logstash占用系统资源较高的问题,Elastic公司推出了轻量级的日志采集器Beats,在数据收集方面取代Logstash。
Beats 将搜集到的数据发送到 Logstash,经 Logstash 解析、过滤后,将其发送到 Elasticsearch 存储,并由 Kibana 呈现给用户。引入Beats后的系统架构如图2所示。
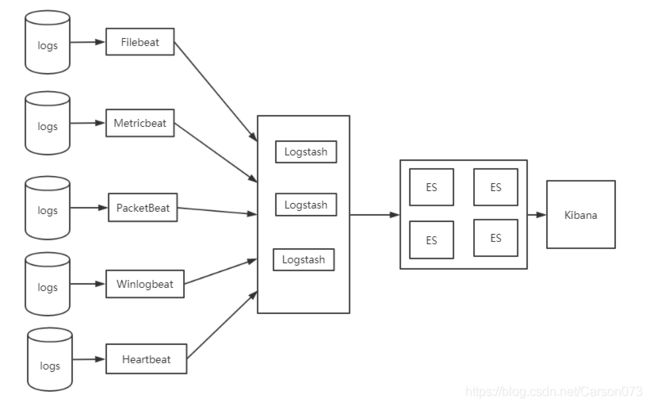
这种架构解决了 Logstash 在各服务器节点上占用系统资源高的问题。相比 Logstash,Beats 所占系统的 CPU 和内存几乎可以忽略不计。另外,Beats 和 Logstash 之间支持 SSL/TLS 加密传输,客户端和服务器双向认证,保证了通信安全。因此这种架构适合对数据安全性要求较高,同时各服务器性能比较敏感的场景。
2.2.4 ELK+Beats+消息队列架构
对于日志规模比较大的场景,还需要引入消息队列,Logstash支持常用的消息队列如Kafka、RabbitMq、Redis等,通常采用Kafka。日志采集是日志分析处理的前提与基础,对于不同类型的日志,可以根据需求选择不同的Beats。实际应用中,文件类型的日志居多,通常采用Filebeat。
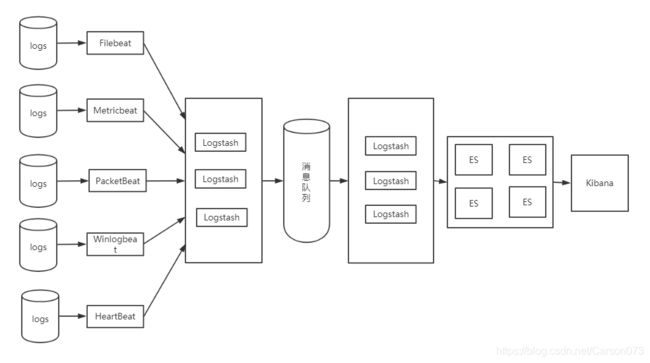
- 日志采集模块分析
当Filebeat启动时,它会启动一个或者多个prospector监控日志路径或日志文件,每个日志文件会有一个对应的harvester,harvester按行读取日志内容并转发至后台程序。Filebeat维护了一个记录文件读取信息的注册文件,记录每个harvester最后读取位置的偏移量。日志按行读取以后,转发至logstash做解析。
- 日志解析模块分析
Grok是Logstash的一个正则解析插件,它能对日志流进行解析,内置了120多种的正则表达式库,对日志解析时需要针对日志格式定义相应的正则表达式。结合Grok提供的便利,总结出按行读取文件格式日志的解析步骤:
(1)首先对日志进行分析,明确每一个字段的含义,确定日志的切分规则,也就是一条日志切分成哪几个字段,这些字段是以后做日志分析的关键,对原始日志的解读和分析是非常关键的一步。
(2)根据步骤(1)的切分原则确定提取每一个字段的正则表达式,如果Grok中的正则库满足需求直接使用即可,否则采用自定义模式,两者可以组合使用。
(3)在Grok Debugger调试工具中调试、验证解析日志的正则表达式是否正确。
1、未冷热分离的架构
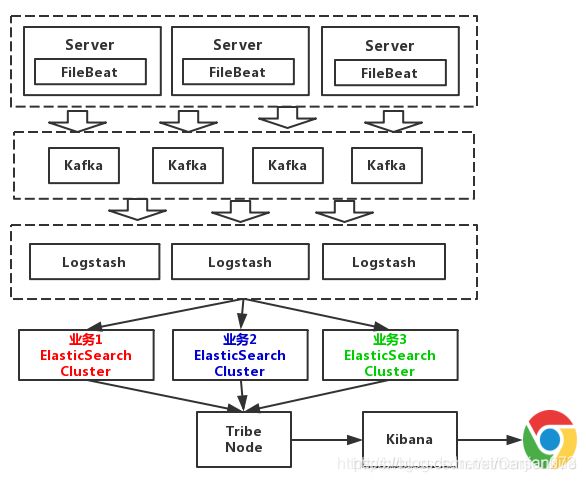
如上图所示,本架构引入了组件Filebeat,消息队列Kafka。相比于Logstash,Filebeat更轻量,占用资源更少,所占系统的 CPU 和内存几乎可以忽略不计,因其实际就只是一个二进制文件。
上述架构中,Elasticsearch根据业务分成了3个集群,他们之间相互独立。避免出现,一个业务拖垮了Elasticsearch集群,整个日志系统就一起宕机的情况。图中所示的Tribe Node组件,中文翻译为:部落结点,它是一个特殊的客户端,可连接多个集群,在所有连接的集群上执行搜索和其他操作。本处主要负责将请求路由到正确的后端ES集群上。
弊端:
本架构中没有对日志进行冷热分离。因假如需要对一个礼拜内的日志,查询的最多。以7天作为界限,区分冷热数据,可以大大的优化查询速度。
2、已冷热分离的架构
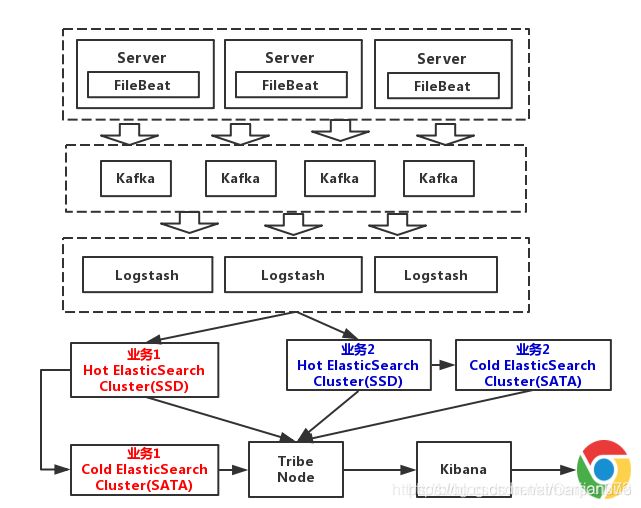
在该架构中,采用对数据进行冷热分离的策略。每个业务准备两个Elasticsearch集群,可以理解为冷热集群。7天以内的数据,存入热集群,以SSD存储索引。超过7天,就进入冷集群,以SATA存储索引。这么一改动,性能又得到提升。
注意:
敏感数据应该进行处理,不可以直接写入日志。在Java的生态中,有很多现成的日志组件,比如log4j都有提供这种日志过滤功能,需将敏感信息进行脱敏后,再记录日志。
三、遇到的典型问题
1、Filebeat 如何读取多个日志目录?
如果 Filebeat 所在 server 上运行有多个 application servers,各自有不同的日志目录,那 Filebeat 如何同时读取多个目录,这是一个非常典型的问题。
解决方案:通过配置多个 prospector 就能达到要求。在配置文件的 prospectors 下,每个"-"表示一个 prospector,每个 prospector 包含一些配置项,指明这个 prospector 所要读取的日志信息。如下所示:
prospectors:
-
paths:
- /home/WLPLog/*.log
# 其他配置项,具体参考 Elastic 官网
-
paths:
- /home/ApacheLog/*.log
# 其他配置项,具体参考 Elastic 官网
2、Filebeat 如何区分不同日志来源?
还是上题中提到的场景,Filebeat 虽然能读取不同的日志目录,但是在 Logstash 这边,或者是 Elasticsearch 这边,怎么区分不同 application server 的日志数据呢?
解决方案:Filebeat 的配置项 fields 可以实现不同日志来源的区分。用法如下:
prospectors:
-
paths:
- /home/WLPLog/*.log
fields:
log_source: WLP
-
paths:
- /home/ApacheLog/*.log
fields:
log_source: Apache
在 fields 配置项中,用户可以自定义域来标识不同的 log。比如上例中的"log_source"就是笔者自定义的。如此,从 Filebeat 输出的 log 就有一个叫做 log_source 的域表明该 log 的实际来源。
3、如何配置 Logstash 与 Elasticsearch 集群通信?
我们知道 Logstash 使用 Elasticsearch 输出插件就能把数据发送到 Elasticsearch 进行存储和搜索。Elasticsearch 插件中有个 hosts 配置项说明 Elasticsearch 信息。但是假如是一个 Elasticsearch 集群,应该怎么配置 hosts?
解决方案:最简单的做法是把集群中所有的 Elasticsearch 节点的 IP 或者是 hostname 信息都在 hosts 中配上(它支持数组)。但是如果集群比较大,或者是集群节点变动频繁的话,还需要维护这个 hosts 值,不太方便。比较推荐的做法是只配集群中某个节点的信息,可以是 client 节点,也可以是 master 节点或者是 data 节点。因为不管是哪个节点,都知道该它所在集群的信息(集群规模,各节点角色)。这样,Logstash 与任意节点通信时都会先拿到集群信息,然后再决定应该给哪个节点发送数据输出请求。
4、如何在 Kibana 显示日志数据?
解决方案:当数据存储在 Elasticsearch 端之后就可以在 Kibana 上清楚的展示了。首先在浏览器上打开 Kibana 页面。如果使用了 Nginx,就使用 Nginx 配置的 URL;否则就是http://yourhostname:5601。
创建日志索引。Logstash 发送的数据,默认使用 logstash 前缀作为数据索引。见图 1。

图 1. Kibana 创建索引页面
点击 Create,再选择 Discover 页面就能看见 Logstash 发送的数据了,如图 2 所示。
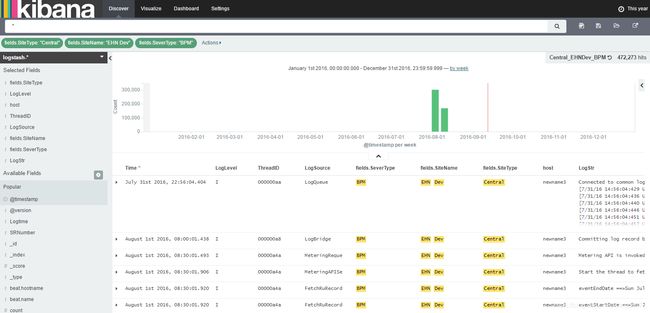
图 2. 数据展示页面
Kibana 具体的使用,比如如何创建日志 visualization,如何将 visualization 添加到 dashboard,如何在 Kibana 上搜索日志,这些可以参考官网。
参考文档:
https://blog.csdn.net/ximenjianxue/article/details/100655154
https://blog.csdn.net/zoubf/article/details/55252015
https://gitchat.csdn.net/activity/5a4b5ce9e33ddb33af128a3d?utm_source=so
https://blog.csdn.net/lively1982/article/details/50678657