人流密度检测比赛(MCNN实现)(1)——比赛及数据集介绍
笔者有幸参加:
百度深度学习7日入门-CV疫情特辑
在训练营结尾,有一场比赛,做人流密度检测,笔者初次参加比赛,有些小激动[滑稽]
好,话不多说,我们先来看看比赛
1.试题说明
近年来,应用于监控场景的行人分析视觉技术日益受到广泛关注。包括人体检测、人体属性识别、人流密度估计等技术在内的多种视觉技术,已获得在居家、安防、新零售等多个重要领域的广泛应用。其中作用于人流密集场景的人流密度估计技术(crowd density estimation)因其远高于肉眼计数的准确率和速度,已广泛应用于机场、车站、运营车辆、艺术展馆等多种场景,一方面可有效防止拥挤踩踏、超载等隐患发生,另一方面还可帮助零售商等统计客流。本试题以人流密度估计作为内容,答题者需要以对应主题作为技术核心,开发出能适用于密集、稀疏、高空、车载等多种复杂场景的通用人流密度估计算法,准确估计出输入图像中的总人数。
2.任务描述
要求参赛者给出一个算法或模型,对于给定的图片,统计图片中的总人数。给定图片数据,选手据此训练模型,为每张测试数据预测出最准确的人数。
3.数据说明
本竞赛所用训练和测试图片均来自一般监控场景,但包括多种视角(如低空、高空、鱼眼等),图中行人的相对尺寸也会有较大差异。部分训练数据参考了公开数据集(如ShanghaiTech [1], UCF-CC-50 [2], WorldExpo’10 [3],Mall [4] 等)。
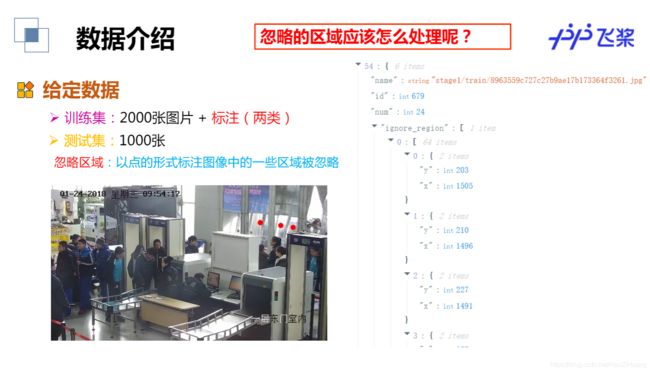
本竞赛的数据标注均在对应json文件中,每张训练图片的标注为以下两种方式之一:
(1)部分数据对图中行人提供了方框标注(boundingbox),格式为[x, y, w, h][x,y,w,h];
(2)部分图对图中行人提供了头部的打点标注,坐标格式为[x,y][x,y]。
此外部分图片还提供了忽略区(ignore_region)标注,格式为[x_0, y_0, x_1, y_1, …, x_n, y_n]组成的多边形(注意一张图片可能有多个多边形忽略区),图片在忽略区内的部分不参与训练/测试。
大家最最最关心的数据集在这里:
人流密度预测数据集(副本):https://aistudio.baidu.com/aistudio/datasetdetail/28831?
4.提交答案
考试提交,需要提交模型代码项目版本和结果文件。结果文件为CSV文件格式,可以自定义文件名称,文件内的字段需要按照指定格式写入,其中,id表示图片文件名,predicted表示图片中行人个数。
结果文件,内容应参考如下:
| id | predicted |
|---|---|
| 1 | 23 |
| 2 | 50 |
| 图片文件名 | 图片中行人个数 |
5.比赛数据分析
注: 以下分析,图片部分来自百度的教授
上面题目说了一大堆,说白了,就是给你一张图片,让你数一数里面的人数
1.我们先来看看数据图片,有这样两种的照片,正常照片和畸变后的照片[可能我说的不专业],此为难点一

2.而数据集的标注也有两种,一种是边界框标注(ground truth),另一种是坐标标注
如何有效利用数据标注,此为难点二


3.甚至给定了忽略区域,在给定区域外的人数不计算在内,如何处理忽略区域,此为难点三
4.每张图片的分辨率不同,此为难点四

5.图片数据来源于不同的场景,此为难点五
6.人群之间存在遮挡

7.目标大小存在差异

8.存在人流密集的图像
6.比赛方法分析
(1).可将该问题直接视为N分类问题,损失函数一般选择交叉熵损失函数(可行性不大,无法解决人流密集的图像)

(2).可将该问题直接视为回归问题,损失函数一般选择均方误差损失函数(笔者觉得可行性不行,但是YOLO不都是将检测问题视为回归吗,大家可以试试,没准儿效果超级好!)

(3).直接看做目标检测任务(从信息论的角度,部分计算资源被用作处理没用的信息,有种杀鸡焉用宰牛刀的感觉,嘿嘿)

(4).用密度图回归来做(笔者墙裂推荐)
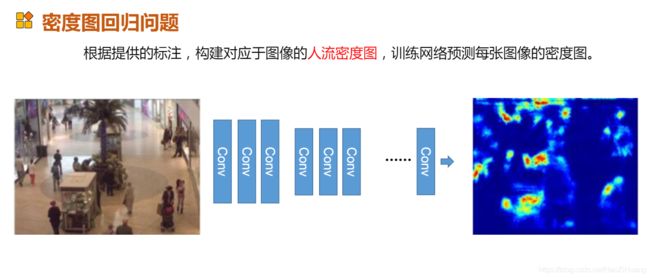
下一篇,我们来说说如何用密度图回归来做